 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Automated Evaluation Metrics: Evaluating Topic Models On Practical Social Science Content Analysis Tasks
Jan 29, 2024Topic models are a popular tool for understanding text collections, but their evaluation has been a point of contention. Automated evaluation metrics such as coherence are often used, however, their validity has been questioned for neural topic models (NTMs) and can overlook the benefits of a model in real world applications. To this end, we conduct the first evaluation of neural, supervised and classical topic models in an interactive task based setting. We combine topic models with a classifier and test their ability to help humans conduct content analysis and document annotation. From simulated, real user and expert pilot studies, the Contextual Neural Topic Model does the best on cluster evaluation metrics and human evaluations; however, LDA is competitive with two other NTMs under our simulated experiment and user study results, contrary to what coherence scores suggest. We show that current automated metrics do not provide a complete picture of topic modeling capabilities, but the right choice of NTMs can be better than classical models on practical tasks.
Making the Implicit Explicit: Implicit Content as a First Class Citizen in NLP
May 23, 2023Language is multifaceted. A given utterance can be re-expressed in equivalent forms, and its implicit and explicit content support various logical and pragmatic inferences. When processing an utterance, we consider these different aspects, as mediated by our interpretive goals -- understanding that "it's dark in here" may be a veiled direction to turn on a light. Nonetheless, NLP methods typically operate over the surface form alone, eliding this nuance. In this work, we represent language with language, and direct an LLM to decompose utterances into logical and plausible inferences. The reduced complexity of the decompositions makes them easier to embed, opening up novel applications. Variations on our technique lead to state-of-the-art improvements on sentence embedding benchmarks, a substantive application in computational political science, and to a novel construct-discovery process, which we validate with human annotations.
Are Neural Topic Models Broken?
Oct 28, 2022Recently, the relationship between automated and human evaluation of topic models has been called into question. Method developers have staked the efficacy of new topic model variants on automated measures, and their failure to approximate human preferences places these models on uncertain ground. Moreover, existing evaluation paradigms are often divorced from real-world use. Motivated by content analysis as a dominant real-world use case for topic modeling, we analyze two related aspects of topic models that affect their effectiveness and trustworthiness in practice for that purpose: the stability of their estimates and the extent to which the model's discovered categories align with human-determined categories in the data. We find that neural topic models fare worse in both respects compared to an established classical method. We take a step toward addressing both issues in tandem by demonstrating that a straightforward ensembling method can reliably outperform the members of the ensemble.
Studying word order through iterative shuffling
Sep 10, 2021
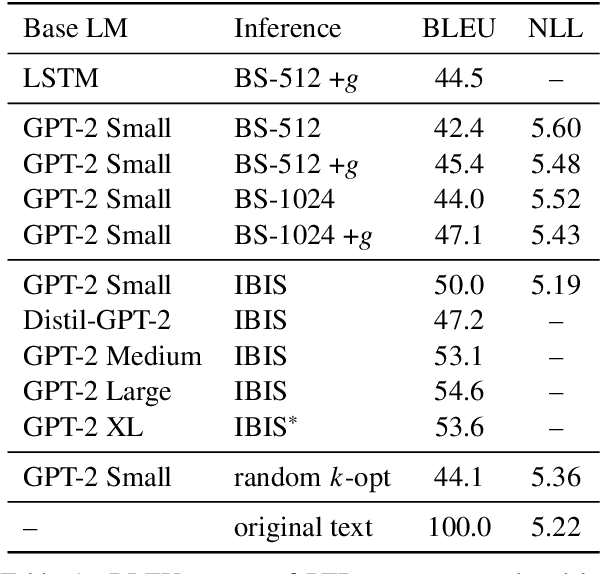


As neural language models approach human performance on NLP benchmark tasks, their advances are widely seen as evidence of an increasingly complex understanding of syntax. This view rests upon a hypothesis that has not yet been empirically tested: that word order encodes meaning essential to performing these tasks. We refute this hypothesis in many cases: in the GLUE suite and in various genres of English text, the words in a sentence or phrase can rarely be permuted to form a phrase carrying substantially different information. Our surprising result relies on inference by iterative shuffling (IBIS), a novel, efficient procedure that finds the ordering of a bag of words having the highest likelihood under a fixed language model. IBIS can use any black-box model without additional training and is superior to existing word ordering algorithms. Coalescing our findings, we discuss how shuffling inference procedures such as IBIS can benefit language modeling and constrained generation.
Is Automated Topic Model Evaluation Broken?: The Incoherence of Coherence
Jul 05, 2021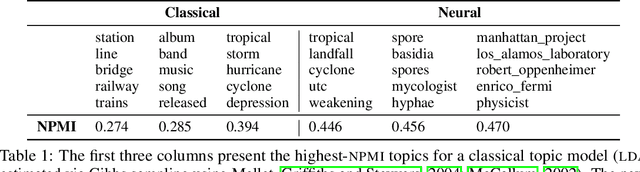


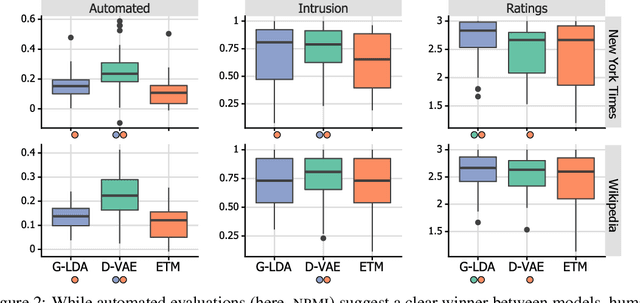
Topic model evaluation, like evaluation of other unsupervised methods, can be contentious. However, the field has coalesced around automated estimates of topic coherence, which rely on the frequency of word co-occurrences in a reference corpus. Recent models relying on neural components surpass classical topic models according to these metrics. At the same time, unlike classical models, the practice of neural topic model evaluation suffers from a validation gap: automatic coherence for neural models has not been validated using human experimentation. In addition, as we show via a meta-analysis of topic modeling literature, there is a substantial standardization gap in the use of automated topic modeling benchmarks. We address both the standardization gap and the validation gap. Using two of the most widely used topic model evaluation datasets, we assess a dominant classical model and two state-of-the-art neural models in a systematic, clearly documented, reproducible way. We use automatic coherence along with the two most widely accepted human judgment tasks, namely, topic rating and word intrusion. Automated evaluation will declare one model significantly different from another when corresponding human evaluations do not, calling into question the validity of fully automatic evaluations independent of human judgments.
Improving Neural Topic Models using Knowledge Distillation
Oct 05, 2020



Topic models are often used to identify human-interpretable topics to help make sense of large document collections. We use knowledge distillation to combine the best attributes of probabilistic topic models and pretrained transformers. Our modular method can be straightforwardly applied with any neural topic model to improve topic quality, which we demonstrate using two models having disparate architectures, obtaining state-of-the-art topic coherence. We show that our adaptable framework not only improves performance in the aggregate over all estimated topics, as is commonly reported, but also in head-to-head comparisons of aligned topics.
Towards Automatic Generation of Questions from Long Answers
Apr 15, 2020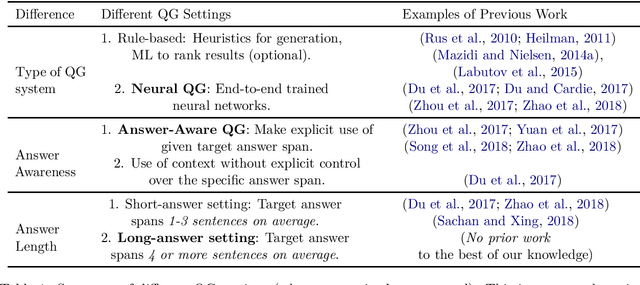

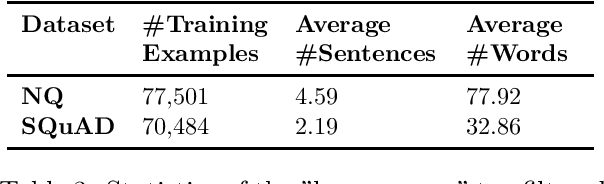

Automatic question generation (AQG) has broad applicability in domains such as tutoring systems, conversational agents, healthcare literacy, and information retrieval. Existing efforts at AQG have been limited to short answer lengths of up to two or three sentences. However, several real-world applications require question generation from answers that span several sentences. Therefore, we propose a novel evaluation benchmark to assess the performance of existing AQG systems for long-text answers. We leverage the large-scale open-source Google Natural Questions dataset to create the aforementioned long-answer AQG benchmark. We empirically demonstrate that the performance of existing AQG methods significantly degrades as the length of the answer increases. Transformer-based methods outperform other existing AQG methods on long answers in terms of automatic as well as human evaluation. However, we still observe degradation in the performance of our best performing models with increasing sentence length, suggesting that long answer QA is a challenging benchmark task for future research.
Automatic Identification of Sarcasm Target: An Introductory Approach
Aug 25, 2017



Past work in computational sarcasm deals primarily with sarcasm detection. In this paper, we introduce a novel, related problem: sarcasm target identification i.e., extracting the target of ridicule in a sarcastic sentence). We present an introductory approach for sarcasm target identification. Our approach employs two types of extractors: one based on rules, and another consisting of a statistical classifier. To compare our approach, we use two baselines: a na\"ive baseline and another baseline based on work in sentiment target identification. We perform our experiments on book snippets and tweets, and show that our hybrid approach performs better than the two baselines and also, in comparison with using the two extractors individually. Our introductory approach establishes the viability of sarcasm target identification, and will serve as a baseline for future work.