 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason in LLMs by Expectation Maximization
Dec 23, 2025

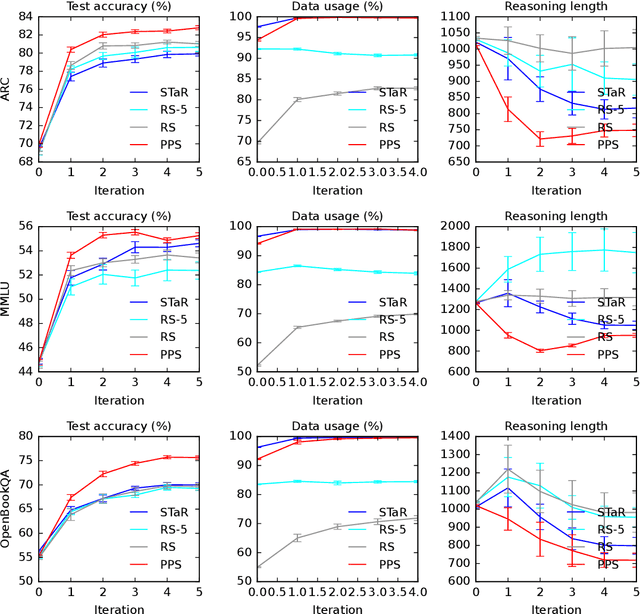
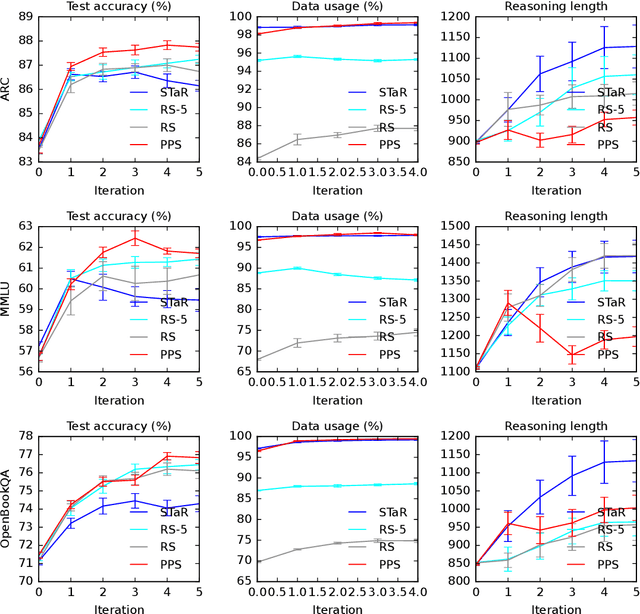
Large language models (LLMs) solve reasoning problems by first generating a rationale and then answering. We formalize reasoning as a latent variable model and derive an expectation-maximization (EM) objective for learning to reason. This view connects EM and modern reward-based optimization, and shows that the main challenge lies in designing a sampling distribution that generates rationales that justify correct answers. We instantiate and compare several sampling schemes: rejection sampling with a budget, self-taught reasoner (STaR), and prompt posterior sampling (PPS), which only keeps the rationalization stage of STaR. Our experiments on the ARC, MMLU, and OpenBookQA datasets with the Llama and Qwen models show that the sampling scheme can significantly affect the accuracy of learned reasoning models. Despite its simplicity, we observe that PPS outperforms the other sampling schemes.
SweeperBot: Making 3D Browsing Accessible through View Analysis and Visual Question Answering
Nov 19, 2025Accessing 3D models remains challenging for Screen Reader (SR) users. While some existing 3D viewers allow creators to provide alternative text, they often lack sufficient detail about the 3D models. Grounded on a formative study, this paper introduces SweeperBot, a system that enables SR users to leverage visual question answering to explore and compare 3D models. SweeperBot answers SR users' visual questions by combining an optimal view selection technique with the strength of generative- and recognition-based foundation models. An expert review with 10 Blind and Low-Vision (BLV) users with SR experience demonstrated the feasibility of using SweeperBot to assist BLV users in exploring and comparing 3D models. The quality of the descriptions generated by SweeperBot was validated by a second survey study with 30 sighted participants.
Imprinto: Enhancing Infrared Inkjet Watermarking for Human and Machine Perception
Feb 24, 2025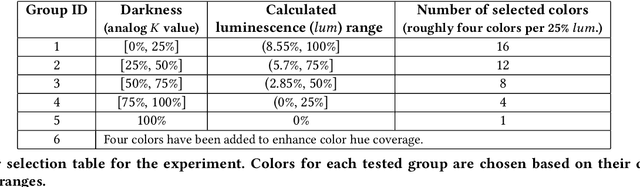
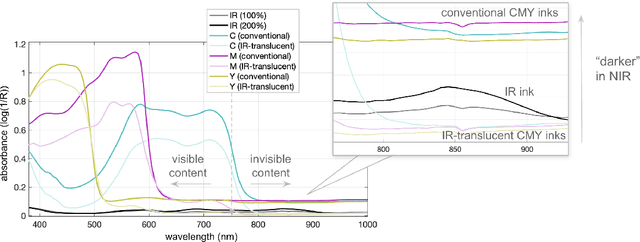


Hybrid paper interfaces leverage augmented reality to combine the desired tangibility of paper documents with the affordances of interactive digital media. Typically, virtual content can be embedded through direct links (e.g., QR codes); however, this impacts the aesthetics of the paper print and limits the available visual content space. To address this problem, we present Imprinto, an infrared inkjet watermarking technique that allows for invisible content embeddings only by using off-the-shelf IR inks and a camera. Imprinto was established through a psychophysical experiment, studying how much IR ink can be used while remaining invisible to users regardless of background color. We demonstrate that we can detect invisible IR content through our machine learning pipeline, and we developed an authoring tool that optimizes the amount of IR ink on the color regions of an input document for machine and human detectability. Finally, we demonstrate several applications, including augmenting paper documents and objects.
Optimizing Data Delivery: Insights from User Preferences on Visuals, Tables, and Text
Nov 12, 2024

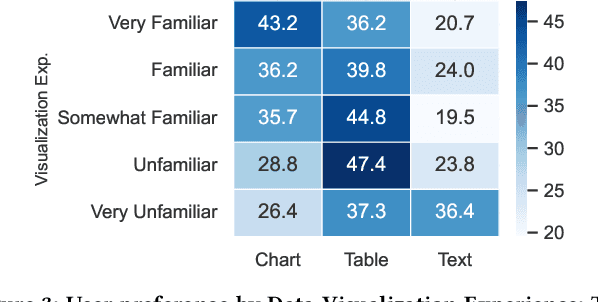

In this work, we research user preferences to see a chart, table, or text given a question asked by the user. This enables us to understand when it is best to show a chart, table, or text to the user for the specific question. For this, we conduct a user study where users are shown a question and asked what they would prefer to see and used the data to establish that a user's personal traits does influence the data outputs that they prefer. Understanding how user characteristics impact a user's preferences is critical to creating data tools with a better user experience. Additionally, we investigate to what degree an LLM can be used to replicate a user's preference with and without user preference data. Overall, these findings have significant implications pertaining to the development of data tools and the replication of human preferences using LLMs. Furthermore, this work demonstrates the potential use of LLMs to replicate user preference data which has major implications for future user modeling and personalization research.
Survey of User Interface Design and Interaction Techniques in Generative AI Applications
Oct 28, 2024

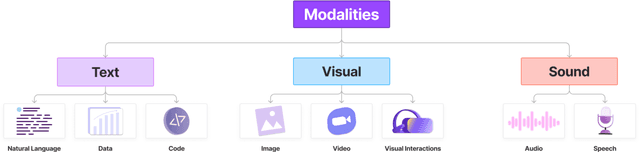
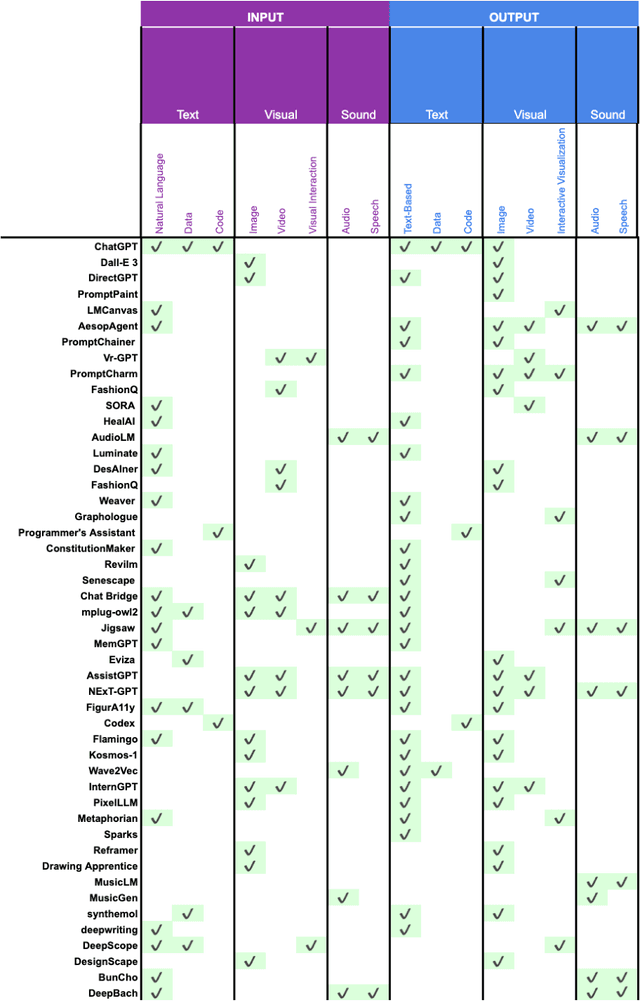
The applications of generative AI have become extremely impressive, and the interplay between users and AI is even more so. Current human-AI interaction literature has taken a broad look at how humans interact with generative AI, but it lacks specificity regarding the user interface designs and patterns used to create these applications. Therefore, we present a survey that comprehensively presents taxonomies of how a human interacts with AI and the user interaction patterns designed to meet the needs of a variety of relevant use cases. We focus primarily on user-guided interactions, surveying interactions that are initiated by the user and do not include any implicit signals given by the user. With this survey, we aim to create a compendium of different user-interaction patterns that can be used as a reference for designers and developers alike. In doing so, we also strive to lower the entry barrier for those attempting to learn more about the design of generative AI applications.
Augmenting Textual Generation via Topology Aware Retrieval
May 27, 2024



Despite the impressive advancements of Large Language Models (LLMs) in generating text, they are often limited by the knowledge contained in the input and prone to producing inaccurate or hallucinated content. To tackle these issues, Retrieval-augmented Generation (RAG) is employed as an effective strategy to enhance the available knowledge base and anchor the responses in reality by pulling additional texts from external databases. In real-world applications, texts are often linked through entities within a graph, such as citations in academic papers or comments in social networks. This paper exploits these topological relationships to guide the retrieval process in RAG. Specifically, we explore two kinds of topological connections: proximity-based, focusing on closely connected nodes, and role-based, which looks at nodes sharing similar subgraph structures. Our empirical research confirms their relevance to text relationships, leading us to develop a Topology-aware Retrieval-augmented Generation framework. This framework includes a retrieval module that selects texts based on their topological relationships and an aggregation module that integrates these texts into prompts to stimulate LLMs for text generation. We have curated established text-attributed networks and conducted comprehensive experiments to validate the effectiveness of this framework, demonstrating its potential to enhance RAG with topological awareness.
PDFTriage: Question Answering over Long, Structured Documents
Sep 16, 2023



Large Language Models (LLMs) have issues with document question answering (QA) in situations where the document is unable to fit in the small context length of an LLM. To overcome this issue, most existing works focus on retrieving the relevant context from the document, representing them as plain text. However, documents such as PDFs, web pages, and presentations are naturally structured with different pages, tables, sections, and so on. Representing such structured documents as plain text is incongruous with the user's mental model of these documents with rich structure. When a system has to query the document for context, this incongruity is brought to the fore, and seemingly trivial questions can trip up the QA system. To bridge this fundamental gap in handling structured documents, we propose an approach called PDFTriage that enables models to retrieve the context based on either structure or content. Our experiments demonstrate the effectiveness of the proposed PDFTriage-augmented models across several classes of questions where existing retrieval-augmented LLMs fail. To facilitate further research on this fundamental problem, we release our benchmark dataset consisting of 900+ human-generated questions over 80 structured documents from 10 different categories of question types for document QA.
Knowledge Graph Prompting for Multi-Document Question Answering
Aug 22, 2023



The 'pre-train, prompt, predict' paradigm of large language models (LLMs) has achieved remarkable success in open-domain question answering (OD-QA). However, few works explore this paradigm in the scenario of multi-document question answering (MD-QA), a task demanding a thorough understanding of the logical associations among the contents and structures of different documents. To fill this crucial gap, we propose a Knowledge Graph Prompting (KGP) method to formulate the right context in prompting LLMs for MD-QA, which consists of a graph construction module and a graph traversal module. For graph construction, we create a knowledge graph (KG) over multiple documents with nodes symbolizing passages or document structures (e.g., pages/tables), and edges denoting the semantic/lexical similarity between passages or intra-document structural relations. For graph traversal, we design an LM-guided graph traverser that navigates across nodes and gathers supporting passages assisting LLMs in MD-QA. The constructed graph serves as the global ruler that regulates the transitional space among passages and reduces retrieval latency. Concurrently, the LM-guided traverser acts as a local navigator that gathers pertinent context to progressively approach the question and guarantee retrieval quality. Extensive experiments underscore the efficacy of KGP for MD-QA, signifying the potential of leveraging graphs in enhancing the prompt design for LLMs. Our code is at https://github.com/YuWVandy/KG-LLM-MDQA.