 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoiré Video Authentication: A Physical Signature Against AI Video Generation
Apr 02, 2026Recent advances in video generation have made AI-synthesized content increasingly difficult to distinguish from real footage. We propose a physics-based authentication signature that real cameras produce naturally, but that generative models cannot faithfully reproduce. Our approach exploits the Moiré effect: the interference fringes formed when a camera views a compact two-layer grating structure. We derive the Moiré motion invariant, showing that fringe phase and grating image displacement are linearly coupled by optical geometry, independent of viewing distance and grating structure. A verifier extracts both signals from video and tests their correlation. We validate the invariant on both real-captured and AI-generated videos from multiple state-of-the-art generators, and find that real and AI-generated videos produce significantly different correlation signatures, suggesting a robust means of differentiating them. Our work demonstrates that deterministic optical phenomena can serve as physically grounded, verifiable signatures against AI-generated video.
Skill Discovery for Software Scripting Automation via Offline Simulations with LLMs
Apr 29, 2025Scripting interfaces enable users to automate tasks and customize software workflows, but creating scripts traditionally requires programming expertise and familiarity with specific APIs, posing barriers for many users. While Large Language Models (LLMs) can generate code from natural language queries, runtime code generation is severely limited due to unverified code, security risks, longer response times, and higher computational costs. To bridge the gap, we propose an offline simulation framework to curate a software-specific skillset, a collection of verified scripts, by exploiting LLMs and publicly available scripting guides. Our framework comprises two components: (1) task creation, using top-down functionality guidance and bottom-up API synergy exploration to generate helpful tasks; and (2) skill generation with trials, refining and validating scripts based on execution feedback. To efficiently navigate the extensive API landscape, we introduce a Graph Neural Network (GNN)-based link prediction model to capture API synergy, enabling the generation of skills involving underutilized APIs and expanding the skillset's diversity. Experiments with Adobe Illustrator demonstrate that our framework significantly improves automation success rates, reduces response time, and saves runtime token costs compared to traditional runtime code generation. This is the first attempt to use software scripting interfaces as a testbed for LLM-based systems, highlighting the advantages of leveraging execution feedback in a controlled environment and offering valuable insights into aligning AI capabilities with user needs in specialized software domains.
Streaming, Fast and Slow: Cognitive Load-Aware Streaming for Efficient LLM Serving
Apr 25, 2025Generative conversational interfaces powered by large language models (LLMs) typically stream output token-by-token at a rate determined by computational budget, often neglecting actual human reading speeds and the cognitive load associated with the content. This mismatch frequently leads to inefficient use of computational resources. For example, in cloud-based services, streaming content faster than users can read appears unnecessary, resulting in wasted computational resources and potential delays for other users, particularly during peak usage periods. To address this issue, we propose an adaptive streaming method that dynamically adjusts the pacing of LLM streaming output in real-time based on inferred cognitive load. Our approach estimates the cognitive load associated with streaming content and strategically slows down the stream during complex or information-rich segments, thereby freeing computational resources for other users. Our statistical analysis of computational savings, combined with crowdsourced user studies, provides insights into the trade-offs between service efficiency and user satisfaction, demonstrating that our method can significantly reduce computational consumption up to 16.8\%. This context-aware computational resource management strategy presents a practical framework for enhancing system efficiency in cloud-based conversational AI interfaces without compromising user experience.
Imprinto: Enhancing Infrared Inkjet Watermarking for Human and Machine Perception
Feb 24, 2025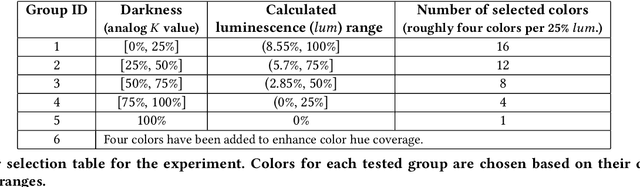
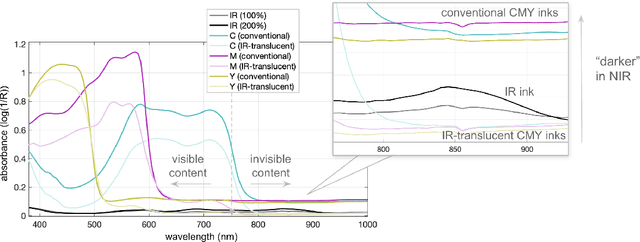


Hybrid paper interfaces leverage augmented reality to combine the desired tangibility of paper documents with the affordances of interactive digital media. Typically, virtual content can be embedded through direct links (e.g., QR codes); however, this impacts the aesthetics of the paper print and limits the available visual content space. To address this problem, we present Imprinto, an infrared inkjet watermarking technique that allows for invisible content embeddings only by using off-the-shelf IR inks and a camera. Imprinto was established through a psychophysical experiment, studying how much IR ink can be used while remaining invisible to users regardless of background color. We demonstrate that we can detect invisible IR content through our machine learning pipeline, and we developed an authoring tool that optimizes the amount of IR ink on the color regions of an input document for machine and human detectability. Finally, we demonstrate several applications, including augmenting paper documents and objects.
LLMs May Not Be Human-Level Players, But They Can Be Testers: Measuring Game Difficulty with LLM Agents
Oct 01, 2024Recent advances in Large Language Models (LLMs) have demonstrated their potential as autonomous agents across various tasks. One emerging application is the use of LLMs in playing games. In this work, we explore a practical problem for the gaming industry: Can LLMs be used to measure game difficulty? We propose a general game-testing framework using LLM agents and test it on two widely played strategy games: Wordle and Slay the Spire. Our results reveal an interesting finding: although LLMs may not perform as well as the average human player, their performance, when guided by simple, generic prompting techniques, shows a statistically significant and strong correlation with difficulty indicated by human players. This suggests that LLMs could serve as effective agents for measuring game difficulty during the development process. Based on our experiments, we also outline general principles and guidelines for incorporating LLMs into the game testing process.
A Hypergraph Neural Network Framework for Learning Hyperedge-Dependent Node Embeddings
Dec 28, 2022In this work, we introduce a hypergraph representation learning framework called Hypergraph Neural Networks (HNN) that jointly learns hyperedge embeddings along with a set of hyperedge-dependent embeddings for each node in the hypergraph. HNN derives multiple embeddings per node in the hypergraph where each embedding for a node is dependent on a specific hyperedge of that node. Notably, HNN is accurate, data-efficient, flexible with many interchangeable components, and useful for a wide range of hypergraph learning tasks. We evaluate the effectiveness of the HNN framework for hyperedge prediction and hypergraph node classification. We find that HNN achieves an overall mean gain of 7.72% and 11.37% across all baseline models and graphs for hyperedge prediction and hypergraph node classification, respectively.
Can one hear the shape of a neural network?: Snooping the GPU via Magnetic Side Channel
Sep 15, 2021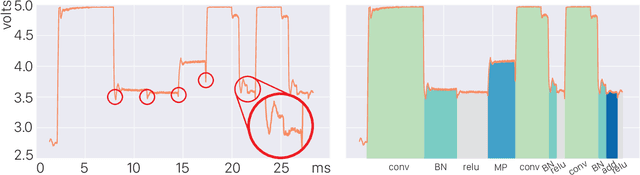
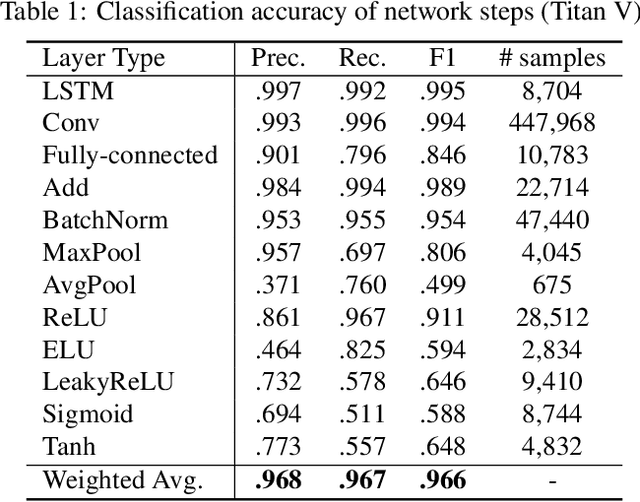

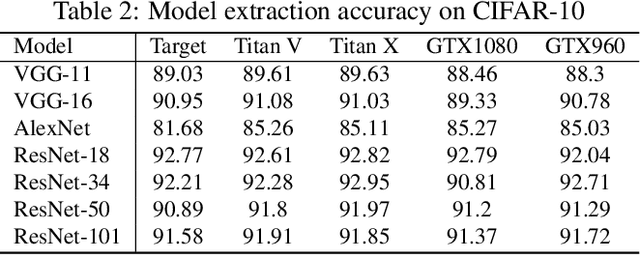
Neural network applications have become popular in both enterprise and personal settings. Network solutions are tuned meticulously for each task, and designs that can robustly resolve queries end up in high demand. As the commercial value of accurate and performant machine learning models increases, so too does the demand to protect neural architectures as confidential investments. We explore the vulnerability of neural networks deployed as black boxes across accelerated hardware through electromagnetic side channels. We examine the magnetic flux emanating from a graphics processing unit's power cable, as acquired by a cheap $3 induction sensor, and find that this signal betrays the detailed topology and hyperparameters of a black-box neural network model. The attack acquires the magnetic signal for one query with unknown input values, but known input dimensions. The network reconstruction is possible due to the modular layer sequence in which deep neural networks are evaluated. We find that each layer component's evaluation produces an identifiable magnetic signal signature, from which layer topology, width, function type, and sequence order can be inferred using a suitably trained classifier and a joint consistency optimization based on integer programming. We study the extent to which network specifications can be recovered, and consider metrics for comparing network similarity. We demonstrate the potential accuracy of this side channel attack in recovering the details for a broad range of network architectures, including random designs. We consider applications that may exploit this novel side channel exposure, such as adversarial transfer attacks. In response, we discuss countermeasures to protect against our method and other similar snooping techniques.
STRODE: Stochastic Boundary Ordinary Differential Equation
Jul 17, 2021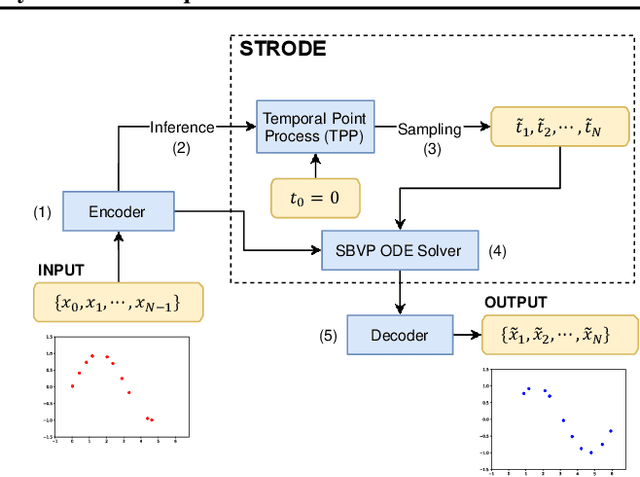

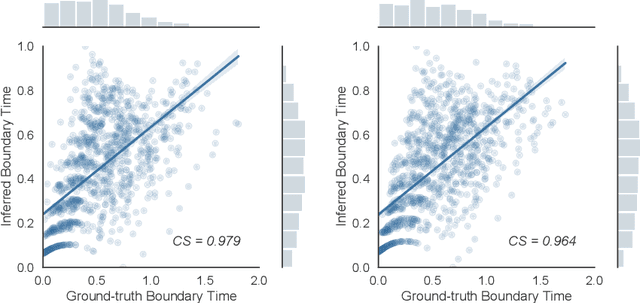

Perception of time from sequentially acquired sensory inputs is rooted in everyday behaviors of individual organisms. Yet, most algorithms for time-series modeling fail to learn dynamics of random event timings directly from visual or audio inputs, requiring timing annotations during training that are usually unavailable for real-world applications. For instance, neuroscience perspectives on postdiction imply that there exist variable temporal ranges within which the incoming sensory inputs can affect the earlier perception, but such temporal ranges are mostly unannotated for real applications such as automatic speech recognition (ASR). In this paper, we present a probabilistic ordinary differential equation (ODE), called STochastic boundaRy ODE (STRODE), that learns both the timings and the dynamics of time series data without requiring any timing annotations during training. STRODE allows the usage of differential equations to sample from the posterior point processes, efficiently and analytically. We further provide theoretical guarantees on the learning of STRODE. Our empirical results show that our approach successfully infers event timings of time series data. Our method achieves competitive or superior performances compared to existing state-of-the-art methods for both synthetic and real-world datasets.
DeepCAD: A Deep Generative Network for Computer-Aided Design Models
May 20, 2021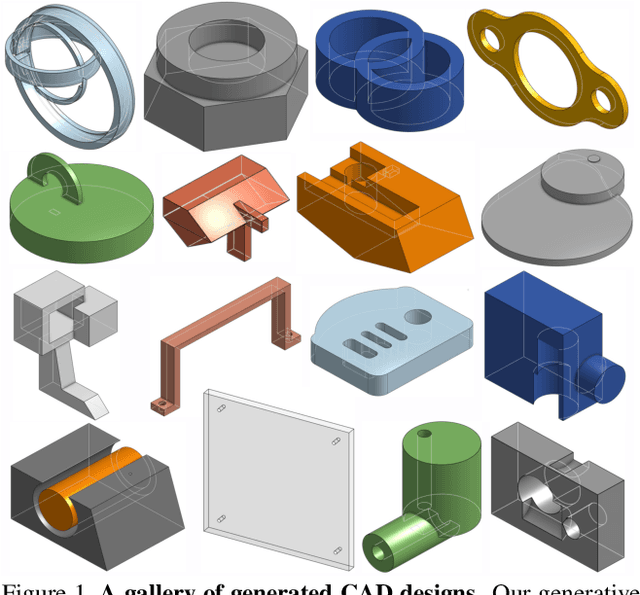
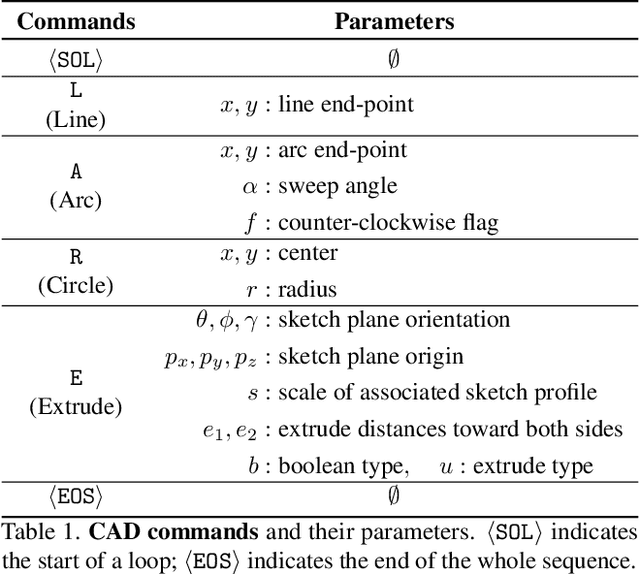
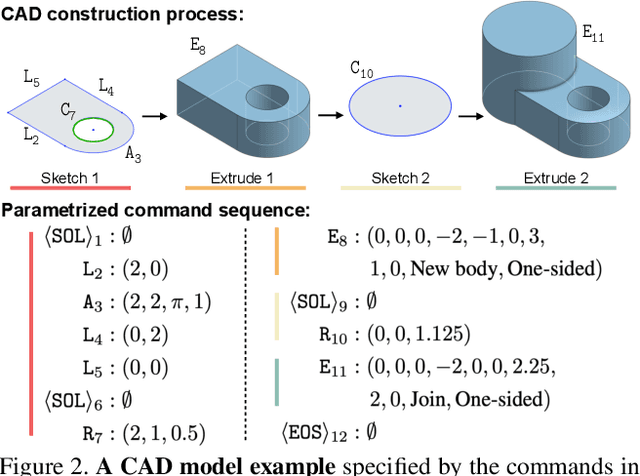
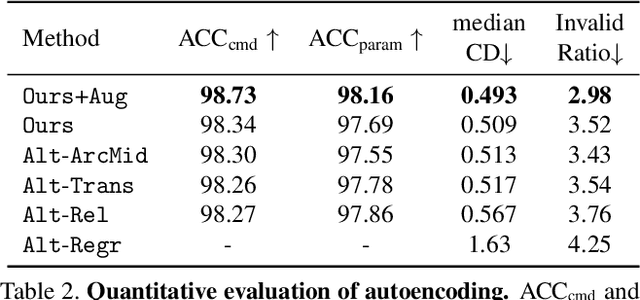
Deep generative models of 3D shapes have received a great deal of research interest. Yet, almost all of them generate discrete shape representations, such as voxels, point clouds, and polygon meshes. We present the first 3D generative model for a drastically different shape representation -- describing a shape as a sequence of computer-aided design (CAD) operations. Unlike meshes and point clouds, CAD models encode the user creation process of 3D shapes, widely used in numerous industrial and engineering design tasks. However, the sequential and irregular structure of CAD operations poses significant challenges for existing 3D generative models. Drawing an analogy between CAD operations and natural language, we propose a CAD generative network based on the Transformer. We demonstrate the performance of our model for both shape autoencoding and random shape generation. To train our network, we create a new CAD dataset consisting of 179,133 models and their CAD construction sequences. We have made this dataset publicly available to promote future research on this topic.
RP2K: A Large-Scale Retail Product Dataset for Fine-Grained Image Classification
Jul 08, 2020
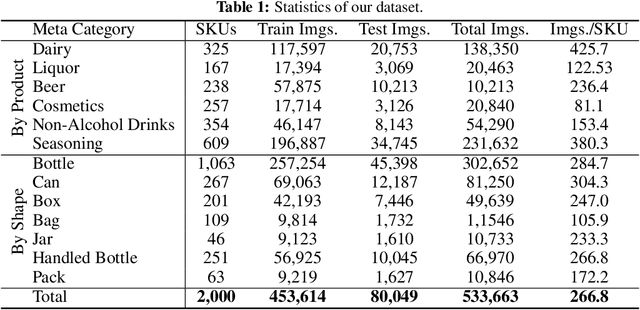
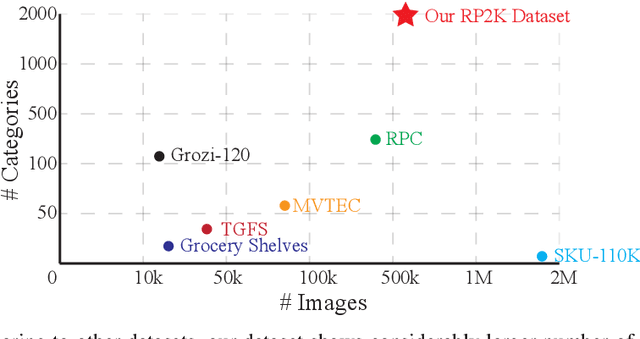
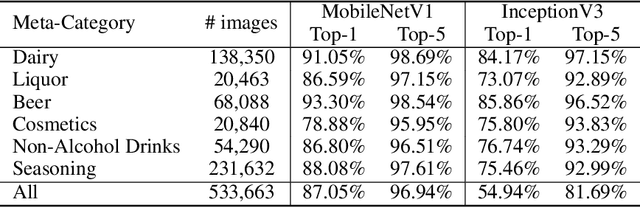
We introduce RP2K, a new large-scale retail product dataset for fine-grained image classification. Unlike previous datasets focusing on relatively few products, we collect more than 500,000 images of retail products on shelves belonging to 2000 different products. Our dataset aims to advance the research in retail object recognition, which has massive applications such as automatic shelf auditing and image-based product information retrieval. Our dataset enjoys following properties: (1) It is by far the largest scale dataset in terms of product categories. (2) All images are captured manually in physical retail stores with natural lightings, matching the scenario of real applications. (3) We provide rich annotations to each object, including the sizes, shapes and flavors/scents. We believe our dataset could benefit both computer vision research and retail industry. Our dataset is publicly available at https://www.pinlandata.com/rp2k_dataset.