 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding In-Context Learning with Contrastive Demonstrations and Saliency Maps
Jul 11, 2023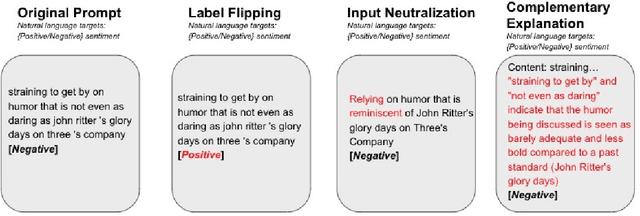

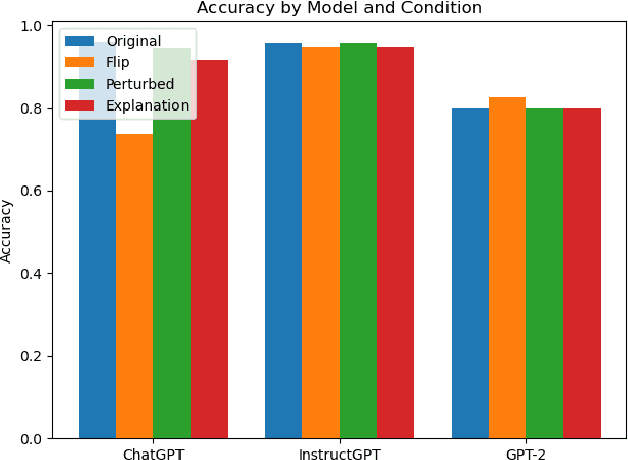

We investigate the role of various demonstration components in the in-context learning (ICL) performance of large language models (LLMs). Specifically, we explore the impacts of ground-truth labels, input distribution, and complementary explanations, particularly when these are altered or perturbed. We build on previous work, which offers mixed findings on how these elements influence ICL. To probe these questions, we employ explainable NLP (XNLP) methods and utilize saliency maps of contrastive demonstrations for both qualitative and quantitative analysis. Our findings reveal that flipping ground-truth labels significantly affects the saliency, though it's more noticeable in larger LLMs. Our analysis of the input distribution at a granular level reveals that changing sentiment-indicative terms in a sentiment analysis task to neutral ones does not have as substantial an impact as altering ground-truth labels. Finally, we find that the effectiveness of complementary explanations in boosting ICL performance is task-dependent, with limited benefits seen in sentiment analysis tasks compared to symbolic reasoning tasks. These insights are critical for understanding the functionality of LLMs and guiding the development of effective demonstrations, which is increasingly relevant in light of the growing use of LLMs in applications such as ChatGPT. Our research code is publicly available at https://github.com/paihengxu/XICL.