 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Hypothesis Generation for LLM-Based Text Analysis with Researcher-Specified Covariates
Jun 02, 2026A core goal of computational social science is to discover interpretable differences in how language varies across outcomes of interest, such as political affiliation or instructional quality. Recent LLM-based hypothesis generation methods describe such differences in natural language, but select for globally discriminative patterns without accounting for covariates that shape the data based on researchers' domain knowledge. When covariates are ignored, selected patterns can reflect confounds rather than differences of substantive interest. We introduce conditional hypothesis generation, a framework that incorporates researcher-specified covariates to steer hypothesis discovery toward differences that hold within relevant subgroups. Two challenges arise: the target subgroup may be underrepresented (stratum imbalance), and the direction of a difference may reverse across subgroups (sign reversal). We propose two econometrics-inspired methods: one introduces feature--covariate interactions to detect sign reversals, and the other applies within-stratum demeaning and inverse-frequency reweighting to equalize underrepresented strata. Synthetic experiments show each method outperforms global baselines in its targeted setting, and expert evaluation on two real-world datasets confirms that covariate-aware generation surfaces more useful hypotheses within relevant subgroups.
DISCO Balances the Scales: Adaptive Domain- and Difficulty-Aware Reinforcement Learning on Imbalanced Data
May 21, 2025Large Language Models (LLMs) are increasingly aligned with human preferences through Reinforcement Learning from Human Feedback (RLHF). Among RLHF methods, Group Relative Policy Optimization (GRPO) has gained attention for its simplicity and strong performance, notably eliminating the need for a learned value function. However, GRPO implicitly assumes a balanced domain distribution and uniform semantic alignment across groups - assumptions that rarely hold in real-world datasets. When applied to multi-domain, imbalanced data, GRPO disproportionately optimizes for dominant domains, neglecting underrepresented ones and resulting in poor generalization and fairness. We propose Domain-Informed Self-Consistency Policy Optimization (DISCO), a principled extension to GRPO that addresses inter-group imbalance with two key innovations. Domain-aware reward scaling counteracts frequency bias by reweighting optimization based on domain prevalence. Difficulty-aware reward scaling leverages prompt-level self-consistency to identify and prioritize uncertain prompts that offer greater learning value. Together, these strategies promote more equitable and effective policy learning across domains. Extensive experiments across multiple LLMs and skewed training distributions show that DISCO improves generalization, outperforms existing GRPO variants by 5% on Qwen3 models, and sets new state-of-the-art results on multi-domain alignment benchmarks.
Skill Discovery for Software Scripting Automation via Offline Simulations with LLMs
Apr 29, 2025Scripting interfaces enable users to automate tasks and customize software workflows, but creating scripts traditionally requires programming expertise and familiarity with specific APIs, posing barriers for many users. While Large Language Models (LLMs) can generate code from natural language queries, runtime code generation is severely limited due to unverified code, security risks, longer response times, and higher computational costs. To bridge the gap, we propose an offline simulation framework to curate a software-specific skillset, a collection of verified scripts, by exploiting LLMs and publicly available scripting guides. Our framework comprises two components: (1) task creation, using top-down functionality guidance and bottom-up API synergy exploration to generate helpful tasks; and (2) skill generation with trials, refining and validating scripts based on execution feedback. To efficiently navigate the extensive API landscape, we introduce a Graph Neural Network (GNN)-based link prediction model to capture API synergy, enabling the generation of skills involving underutilized APIs and expanding the skillset's diversity. Experiments with Adobe Illustrator demonstrate that our framework significantly improves automation success rates, reduces response time, and saves runtime token costs compared to traditional runtime code generation. This is the first attempt to use software scripting interfaces as a testbed for LLM-based systems, highlighting the advantages of leveraging execution feedback in a controlled environment and offering valuable insights into aligning AI capabilities with user needs in specialized software domains.
Large Language Models Struggle to Describe the Haystack without Human Help: Human-in-the-loop Evaluation of LLMs
Feb 20, 2025A common use of NLP is to facilitate the understanding of large document collections, with a shift from using traditional topic models to Large Language Models. Yet the effectiveness of using LLM for large corpus understanding in real-world applications remains under-explored. This study measures the knowledge users acquire with unsupervised, supervised LLM-based exploratory approaches or traditional topic models on two datasets. While LLM-based methods generate more human-readable topics and show higher average win probabilities than traditional models for data exploration, they produce overly generic topics for domain-specific datasets that do not easily allow users to learn much about the documents. Adding human supervision to the LLM generation process improves data exploration by mitigating hallucination and over-genericity but requires greater human effort. In contrast, traditional. models like Latent Dirichlet Allocation (LDA) remain effective for exploration but are less user-friendly. We show that LLMs struggle to describe the haystack of large corpora without human help, particularly domain-specific data, and face scaling and hallucination limitations due to context length constraints. Dataset available at https://huggingface. co/datasets/zli12321/Bills.
Multi-Stage Balanced Distillation: Addressing Long-Tail Challenges in Sequence-Level Knowledge Distillation
Jun 19, 2024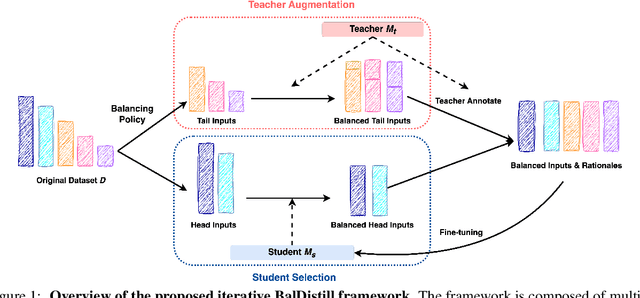
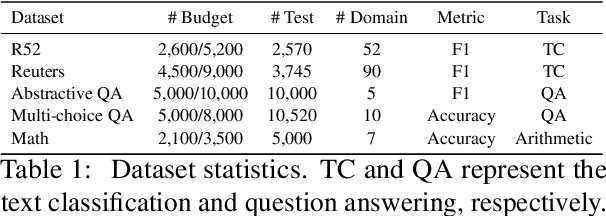
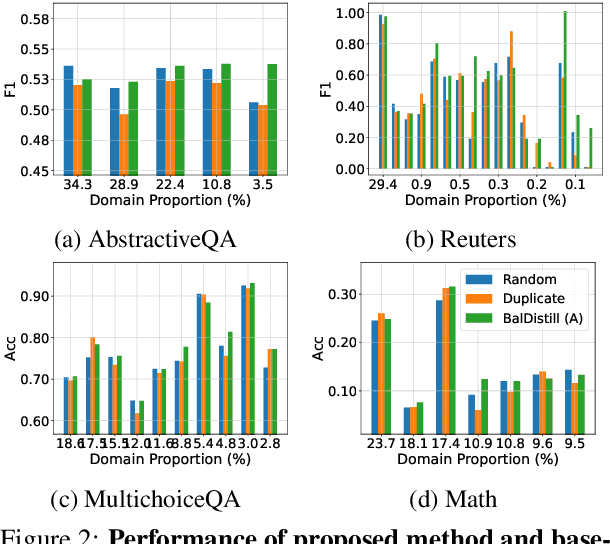
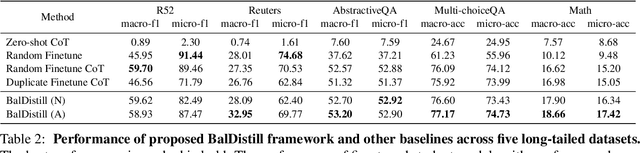
Large language models (LLMs) have significantly advanced various natural language processing tasks, but deploying them remains computationally expensive. Knowledge distillation (KD) is a promising solution, enabling the transfer of capabilities from larger teacher LLMs to more compact student models. Particularly, sequence-level KD, which distills rationale-based reasoning processes instead of merely final outcomes, shows great potential in enhancing students' reasoning capabilities. However, current methods struggle with sequence level KD under long-tailed data distributions, adversely affecting generalization on sparsely represented domains. We introduce the Multi-Stage Balanced Distillation (BalDistill) framework, which iteratively balances training data within a fixed computational budget. By dynamically selecting representative head domain examples and synthesizing tail domain examples, BalDistill achieves state-of-the-art performance across diverse long-tailed datasets, enhancing both the efficiency and efficacy of the distilled models.
Does Geo-co-location Matter? A Case Study of Public Health Conversations during COVID-19
May 28, 2024Social media platforms like Twitter (now X) have been pivotal in information dissemination and public engagement, especially during COVID-19. A key goal for public health experts was to encourage prosocial behavior that could impact local outcomes such as masking and social distancing. Given the importance of local news and guidance during COVID-19, the objective of our research is to analyze the effect of localized engagement, on social media conversations. This study examines the impact of geographic co-location, as a proxy for localized engagement between public health experts (PHEs) and the public, on social media. We analyze a Twitter conversation dataset from January 2020 to November 2021, comprising over 19 K tweets from nearly five hundred PHEs, along with approximately 800 K replies from 350 K participants. Our findings reveal that geo-co-location is associated with higher engagement rates, especially in conversations on topics including masking, lockdowns, and education, and in conversations with academic and medical professionals. Lexical features associated with emotion and personal experiences were more common in geo-co-located contexts. This research provides insights into how geographic co-location influences social media engagement and can inform strategies to improve public health messaging.
The Promises and Pitfalls of Using Language Models to Measure Instruction Quality in Education
Apr 03, 2024Assessing instruction quality is a fundamental component of any improvement efforts in the education system. However, traditional manual assessments are expensive, subjective, and heavily dependent on observers' expertise and idiosyncratic factors, preventing teachers from getting timely and frequent feedback. Different from prior research that mostly focuses on low-inference instructional practices on a singular basis, this paper presents the first study that leverages Natural Language Processing (NLP) techniques to assess multiple high-inference instructional practices in two distinct educational settings: in-person K-12 classrooms and simulated performance tasks for pre-service teachers. This is also the first study that applies NLP to measure a teaching practice that is widely acknowledged to be particularly effective for students with special needs. We confront two challenges inherent in NLP-based instructional analysis, including noisy and long input data and highly skewed distributions of human ratings. Our results suggest that pretrained Language Models (PLMs) demonstrate performances comparable to the agreement level of human raters for variables that are more discrete and require lower inference, but their efficacy diminishes with more complex teaching practices. Interestingly, using only teachers' utterances as input yields strong results for student-centered variables, alleviating common concerns over the difficulty of collecting and transcribing high-quality student speech data in in-person teaching settings. Our findings highlight both the potential and the limitations of current NLP techniques in the education domain, opening avenues for further exploration.
Large Language Models and Causal Inference in Collaboration: A Comprehensive Survey
Mar 14, 2024

Causal inference has shown potential in enhancing the predictive accuracy, fairness, robustness, and explainability of Natural Language Processing (NLP) models by capturing causal relationships among variables. The emergence of generative Large Language Models (LLMs) has significantly impacted various NLP domains, particularly through their advanced reasoning capabilities. This survey focuses on evaluating and improving LLMs from a causal view in the following areas: understanding and improving the LLMs' reasoning capacity, addressing fairness and safety issues in LLMs, complementing LLMs with explanations, and handling multimodality. Meanwhile, LLMs' strong reasoning capacities can in turn contribute to the field of causal inference by aiding causal relationship discovery and causal effect estimations. This review explores the interplay between causal inference frameworks and LLMs from both perspectives, emphasizing their collective potential to further the development of more advanced and equitable artificial intelligence systems.
Emojis Decoded: Leveraging ChatGPT for Enhanced Understanding in Social Media Communications
Jan 22, 2024
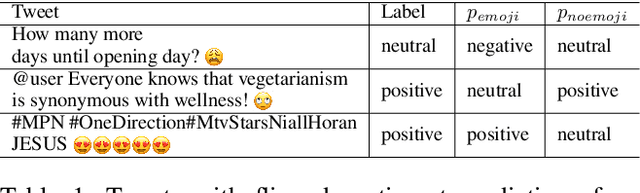


Emojis, which encapsulate semantics beyond mere words or phrases, have become prevalent in social network communications. This has spurred increasing scholarly interest in exploring their attributes and functionalities. However, emoji-related research and application face two primary challenges. First, researchers typically rely on crowd-sourcing to annotate emojis in order to understand their sentiments, usage intentions, and semantic meanings. Second, subjective interpretations by users can often lead to misunderstandings of emojis and cause the communication barrier. Large Language Models (LLMs) have achieved significant success in various annotation tasks, with ChatGPT demonstrating expertise across multiple domains. In our study, we assess ChatGPT's effectiveness in handling previously annotated and downstream tasks. Our objective is to validate the hypothesis that ChatGPT can serve as a viable alternative to human annotators in emoji research and that its ability to explain emoji meanings can enhance clarity and transparency in online communications. Our findings indicate that ChatGPT has extensive knowledge of emojis. It is adept at elucidating the meaning of emojis across various application scenarios and demonstrates the potential to replace human annotators in a range of tasks.
Explore Spurious Correlations at the Concept Level in Language Models for Text Classification
Nov 15, 2023Language models (LMs) have gained great achievement in various NLP tasks for both fine-tuning and in-context learning (ICL) methods. Despite its outstanding performance, evidence shows that spurious correlations caused by imbalanced label distributions in training data (or exemplars in ICL) lead to robustness issues. However, previous studies mostly focus on word- and phrase-level features and fail to tackle it from the concept level, partly due to the lack of concept labels and subtle and diverse expressions of concepts in text. In this paper, we first use the LLM to label the concept for each text and then measure the concept bias of models for fine-tuning or ICL on the test data. Second, we propose a data rebalancing method to mitigate the spurious correlations by adding the LLM-generated counterfactual data to make a balanced label distribution for each concept. We verify the effectiveness of our mitigation method and show its superiority over the token removal method. Overall, our results show that there exist label distribution biases in concepts across multiple text classification datasets, and LMs will utilize these shortcuts to make predictions in both fine-tuning and ICL methods.