 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQLSpace: A Representation Space for Text-to-SQL to Discover and Mitigate Robustness Gaps
Oct 31, 2025We introduce SQLSpace, a human-interpretable, generalizable, compact representation for text-to-SQL examples derived with minimal human intervention. We demonstrate the utility of these representations in evaluation with three use cases: (i) closely comparing and contrasting the composition of popular text-to-SQL benchmarks to identify unique dimensions of examples they evaluate, (ii) understanding model performance at a granular level beyond overall accuracy scores, and (iii) improving model performance through targeted query rewriting based on learned correctness estimation. We show that SQLSpace enables analysis that would be difficult with raw examples alone: it reveals compositional differences between benchmarks, exposes performance patterns obscured by accuracy alone, and supports modeling of query success.
SOHES: Self-supervised Open-world Hierarchical Entity Segmentation
Apr 18, 2024Open-world entity segmentation, as an emerging computer vision task, aims at segmenting entities in images without being restricted by pre-defined classes, offering impressive generalization capabilities on unseen images and concepts. Despite its promise, existing entity segmentation methods like Segment Anything Model (SAM) rely heavily on costly expert annotators. This work presents Self-supervised Open-world Hierarchical Entity Segmentation (SOHES), a novel approach that eliminates the need for human annotations. SOHES operates in three phases: self-exploration, self-instruction, and self-correction. Given a pre-trained self-supervised representation, we produce abundant high-quality pseudo-labels through visual feature clustering. Then, we train a segmentation model on the pseudo-labels, and rectify the noises in pseudo-labels via a teacher-student mutual-learning procedure. Beyond segmenting entities, SOHES also captures their constituent parts, providing a hierarchical understanding of visual entities. Using raw images as the sole training data, our method achieves unprecedented performance in self-supervised open-world segmentation, marking a significant milestone towards high-quality open-world entity segmentation in the absence of human-annotated masks. Project page: https://SOHES.github.io.
Standardizing the Measurement of Text Diversity: A Tool and a Comparative Analysis of Scores
Mar 01, 2024



The diversity across outputs generated by large language models shapes the perception of their quality and utility. Prompt leaks, templated answer structure, and canned responses across different interactions are readily noticed by people, but there is no standard score to measure this aspect of model behavior. In this work we empirically investigate diversity scores on English texts. We find that computationally efficient compression algorithms capture information similar to what is measured by slow to compute $n$-gram overlap homogeneity scores. Further, a combination of measures -- compression ratios, self-repetition of long $n$-grams and Self-BLEU and BERTScore -- are sufficient to report, as they have low mutual correlation with each other. The applicability of scores extends beyond analysis of generative models; for example, we highlight applications on instruction-tuning datasets and human-produced texts. We release a diversity score package to facilitate research and invite consistency across reports.
How Much Annotation is Needed to Compare Summarization Models?
Feb 28, 2024



Modern instruction-tuned models have become highly capable in text generation tasks such as summarization, and are expected to be released at a steady pace. In practice one may now wish to choose confidently, but with minimal effort, the best performing summarization model when applied to a new domain or purpose. In this work, we empirically investigate the test sample size necessary to select a preferred model in the context of news summarization. Empirical results reveal that comparative evaluation converges quickly for both automatic and human evaluation, with clear preferences for a system emerging from under 100 examples. The human preference data allows us to quantify how well automatic scores can reproduce preference rankings across a variety of downstream summarization tasks. We find that, while automatic metrics are stable at smaller sample sizes, only some automatic metrics are able to moderately predict model win rates according to human preference.
Improving a Named Entity Recognizer Trained on Noisy Data with a Few Clean Instances
Oct 25, 2023



To achieve state-of-the-art performance, one still needs to train NER models on large-scale, high-quality annotated data, an asset that is both costly and time-intensive to accumulate. In contrast, real-world applications often resort to massive low-quality labeled data through non-expert annotators via crowdsourcing and external knowledge bases via distant supervision as a cost-effective alternative. However, these annotation methods result in noisy labels, which in turn lead to a notable decline in performance. Hence, we propose to denoise the noisy NER data with guidance from a small set of clean instances. Along with the main NER model we train a discriminator model and use its outputs to recalibrate the sample weights. The discriminator is capable of detecting both span and category errors with different discriminative prompts. Results on public crowdsourcing and distant supervision datasets show that the proposed method can consistently improve performance with a small guidance set.
AutoDAN: Automatic and Interpretable Adversarial Attacks on Large Language Models
Oct 23, 2023



Safety alignment of Large Language Models (LLMs) can be compromised with manual jailbreak attacks and (automatic) adversarial attacks. Recent work suggests that patching LLMs against these attacks is possible: manual jailbreak attacks are human-readable but often limited and public, making them easy to block; adversarial attacks generate gibberish prompts that can be detected using perplexity-based filters. In this paper, we show that these solutions may be too optimistic. We propose an interpretable adversarial attack, \texttt{AutoDAN}, that combines the strengths of both types of attacks. It automatically generates attack prompts that bypass perplexity-based filters while maintaining a high attack success rate like manual jailbreak attacks. These prompts are interpretable and diverse, exhibiting strategies commonly used in manual jailbreak attacks, and transfer better than their non-readable counterparts when using limited training data or a single proxy model. We also customize \texttt{AutoDAN}'s objective to leak system prompts, another jailbreak application not addressed in the adversarial attack literature. %, demonstrating the versatility of the approach. We can also customize the objective of \texttt{AutoDAN} to leak system prompts, beyond the ability to elicit harmful content from the model, demonstrating the versatility of the approach. Our work provides a new way to red-team LLMs and to understand the mechanism of jailbreak attacks.
PDFTriage: Question Answering over Long, Structured Documents
Sep 16, 2023



Large Language Models (LLMs) have issues with document question answering (QA) in situations where the document is unable to fit in the small context length of an LLM. To overcome this issue, most existing works focus on retrieving the relevant context from the document, representing them as plain text. However, documents such as PDFs, web pages, and presentations are naturally structured with different pages, tables, sections, and so on. Representing such structured documents as plain text is incongruous with the user's mental model of these documents with rich structure. When a system has to query the document for context, this incongruity is brought to the fore, and seemingly trivial questions can trip up the QA system. To bridge this fundamental gap in handling structured documents, we propose an approach called PDFTriage that enables models to retrieve the context based on either structure or content. Our experiments demonstrate the effectiveness of the proposed PDFTriage-augmented models across several classes of questions where existing retrieval-augmented LLMs fail. To facilitate further research on this fundamental problem, we release our benchmark dataset consisting of 900+ human-generated questions over 80 structured documents from 10 different categories of question types for document QA.
Summarization from Leaderboards to Practice: Choosing A Representation Backbone and Ensuring Robustness
Jun 18, 2023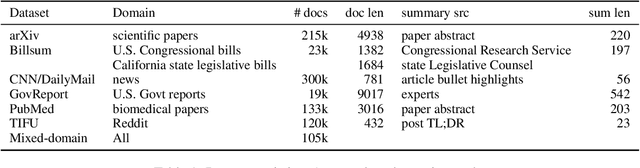

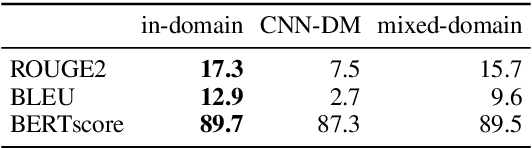
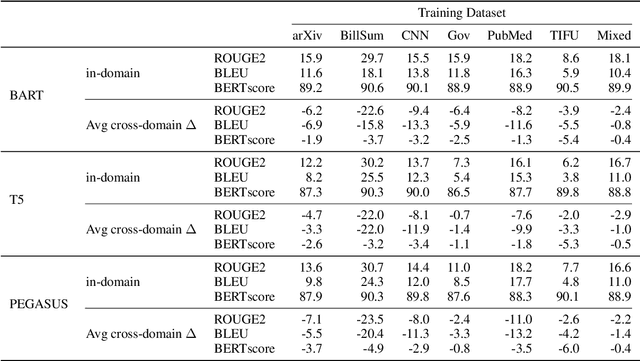
Academic literature does not give much guidance on how to build the best possible customer-facing summarization system from existing research components. Here we present analyses to inform the selection of a system backbone from popular models; we find that in both automatic and human evaluation, BART performs better than PEGASUS and T5. We also find that when applied cross-domain, summarizers exhibit considerably worse performance. At the same time, a system fine-tuned on heterogeneous domains performs well on all domains and will be most suitable for a broad-domain summarizer. Our work highlights the need for heterogeneous domain summarization benchmarks. We find considerable variation in system output that can be captured only with human evaluation and are thus unlikely to be reflected in standard leaderboards with only automatic evaluation.
Few-Shot Dialogue Summarization via Skeleton-Assisted Prompt Transfer
May 20, 2023
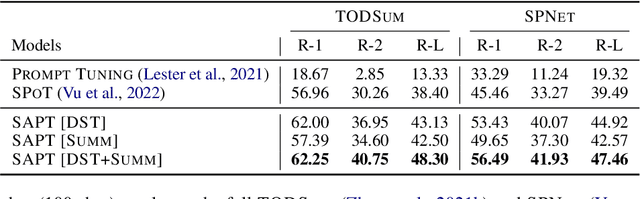
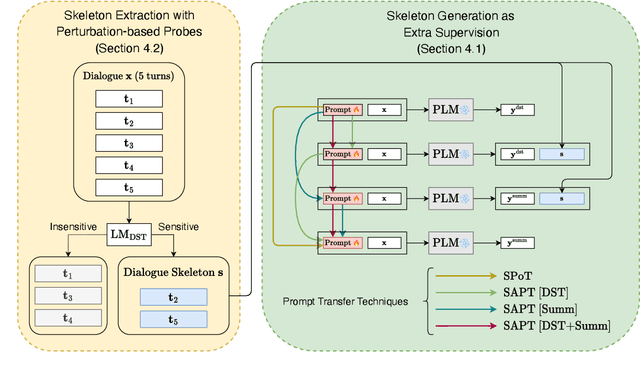
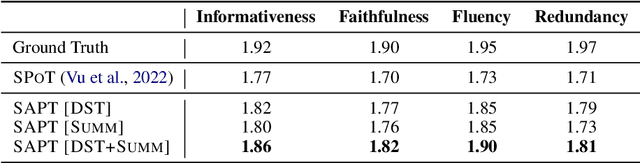
In real-world scenarios, labeled samples for dialogue summarization are usually limited (i.e., few-shot) due to high annotation costs for high-quality dialogue summaries. To efficiently learn from few-shot samples, previous works have utilized massive annotated data from other downstream tasks and then performed prompt transfer in prompt tuning so as to enable cross-task knowledge transfer. However, existing general-purpose prompt transfer techniques lack consideration for dialogue-specific information. In this paper, we focus on improving the prompt transfer from dialogue state tracking to dialogue summarization and propose Skeleton-Assisted Prompt Transfer (SAPT), which leverages skeleton generation as extra supervision that functions as a medium connecting the distinct source and target task and resulting in the model's better consumption of dialogue state information. To automatically extract dialogue skeletons as supervised training data for skeleton generation, we design a novel approach with perturbation-based probes requiring neither annotation effort nor domain knowledge. Training the model on such skeletons can also help preserve model capability during prompt transfer. Our method significantly outperforms existing baselines. In-depth analyses demonstrate the effectiveness of our method in facilitating cross-task knowledge transfer in few-shot dialogue summarization.
Learning the Visualness of Text Using Large Vision-Language Models
May 11, 2023Visual text evokes an image in a person's mind, while non-visual text fails to do so. A method to automatically detect visualness in text will unlock the ability to augment text with relevant images, as neural text-to-image generation and retrieval models operate on the implicit assumption that the input text is visual in nature. We curate a dataset of 3,620 English sentences and their visualness scores provided by multiple human annotators. Additionally, we use documents that contain text and visual assets to create a distantly supervised corpus of document text and associated images. We also propose a fine-tuning strategy that adapts large vision-language models like CLIP that assume a one-to-one correspondence between text and image to the task of scoring text visualness from text input alone. Our strategy involves modifying the model's contrastive learning objective to map text identified as non-visual to a common NULL image while matching visual text to their corresponding images in the document. We evaluate the proposed approach on its ability to (i) classify visual and non-visual text accurately, and (ii) attend over words that are identified as visual in psycholinguistic studies. Empirical evaluation indicates that our approach performs better than several heuristics and baseline models for the proposed task. Furthermore, to highlight the importance of modeling the visualness of text, we conduct qualitative analyses of text-to-image generation systems like DALL-E.