 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational User-AI Intervention: A Study on Prompt Rewriting for Improved LLM Response Generation
Mar 21, 2025Human-LLM conversations are increasingly becoming more pervasive in peoples' professional and personal lives, yet many users still struggle to elicit helpful responses from LLM Chatbots. One of the reasons for this issue is users' lack of understanding in crafting effective prompts that accurately convey their information needs. Meanwhile, the existence of real-world conversational datasets on the one hand, and the text understanding faculties of LLMs on the other, present a unique opportunity to study this problem, and its potential solutions at scale. Thus, in this paper we present the first LLM-centric study of real human-AI chatbot conversations, focused on investigating aspects in which user queries fall short of expressing information needs, and the potential of using LLMs to rewrite suboptimal user prompts. Our findings demonstrate that rephrasing ineffective prompts can elicit better responses from a conversational system, while preserving the user's original intent. Notably, the performance of rewrites improves in longer conversations, where contextual inferences about user needs can be made more accurately. Additionally, we observe that LLMs often need to -- and inherently do -- make \emph{plausible} assumptions about a user's intentions and goals when interpreting prompts. Our findings largely hold true across conversational domains, user intents, and LLMs of varying sizes and families, indicating the promise of using prompt rewriting as a solution for better human-AI interactions.
Understanding Common Ground Misalignment in Goal-Oriented Dialog: A Case-Study with Ubuntu Chat Logs
Mar 16, 2025



While it is commonly accepted that maintaining common ground plays a role in conversational success, little prior research exists connecting conversational grounding to success in task-oriented conversations. We study failures of grounding in the Ubuntu IRC dataset, where participants use text-only communication to resolve technical issues. We find that disruptions in conversational flow often stem from a misalignment in common ground, driven by a divergence in beliefs and assumptions held by participants. These disruptions, which we call conversational friction, significantly correlate with task success. We find that although LLMs can identify overt cases of conversational friction, they struggle with subtler and more context-dependent instances requiring pragmatic or domain-specific reasoning.
Towards Pragmatic Awareness in Question Answering: A Case Study in Maternal and Infant Health
Nov 16, 2023



Questions posed by information-seeking users often contain implicit false or potentially harmful assumptions. In a high-risk domain such as maternal and infant health, a question-answering system must recognize these pragmatic constraints and go beyond simply answering user questions, examining them in context to respond helpfully. To achieve this, we study pragmatic inferences made when mothers ask questions about pregnancy and infant care. Some of the inferences in these questions evade detection by existing methods, risking the possibility of QA systems failing to address them which can have dangerous health and policy implications. We explore the viability of detecting inferences from questions using large language models and illustrate that informing existing QA pipelines with pragmatic inferences produces responses that can mitigate the propagation of harmful beliefs.
Making the Implicit Explicit: Implicit Content as a First Class Citizen in NLP
May 23, 2023Language is multifaceted. A given utterance can be re-expressed in equivalent forms, and its implicit and explicit content support various logical and pragmatic inferences. When processing an utterance, we consider these different aspects, as mediated by our interpretive goals -- understanding that "it's dark in here" may be a veiled direction to turn on a light. Nonetheless, NLP methods typically operate over the surface form alone, eliding this nuance. In this work, we represent language with language, and direct an LLM to decompose utterances into logical and plausible inferences. The reduced complexity of the decompositions makes them easier to embed, opening up novel applications. Variations on our technique lead to state-of-the-art improvements on sentence embedding benchmarks, a substantive application in computational political science, and to a novel construct-discovery process, which we validate with human annotations.
Are Neural Topic Models Broken?
Oct 28, 2022Recently, the relationship between automated and human evaluation of topic models has been called into question. Method developers have staked the efficacy of new topic model variants on automated measures, and their failure to approximate human preferences places these models on uncertain ground. Moreover, existing evaluation paradigms are often divorced from real-world use. Motivated by content analysis as a dominant real-world use case for topic modeling, we analyze two related aspects of topic models that affect their effectiveness and trustworthiness in practice for that purpose: the stability of their estimates and the extent to which the model's discovered categories align with human-determined categories in the data. We find that neural topic models fare worse in both respects compared to an established classical method. We take a step toward addressing both issues in tandem by demonstrating that a straightforward ensembling method can reliably outperform the members of the ensemble.
Fringe News Networks: Dynamics of US News Viewership following the 2020 Presidential Election
Jan 22, 2021
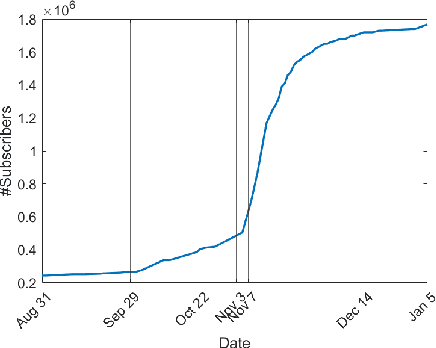
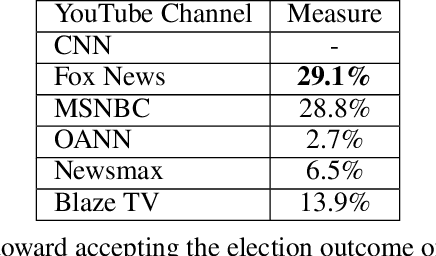

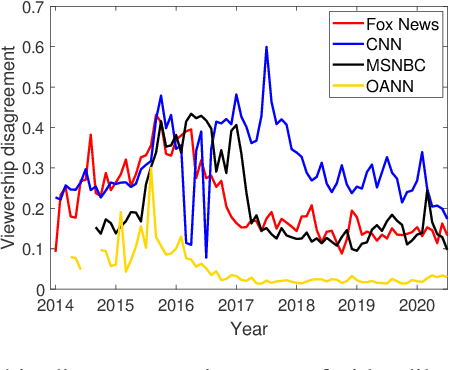
The growing political polarization of the American electorate over the last several decades has been widely studied and documented. During the administration of President Donald Trump, charges of "fake news" made social and news media not only the means but, to an unprecedented extent, the topic of political communication. Using data from before the November 3rd, 2020 US Presidential election, recent work has demonstrated the viability of using YouTube's social media ecosystem to obtain insights into the extent of US political polarization as well as the relationship between this polarization and the nature of the content and commentary provided by different US news networks. With that work as background, this paper looks at the sharp transformation of the relationship between news consumers and here-to-fore "fringe" news media channels in the 64 days between the US presidential election and the violence that took place at US Capitol on January 6th. This paper makes two distinct types of contributions. The first is to introduce a novel methodology to analyze large social media data to study the dynamics of social political news networks and their viewers. The second is to provide insights into what actually happened regarding US political social media channels and their viewerships during this volatile 64 day period.
Are Chess Discussions Racist? An Adversarial Hate Speech Data Set
Nov 20, 2020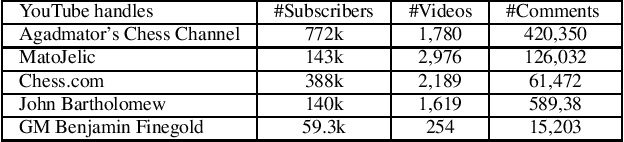


On June 28, 2020, while presenting a chess podcast on Grandmaster Hikaru Nakamura, Antonio Radi\'c's YouTube handle got blocked because it contained "harmful and dangerous" content. YouTube did not give further specific reason, and the channel got reinstated within 24 hours. However, Radi\'c speculated that given the current political situation, a referral to "black against white", albeit in the context of chess, earned him this temporary ban. In this paper, via a substantial corpus of 681,995 comments, on 8,818 YouTube videos hosted by five highly popular chess-focused YouTube channels, we ask the following research question: \emph{how robust are off-the-shelf hate-speech classifiers to out-of-domain adversarial examples?} We release a data set of 1,000 annotated comments where existing hate speech classifiers misclassified benign chess discussions as hate speech. We conclude with an intriguing analogy result on racial bias with our findings pointing out to the broader challenge of color polysemy.
We Don't Speak the Same Language: Interpreting Polarization through Machine Translation
Oct 18, 2020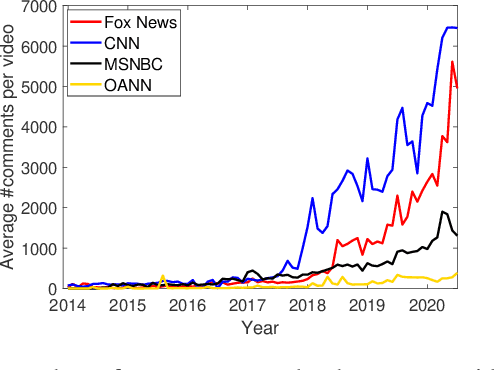
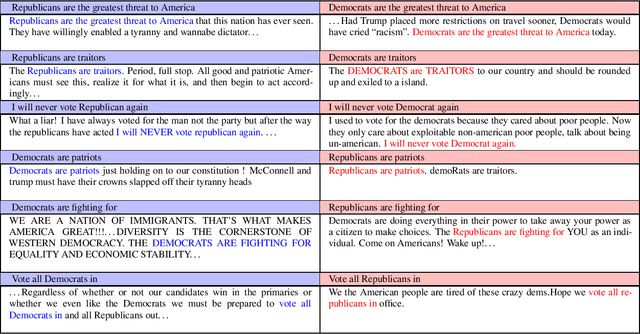

Polarization among US political parties, media and elites is a widely studied topic. Prominent lines of prior research across multiple disciplines have observed and analyzed growing polarization in social media. In this paper, we present a new methodology that offers a fresh perspective on interpreting polarization through the lens of machine translation. With a novel proposition that two sub-communities are speaking in two different \emph{languages}, we demonstrate that modern machine translation methods can provide a simple yet powerful and interpretable framework to understand the differences between two (or more) large-scale social media discussion data sets at the granularity of words. Via a substantial corpus of 86.6 million comments by 6.5 million users on over 200,000 news videos hosted by YouTube channels of four prominent US news networks, we demonstrate that simple word-level and phrase-level translation pairs can reveal deep insights into the current political divide -- what is \emph{black lives matter} to one can be \emph{all lives matter} to the other.
Social Media Attributions in the Context of Water Crisis
Jan 06, 2020

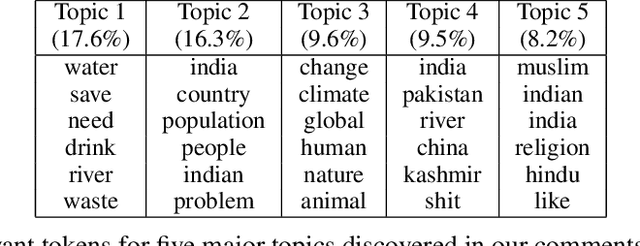
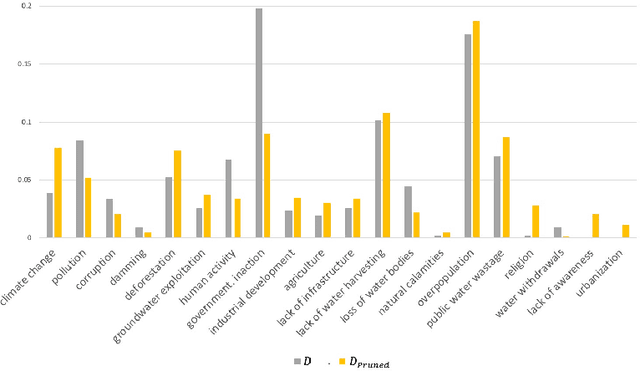
Attribution of natural disasters/collective misfortune is a widely-studied political science problem. However, such studies are typically survey-centric or rely on a handful of experts to weigh in on the matter. In this paper, we explore how can we use social media data and an AI-driven approach to complement traditional surveys and automatically extract attribution factors. We focus on the most-recent Chennai water crisis which started off as a regional issue but rapidly escalated into a discussion topic with global importance following alarming water-crisis statistics. Specifically, we present a novel prediction task of attribution tie detection which identifies the factors held responsible for the crisis (e.g., poor city planning, exploding population etc.). On a challenging data set constructed from YouTube comments (72,098 comments posted by 43,859 users on 623 relevant videos to the crisis), we present a neural classifier to extract attribution ties that achieved a reasonable performance (Accuracy: 81.34\% on attribution detection and 71.19\% on attribution resolution).