 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartPlay : A Benchmark for LLMs as Intelligent Agents
Oct 04, 2023



Recent large language models (LLMs) have demonstrated great potential toward intelligent agents and next-gen automation, but there currently lacks a systematic benchmark for evaluating LLMs' abilities as agents. We introduce SmartPlay: both a challenging benchmark and a methodology for evaluating LLMs as agents. SmartPlay consists of 6 different games, including Rock-Paper-Scissors, Tower of Hanoi, Minecraft. Each game features a unique setting, providing up to 20 evaluation settings and infinite environment variations. Each game in SmartPlay uniquely challenges a subset of 9 important capabilities of an intelligent LLM agent, including reasoning with object dependencies, planning ahead, spatial reasoning, learning from history, and understanding randomness. The distinction between the set of capabilities each game test allows us to analyze each capability separately. SmartPlay serves not only as a rigorous testing ground for evaluating the overall performance of LLM agents but also as a road-map for identifying gaps in current methodologies. We release our benchmark at github.com/microsoft/SmartPlay
The Roles of Symbols in Neural-based AI: They are Not What You Think!
Apr 26, 2023



We propose that symbols are first and foremost external communication tools used between intelligent agents that allow knowledge to be transferred in a more efficient and effective manner than having to experience the world directly. But, they are also used internally within an agent through a form of self-communication to help formulate, describe and justify subsymbolic patterns of neural activity that truly implement thinking. Symbols, and our languages that make use of them, not only allow us to explain our thinking to others and ourselves, but also provide beneficial constraints (inductive bias) on learning about the world. In this paper we present relevant insights from neuroscience and cognitive science, about how the human brain represents symbols and the concepts they refer to, and how today's artificial neural networks can do the same. We then present a novel neuro-symbolic hypothesis and a plausible architecture for intelligent agents that combines subsymbolic representations for symbols and concepts for learning and reasoning. Our hypothesis and associated architecture imply that symbols will remain critical to the future of intelligent systems NOT because they are the fundamental building blocks of thought, but because they are characterizations of subsymbolic processes that constitute thought.
Read and Reap the Rewards: Learning to Play Atari with the Help of Instruction Manuals
Feb 12, 2023High sample complexity has long been a challenge for RL. On the other hand, humans learn to perform tasks not only from interaction or demonstrations, but also by reading unstructured text documents, e.g., instruction manuals. Instruction manuals and wiki pages are among the most abundant data that could inform agents of valuable features and policies or task-specific environmental dynamics and reward structures. Therefore, we hypothesize that the ability to utilize human-written instruction manuals to assist learning policies for specific tasks should lead to a more efficient and better-performing agent. We propose the Read and Reward framework. Read and Reward speeds up RL algorithms on Atari games by reading manuals released by the Atari game developers. Our framework consists of a QA Extraction module that extracts and summarizes relevant information from the manual and a Reasoning module that evaluates object-agent interactions based on information from the manual. Auxiliary reward is then provided to a standard A2C RL agent, when interaction is detected. When assisted by our design, A2C improves on 4 games in the Atari environment with sparse rewards, and requires 1000x less training frames compared to the previous SOTA Agent 57 on Skiing, the hardest game in Atari.
Transferable Student Performance Modeling for Intelligent Tutoring Systems
Feb 08, 2022


Millions of learners worldwide are now using intelligent tutoring systems (ITSs). At their core, ITSs rely on machine learning algorithms to track each user's changing performance level over time to provide personalized instruction. Crucially, student performance models are trained using interaction sequence data of previous learners to analyse data generated by future learners. This induces a cold-start problem when a new course is introduced for which no training data is available. Here, we consider transfer learning techniques as a way to provide accurate performance predictions for new courses by leveraging log data from existing courses. We study two settings: (i) In the naive transfer setting, we propose course-agnostic performance models that can be applied to any course. (ii) In the inductive transfer setting, we tune pre-trained course-agnostic performance models to new courses using small-scale target course data (e.g., collected during a pilot study). We evaluate the proposed techniques using student interaction sequence data from 5 different mathematics courses containing data from over 47,000 students in a real world large-scale ITS. The course-agnostic models that use additional features provided by human domain experts (e.g, difficulty ratings for questions in the new course) but no student interaction training data for the new course, achieve prediction accuracy on par with standard BKT and PFA models that use training data from thousands of students in the new course. In the inductive setting our transfer learning approach yields more accurate predictions than conventional performance models when only limited student interaction training data (<100 students) is available to both.
Assessing the Knowledge State of Online Students -- New Data, New Approaches, Improved Accuracy
Sep 04, 2021
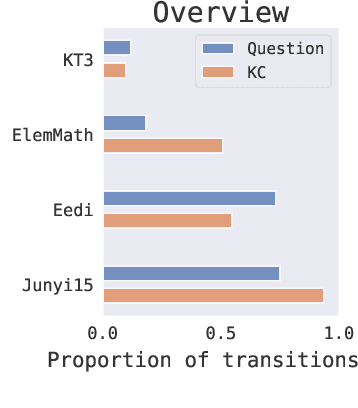
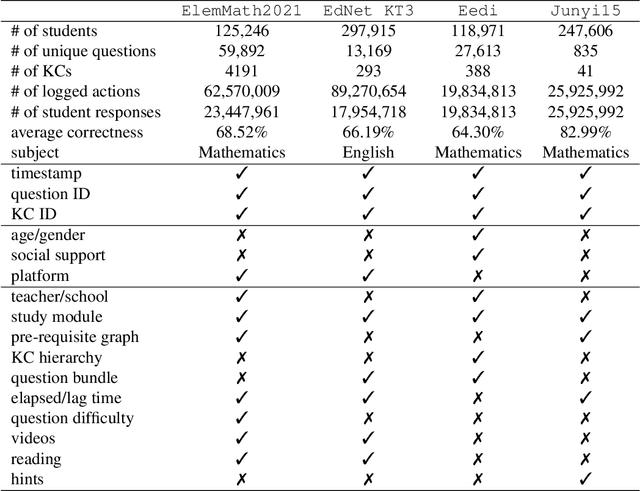
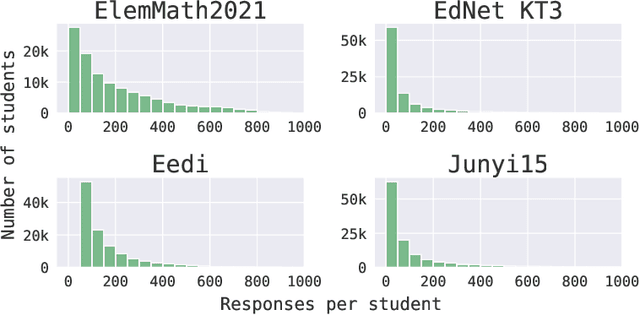
We consider the problem of assessing the changing knowledge state of individual students as they go through online courses. This student performance (SP) modeling problem, also known as knowledge tracing, is a critical step for building adaptive online teaching systems. Specifically, we conduct a study of how to utilize various types and large amounts of students log data to train accurate machine learning models that predict the knowledge state of future students. This study is the first to use four very large datasets made available recently from four distinct intelligent tutoring systems. Our results include a new machine learning approach that defines a new state of the art for SP modeling, improving over earlier methods in several ways: First, we achieve improved accuracy by introducing new features that can be easily computed from conventional question-response logs (e.g., the pattern in the student's most recent answers). Second, we take advantage of features of the student history that go beyond question-response pairs (e.g., which video segments the student watched, or skipped) as well as information about prerequisite structure in the curriculum. Third, we train multiple specialized modeling models for different aspects of the curriculum (e.g., specializing in early versus later segments of the student history), then combine these specialized models to create a group prediction of student knowledge. Taken together, these innovations yield an average AUC score across these four datasets of 0.807 compared to the previous best logistic regression approach score of 0.766, and also outperforming state-of-the-art deep neural net approaches. Importantly, we observe consistent improvements from each of our three methodological innovations, in each dataset, suggesting that our methods are of general utility and likely to produce improvements for other online tutoring systems as well.
Coarse-to-Fine Curriculum Learning
Jun 08, 2021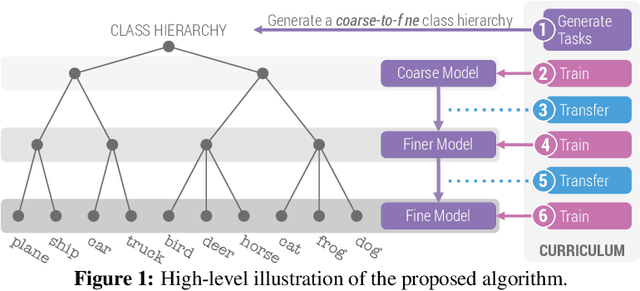

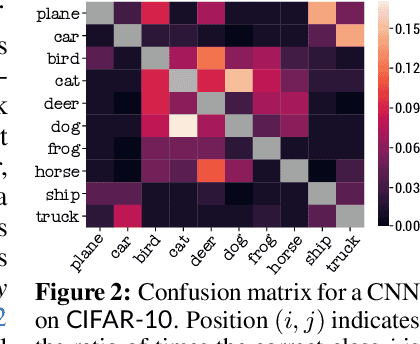
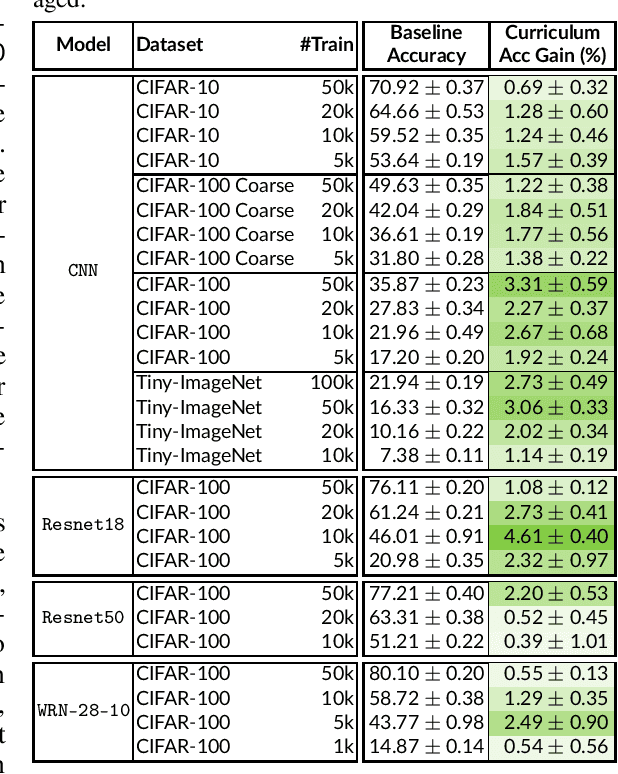
When faced with learning challenging new tasks, humans often follow sequences of steps that allow them to incrementally build up the necessary skills for performing these new tasks. However, in machine learning, models are most often trained to solve the target tasks directly.Inspired by human learning, we propose a novel curriculum learning approach which decomposes challenging tasks into sequences of easier intermediate goals that are used to pre-train a model before tackling the target task. We focus on classification tasks, and design the intermediate tasks using an automatically constructed label hierarchy. We train the model at each level of the hierarchy, from coarse labels to fine labels, transferring acquired knowledge across these levels. For instance, the model will first learn to distinguish animals from objects, and then use this acquired knowledge when learning to classify among more fine-grained classes such as cat, dog, car, and truck. Most existing curriculum learning algorithms for supervised learning consist of scheduling the order in which the training examples are presented to the model. In contrast, our approach focuses on the output space of the model. We evaluate our method on several established datasets and show significant performance gains especially on classification problems with many labels. We also evaluate on a new synthetic dataset which allows us to study multiple aspects of our method.
A Generative Symbolic Model for More General Natural Language Understanding and Reasoning
May 06, 2021

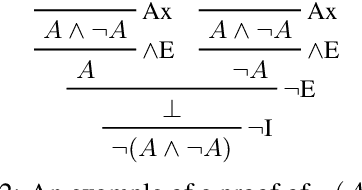

We present a new fully-symbolic Bayesian model of semantic parsing and reasoning which we hope to be the first step in a research program toward more domain- and task-general NLU and AI. Humans create internal mental models of their observations which greatly aid in their ability to understand and reason about a large variety of problems. We aim to capture this in our model, which is fully interpretable and Bayesian, designed specifically with generality in mind, and therefore provides a clearer path for future research to expand its capabilities. We derive and implement an inference algorithm, and evaluate it on an out-of-domain ProofWriter question-answering/reasoning task, achieving zero-shot accuracies of 100% and 93.43%, depending on the experimental setting, thereby demonstrating its value as a proof-of-concept.
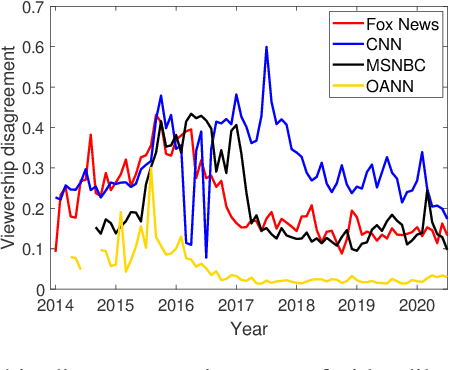
Fringe News Networks: Dynamics of US News Viewership following the 2020 Presidential Election
Jan 22, 2021
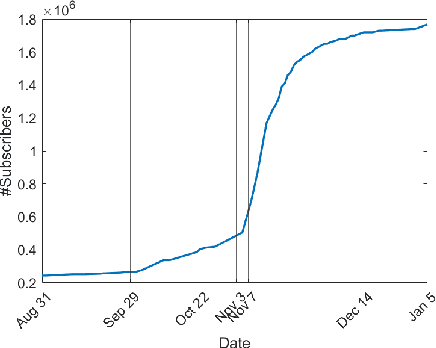
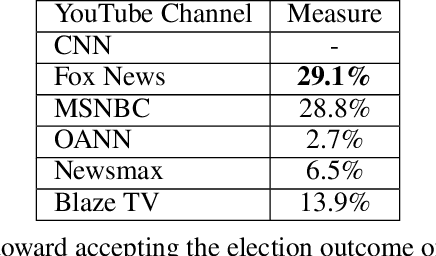

The growing political polarization of the American electorate over the last several decades has been widely studied and documented. During the administration of President Donald Trump, charges of "fake news" made social and news media not only the means but, to an unprecedented extent, the topic of political communication. Using data from before the November 3rd, 2020 US Presidential election, recent work has demonstrated the viability of using YouTube's social media ecosystem to obtain insights into the extent of US political polarization as well as the relationship between this polarization and the nature of the content and commentary provided by different US news networks. With that work as background, this paper looks at the sharp transformation of the relationship between news consumers and here-to-fore "fringe" news media channels in the 64 days between the US presidential election and the violence that took place at US Capitol on January 6th. This paper makes two distinct types of contributions. The first is to introduce a novel methodology to analyze large social media data to study the dynamics of social political news networks and their viewers. The second is to provide insights into what actually happened regarding US political social media channels and their viewerships during this volatile 64 day period.
We Don't Speak the Same Language: Interpreting Polarization through Machine Translation
Oct 18, 2020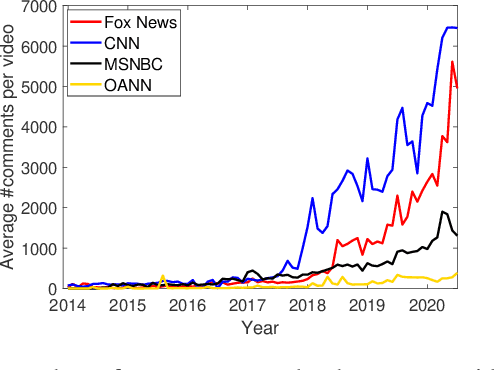
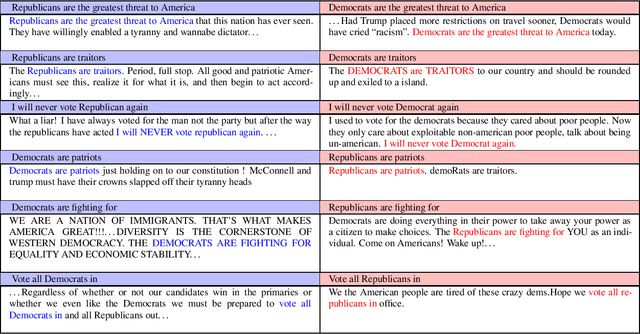

Polarization among US political parties, media and elites is a widely studied topic. Prominent lines of prior research across multiple disciplines have observed and analyzed growing polarization in social media. In this paper, we present a new methodology that offers a fresh perspective on interpreting polarization through the lens of machine translation. With a novel proposition that two sub-communities are speaking in two different \emph{languages}, we demonstrate that modern machine translation methods can provide a simple yet powerful and interpretable framework to understand the differences between two (or more) large-scale social media discussion data sets at the granularity of words. Via a substantial corpus of 86.6 million comments by 6.5 million users on over 200,000 news videos hosted by YouTube channels of four prominent US news networks, we demonstrate that simple word-level and phrase-level translation pairs can reveal deep insights into the current political divide -- what is \emph{black lives matter} to one can be \emph{all lives matter} to the other.
Modeling Task Effects on Meaning Representation in the Brain via Zero-Shot MEG Prediction
Sep 17, 2020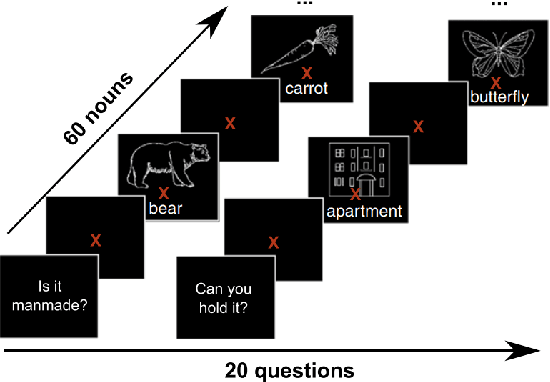

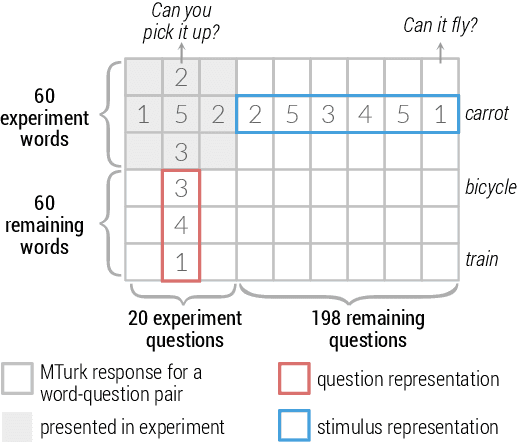
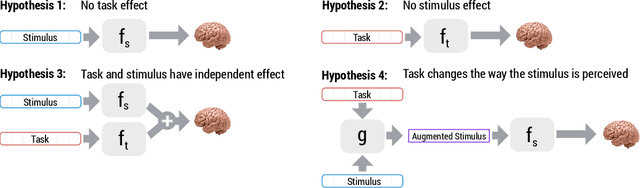
How meaning is represented in the brain is still one of the big open questions in neuroscience. Does a word (e.g., bird) always have the same representation, or does the task under which the word is processed alter its representation (answering "can you eat it?" versus "can it fly?")? The brain activity of subjects who read the same word while performing different semantic tasks has been shown to differ across tasks. However, it is still not understood how the task itself contributes to this difference. In the current work, we study Magnetoencephalography (MEG) brain recordings of participants tasked with answering questions about concrete nouns. We investigate the effect of the task (i.e. the question being asked) on the processing of the concrete noun by predicting the millisecond-resolution MEG recordings as a function of both the semantics of the noun and the task. Using this approach, we test several hypotheses about the task-stimulus interactions by comparing the zero-shot predictions made by these hypotheses for novel tasks and nouns not seen during training. We find that incorporating the task semantics significantly improves the prediction of MEG recordings, across participants. The improvement occurs 475-550ms after the participants first see the word, which corresponds to what is considered to be the ending time of semantic processing for a word. These results suggest that only the end of semantic processing of a word is task-dependent, and pose a challenge for future research to formulate new hypotheses for earlier task effects as a function of the task and stimuli.