 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisPlay: Self-Evolving Vision-Language Models from Images
Nov 19, 2025Reinforcement learning (RL) provides a principled framework for improving Vision-Language Models (VLMs) on complex reasoning tasks. However, existing RL approaches often rely on human-annotated labels or task-specific heuristics to define verifiable rewards, both of which are costly and difficult to scale. We introduce VisPlay, a self-evolving RL framework that enables VLMs to autonomously improve their reasoning abilities using large amounts of unlabeled image data. Starting from a single base VLM, VisPlay assigns the model into two interacting roles: an Image-Conditioned Questioner that formulates challenging yet answerable visual questions, and a Multimodal Reasoner that generates silver responses. These roles are jointly trained with Group Relative Policy Optimization (GRPO), which incorporates diversity and difficulty rewards to balance the complexity of generated questions with the quality of the silver answers. VisPlay scales efficiently across two model families. When trained on Qwen2.5-VL and MiMo-VL, VisPlay achieves consistent improvements in visual reasoning, compositional generalization, and hallucination reduction across eight benchmarks, including MM-Vet and MMMU, demonstrating a scalable path toward self-evolving multimodal intelligence. The project page is available at https://bruno686.github.io/VisPlay/
First Frame Is the Place to Go for Video Content Customization
Nov 19, 2025What role does the first frame play in video generation models? Traditionally, it's viewed as the spatial-temporal starting point of a video, merely a seed for subsequent animation. In this work, we reveal a fundamentally different perspective: video models implicitly treat the first frame as a conceptual memory buffer that stores visual entities for later reuse during generation. Leveraging this insight, we show that it's possible to achieve robust and generalized video content customization in diverse scenarios, using only 20-50 training examples without architectural changes or large-scale finetuning. This unveils a powerful, overlooked capability of video generation models for reference-based video customization.
VOGUE: Guiding Exploration with Visual Uncertainty Improves Multimodal Reasoning
Oct 01, 2025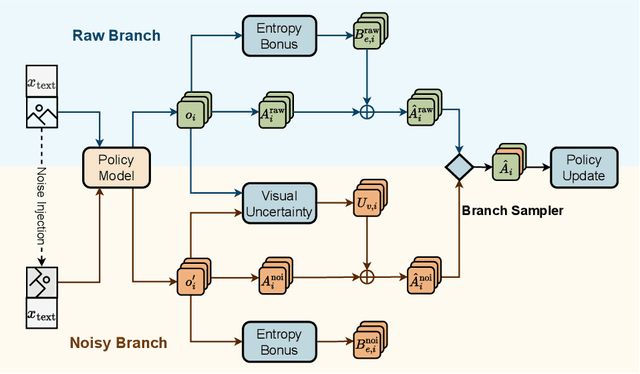
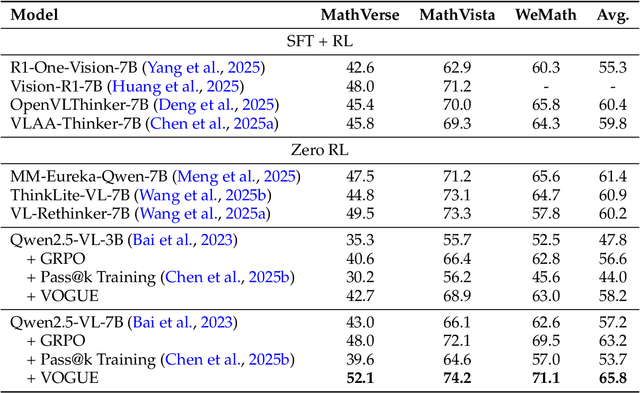
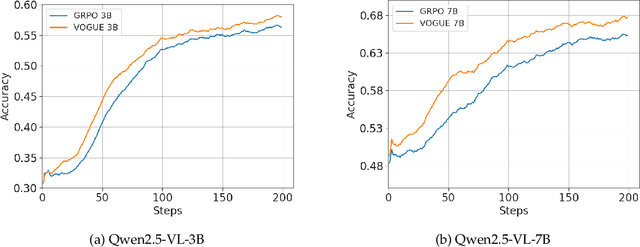
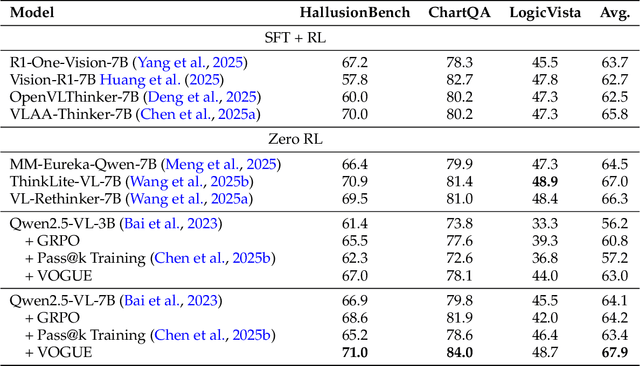
Reinforcement learning with verifiable rewards (RLVR) improves reasoning in large language models (LLMs) but struggles with exploration, an issue that still persists for multimodal LLMs (MLLMs). Current methods treat the visual input as a fixed, deterministic condition, overlooking a critical source of ambiguity and struggling to build policies robust to plausible visual variations. We introduce $\textbf{VOGUE (Visual Uncertainty Guided Exploration)}$, a novel method that shifts exploration from the output (text) to the input (visual) space. By treating the image as a stochastic context, VOGUE quantifies the policy's sensitivity to visual perturbations using the symmetric KL divergence between a "raw" and "noisy" branch, creating a direct signal for uncertainty-aware exploration. This signal shapes the learning objective via an uncertainty-proportional bonus, which, combined with a token-entropy bonus and an annealed sampling schedule, effectively balances exploration and exploitation. Implemented within GRPO on two model scales (Qwen2.5-VL-3B/7B), VOGUE boosts pass@1 accuracy by an average of 2.6% on three visual math benchmarks and 3.7% on three general-domain reasoning benchmarks, while simultaneously increasing pass@4 performance and mitigating the exploration decay commonly observed in RL fine-tuning. Our work shows that grounding exploration in the inherent uncertainty of visual inputs is an effective strategy for improving multimodal reasoning.
Self-Rewarding Vision-Language Model via Reasoning Decomposition
Aug 27, 2025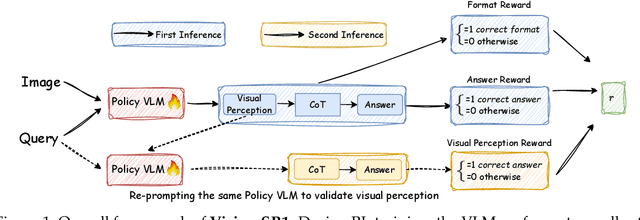
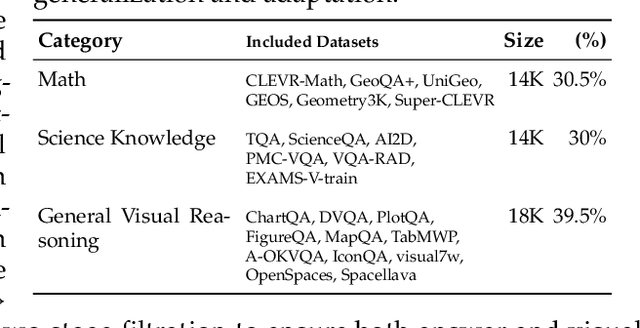
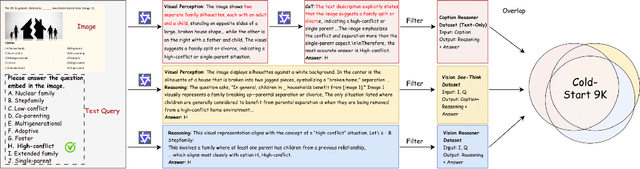
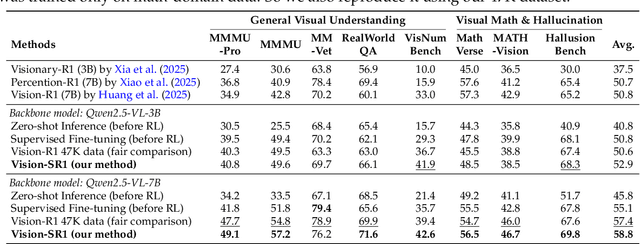
Vision-Language Models (VLMs) often suffer from visual hallucinations, saying things that are not actually in the image, and language shortcuts, where they skip the visual part and just rely on text priors. These issues arise because most post-training methods for VLMs rely on simple verifiable answer matching and supervise only final outputs, leaving intermediate visual reasoning without explicit guidance. As a result, VLMs receive sparse visual signals and often learn to prioritize language-based reasoning over visual perception. To mitigate this, some existing methods add visual supervision using human annotations or distilled labels from external large models. However, human annotations are labor-intensive and costly, and because external signals cannot adapt to the evolving policy, they cause distributional shifts that can lead to reward hacking. In this paper, we introduce Vision-SR1, a self-rewarding method that improves visual reasoning without relying on external visual supervisions via reinforcement learning. Vision-SR1 decomposes VLM reasoning into two stages: visual perception and language reasoning. The model is first prompted to produce self-contained visual perceptions that are sufficient to answer the question without referring back the input image. To validate this self-containment, the same VLM model is then re-prompted to perform language reasoning using only the generated perception as input to compute reward. This self-reward is combined with supervision on final outputs, providing a balanced training signal that strengthens both visual perception and language reasoning. Our experiments demonstrate that Vision-SR1 improves visual reasoning, mitigates visual hallucinations, and reduces reliance on language shortcuts across diverse vision-language tasks.
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Aug 07, 2025



Self-evolving Large Language Models (LLMs) offer a scalable path toward super-intelligence by autonomously generating, refining, and learning from their own experiences. However, existing methods for training such models still rely heavily on vast human-curated tasks and labels, typically via fine-tuning or reinforcement learning, which poses a fundamental bottleneck to advancing AI systems toward capabilities beyond human intelligence. To overcome this limitation, we introduce R-Zero, a fully autonomous framework that generates its own training data from scratch. Starting from a single base LLM, R-Zero initializes two independent models with distinct roles, a Challenger and a Solver. These models are optimized separately and co-evolve through interaction: the Challenger is rewarded for proposing tasks near the edge of the Solver capability, and the Solver is rewarded for solving increasingly challenging tasks posed by the Challenger. This process yields a targeted, self-improving curriculum without any pre-existing tasks and labels. Empirically, R-Zero substantially improves reasoning capability across different backbone LLMs, e.g., boosting the Qwen3-4B-Base by +6.49 on math-reasoning benchmarks and +7.54 on general-domain reasoning benchmarks.
Semantically-Aware Rewards for Open-Ended R1 Training in Free-Form Generation
Jun 18, 2025Evaluating open-ended long-form generation is challenging because it is hard to define what clearly separates good from bad outputs. Existing methods often miss key aspects like coherence, style, or relevance, or are biased by pretraining data, making open-ended long-form evaluation an underexplored problem. To address this gap, we propose PrefBERT, a scoring model for evaluating open-ended long-form generation in GRPO and guiding its training with distinct rewards for good and bad outputs. Trained on two response evaluation datasets with diverse long-form styles and Likert-rated quality, PrefBERT effectively supports GRPO by offering better semantic reward feedback than traditional metrics ROUGE-L and BERTScore do. Through comprehensive evaluations, including LLM-as-a-judge, human ratings, and qualitative analysis, we show that PrefBERT, trained on multi-sentence and paragraph-length responses, remains reliable across varied long passages and aligns well with the verifiable rewards GRPO needs. Human evaluations confirm that using PrefBERT as the reward signal to train policy models yields responses better aligned with human preferences than those trained with traditional metrics. Our code is available at https://github.com/zli12321/long_form_rl.
VideoHallu: Evaluating and Mitigating Multi-modal Hallucinations for Synthetic Videos
May 02, 2025Synthetic video generation with foundation models has gained attention for its realism and wide applications. While these models produce high-quality frames, they often fail to respect common sense and physical laws, resulting in abnormal content. Existing metrics like VideoScore emphasize general quality but ignore such violations and lack interpretability. A more insightful approach is using multi-modal large language models (MLLMs) as interpretable evaluators, as seen in FactScore. Yet, MLLMs' ability to detect abnormalities in synthetic videos remains underexplored. To address this, we introduce VideoHallu, a benchmark featuring synthetic videos from models like Veo2, Sora, and Kling, paired with expert-designed QA tasks solvable via human-level reasoning across various categories. We assess several SoTA MLLMs, including GPT-4o, Gemini-2.5-Pro, Qwen-2.5-VL, and newer models like Video-R1 and VideoChat-R1. Despite strong real-world performance on MVBench and MovieChat, these models still hallucinate on basic commonsense and physics tasks in synthetic settings, underscoring the challenge of hallucination. We further fine-tune SoTA MLLMs using Group Relative Policy Optimization (GRPO) on real and synthetic commonsense/physics data. Results show notable accuracy gains, especially with counterexample integration, advancing MLLMs' reasoning capabilities. Our data is available at https://github.com/zli12321/VideoHallu.
Large Language Models Are Effective Human Annotation Assistants, But Not Good Independent Annotators
Mar 09, 2025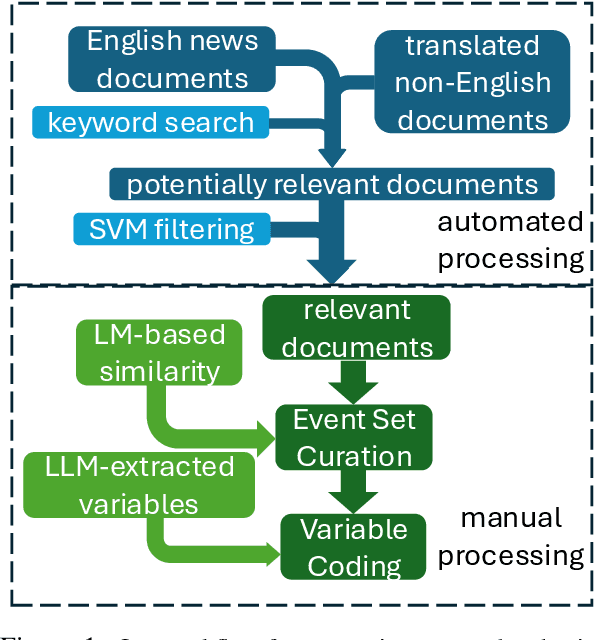
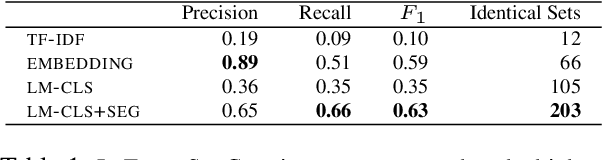

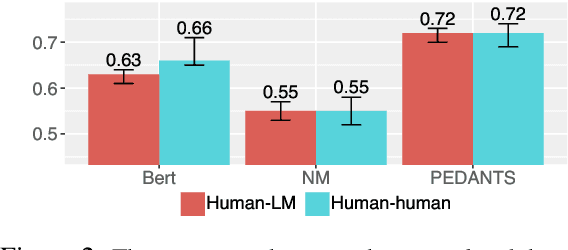
Event annotation is important for identifying market changes, monitoring breaking news, and understanding sociological trends. Although expert annotators set the gold standards, human coding is expensive and inefficient. Unlike information extraction experiments that focus on single contexts, we evaluate a holistic workflow that removes irrelevant documents, merges documents about the same event, and annotates the events. Although LLM-based automated annotations are better than traditional TF-IDF-based methods or Event Set Curation, they are still not reliable annotators compared to human experts. However, adding LLMs to assist experts for Event Set Curation can reduce the time and mental effort required for Variable Annotation. When using LLMs to extract event variables to assist expert annotators, they agree more with the extracted variables than fully automated LLMs for annotation.
Large Language Models Struggle to Describe the Haystack without Human Help: Human-in-the-loop Evaluation of LLMs
Feb 20, 2025A common use of NLP is to facilitate the understanding of large document collections, with a shift from using traditional topic models to Large Language Models. Yet the effectiveness of using LLM for large corpus understanding in real-world applications remains under-explored. This study measures the knowledge users acquire with unsupervised, supervised LLM-based exploratory approaches or traditional topic models on two datasets. While LLM-based methods generate more human-readable topics and show higher average win probabilities than traditional models for data exploration, they produce overly generic topics for domain-specific datasets that do not easily allow users to learn much about the documents. Adding human supervision to the LLM generation process improves data exploration by mitigating hallucination and over-genericity but requires greater human effort. In contrast, traditional. models like Latent Dirichlet Allocation (LDA) remain effective for exploration but are less user-friendly. We show that LLMs struggle to describe the haystack of large corpora without human help, particularly domain-specific data, and face scaling and hallucination limitations due to context length constraints. Dataset available at https://huggingface. co/datasets/zli12321/Bills.
Benchmark Evaluations, Applications, and Challenges of Large Vision Language Models: A Survey
Jan 04, 2025



Multimodal Vision Language Models (VLMs) have emerged as a transformative technology at the intersection of computer vision and natural language processing, enabling machines to perceive and reason about the world through both visual and textual modalities. For example, models such as CLIP, Claude, and GPT-4V demonstrate strong reasoning and understanding abilities on visual and textual data and beat classical single modality vision models on zero-shot classification. Despite their rapid advancements in research and growing popularity in applications, a comprehensive survey of existing studies on VLMs is notably lacking, particularly for researchers aiming to leverage VLMs in their specific domains. To this end, we provide a systematic overview of VLMs in the following aspects: model information of the major VLMs developed over the past five years (2019-2024); the main architectures and training methods of these VLMs; summary and categorization of the popular benchmarks and evaluation metrics of VLMs; the applications of VLMs including embodied agents, robotics, and video generation; the challenges and issues faced by current VLMs such as hallucination, fairness, and safety. Detailed collections including papers and model repository links are listed in https://github.com/zli12321/Awesome-VLM-Papers-And-Models.git.