 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Temporal Representation Learning with Nonstationary Sparse Transition
Sep 05, 2024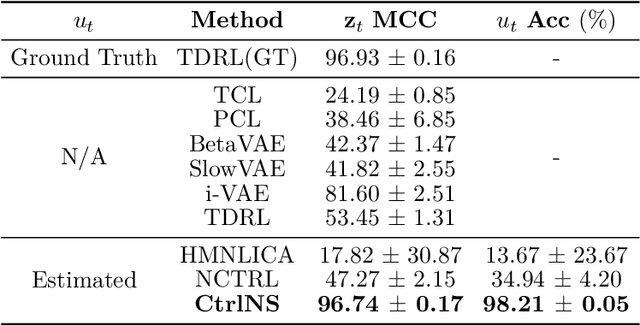
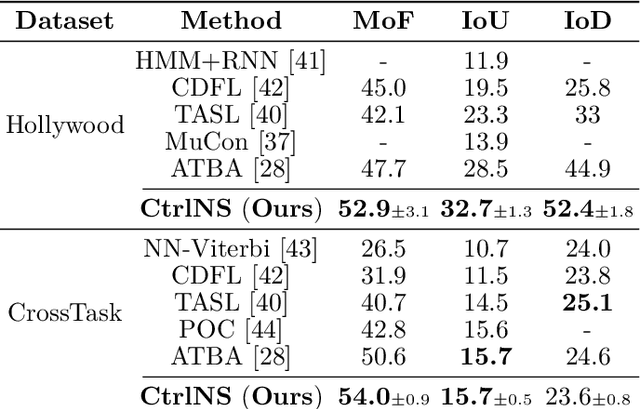
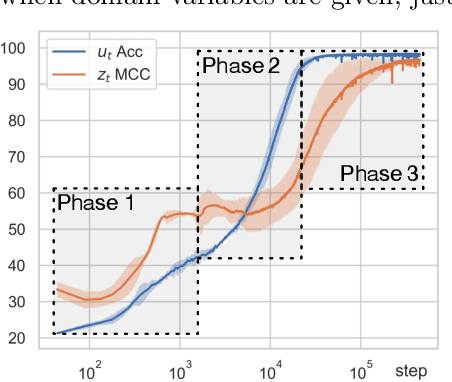

Causal Temporal Representation Learning (Ctrl) methods aim to identify the temporal causal dynamics of complex nonstationary temporal sequences. Despite the success of existing Ctrl methods, they require either directly observing the domain variables or assuming a Markov prior on them. Such requirements limit the application of these methods in real-world scenarios when we do not have such prior knowledge of the domain variables. To address this problem, this work adopts a sparse transition assumption, aligned with intuitive human understanding, and presents identifiability results from a theoretical perspective. In particular, we explore under what conditions on the significance of the variability of the transitions we can build a model to identify the distribution shifts. Based on the theoretical result, we introduce a novel framework, Causal Temporal Representation Learning with Nonstationary Sparse Transition (CtrlNS), designed to leverage the constraints on transition sparsity and conditional independence to reliably identify both distribution shifts and latent factors. Our experimental evaluations on synthetic and real-world datasets demonstrate significant improvements over existing baselines, highlighting the effectiveness of our approach.
AgentKit: Flow Engineering with Graphs, not Coding
Apr 17, 2024



We propose an intuitive LLM prompting framework (AgentKit) for multifunctional agents. AgentKit offers a unified framework for explicitly constructing a complex "thought process" from simple natural language prompts. The basic building block in AgentKit is a node, containing a natural language prompt for a specific subtask. The user then puts together chains of nodes, like stacking LEGO pieces. The chains of nodes can be designed to explicitly enforce a naturally structured "thought process". For example, for the task of writing a paper, one may start with the thought process of 1) identify a core message, 2) identify prior research gaps, etc. The nodes in AgentKit can be designed and combined in different ways to implement multiple advanced capabilities including on-the-fly hierarchical planning, reflection, and learning from interactions. In addition, due to the modular nature and the intuitive design to simulate explicit human thought process, a basic agent could be implemented as simple as a list of prompts for the subtasks and therefore could be designed and tuned by someone without any programming experience. Quantitatively, we show that agents designed through AgentKit achieve SOTA performance on WebShop and Crafter. These advances underscore AgentKit's potential in making LLM agents effective and accessible for a wider range of applications. https://github.com/holmeswww/AgentKit
Calibration-then-Calculation: A Variance Reduced Metric Framework in Deep Click-Through Rate Prediction Models
Jan 30, 2024



Deep learning has been widely adopted across various fields, but there has been little focus on evaluating the performance of deep learning pipelines. With the increased use of large datasets and complex models, it has become common to run the training process only once and compare the result to previous benchmarks. However, this procedure can lead to imprecise comparisons due to the variance in neural network evaluation metrics. The metric variance comes from the randomness inherent in the training process of deep learning pipelines. Traditional solutions such as running the training process multiple times are usually not feasible in deep learning due to computational limitations. In this paper, we propose a new metric framework, Calibrated Loss Metric, that addresses this issue by reducing the variance in its vanilla counterpart. As a result, the new metric has a higher accuracy to detect effective modeling improvement. Our approach is supported by theoretical justifications and extensive experimental validations in the context of Deep Click-Through Rate Prediction Models.
On the Three Demons in Causality in Finance: Time Resolution, Nonstationarity, and Latent Factors
Jan 12, 2024



Financial data is generally time series in essence and thus suffers from three fundamental issues: the mismatch in time resolution, the time-varying property of the distribution - nonstationarity, and causal factors that are important but unknown/unobserved. In this paper, we follow a causal perspective to systematically look into these three demons in finance. Specifically, we reexamine these issues in the context of causality, which gives rise to a novel and inspiring understanding of how the issues can be addressed. Following this perspective, we provide systematic solutions to these problems, which hopefully would serve as a foundation for future research in the area.
Temporally Disentangled Representation Learning under Unknown Nonstationarity
Oct 28, 2023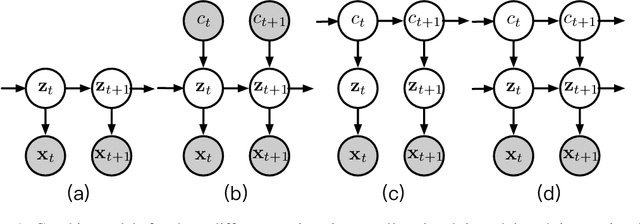
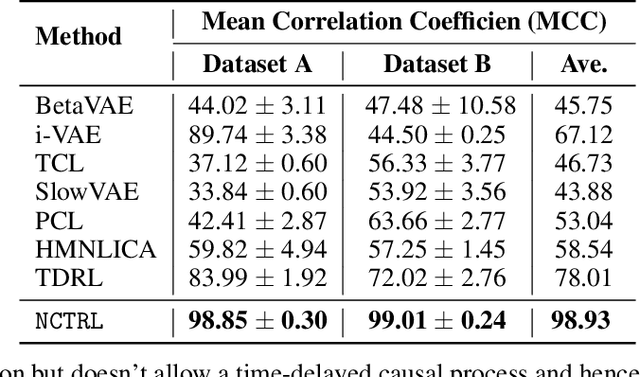
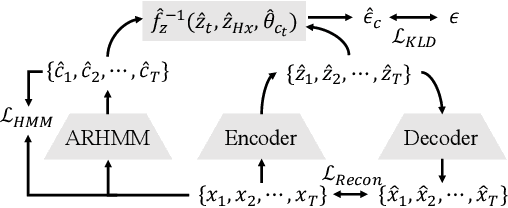

In unsupervised causal representation learning for sequential data with time-delayed latent causal influences, strong identifiability results for the disentanglement of causally-related latent variables have been established in stationary settings by leveraging temporal structure. However, in nonstationary setting, existing work only partially addressed the problem by either utilizing observed auxiliary variables (e.g., class labels and/or domain indexes) as side information or assuming simplified latent causal dynamics. Both constrain the method to a limited range of scenarios. In this study, we further explored the Markov Assumption under time-delayed causally related process in nonstationary setting and showed that under mild conditions, the independent latent components can be recovered from their nonlinear mixture up to a permutation and a component-wise transformation, without the observation of auxiliary variables. We then introduce NCTRL, a principled estimation framework, to reconstruct time-delayed latent causal variables and identify their relations from measured sequential data only. Empirical evaluations demonstrated the reliable identification of time-delayed latent causal influences, with our methodology substantially outperforming existing baselines that fail to exploit the nonstationarity adequately and then, consequently, cannot distinguish distribution shifts.
Generalized Precision Matrix for Scalable Estimation of Nonparametric Markov Networks
May 19, 2023A Markov network characterizes the conditional independence structure, or Markov property, among a set of random variables. Existing work focuses on specific families of distributions (e.g., exponential families) and/or certain structures of graphs, and most of them can only handle variables of a single data type (continuous or discrete). In this work, we characterize the conditional independence structure in general distributions for all data types (i.e., continuous, discrete, and mixed-type) with a Generalized Precision Matrix (GPM). Besides, we also allow general functional relations among variables, thus giving rise to a Markov network structure learning algorithm in one of the most general settings. To deal with the computational challenge of the problem, especially for large graphs, we unify all cases under the same umbrella of a regularized score matching framework. We validate the theoretical results and demonstrate the scalability empirically in various settings.
Read and Reap the Rewards: Learning to Play Atari with the Help of Instruction Manuals
Feb 12, 2023High sample complexity has long been a challenge for RL. On the other hand, humans learn to perform tasks not only from interaction or demonstrations, but also by reading unstructured text documents, e.g., instruction manuals. Instruction manuals and wiki pages are among the most abundant data that could inform agents of valuable features and policies or task-specific environmental dynamics and reward structures. Therefore, we hypothesize that the ability to utilize human-written instruction manuals to assist learning policies for specific tasks should lead to a more efficient and better-performing agent. We propose the Read and Reward framework. Read and Reward speeds up RL algorithms on Atari games by reading manuals released by the Atari game developers. Our framework consists of a QA Extraction module that extracts and summarizes relevant information from the manual and a Reasoning module that evaluates object-agent interactions based on information from the manual. Auxiliary reward is then provided to a standard A2C RL agent, when interaction is detected. When assisted by our design, A2C improves on 4 games in the Atari environment with sparse rewards, and requires 1000x less training frames compared to the previous SOTA Agent 57 on Skiing, the hardest game in Atari.
Calibration Matters: Tackling Maximization Bias in Large-scale Advertising Recommendation Systems
May 19, 2022
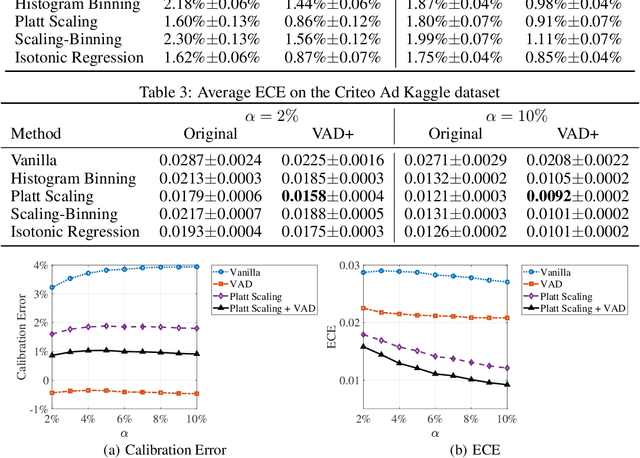
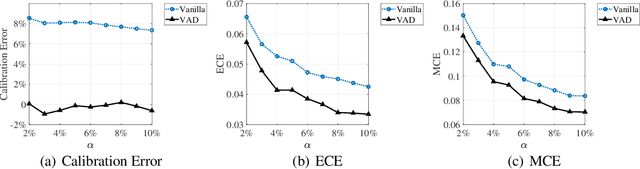
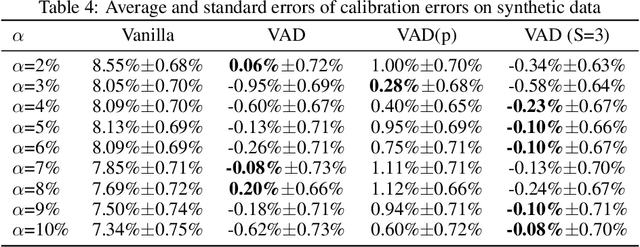
Calibration is defined as the ratio of the average predicted click rate to the true click rate. The optimization of calibration is essential to many online advertising recommendation systems because it directly affects the downstream bids in ads auctions and the amount of money charged to advertisers. Despite its importance, calibration optimization often suffers from a problem called "maximization bias". Maximization bias refers to the phenomenon that the maximum of predicted values overestimates the true maximum. The problem is introduced because the calibration is computed on the set selected by the prediction model itself. It persists even if unbiased predictions can be achieved on every datapoint and worsens when covariate shifts exist between the training and test sets. To mitigate this problem, we theorize the quantification of maximization bias and propose a variance-adjusting debiasing (VAD) meta-algorithm in this paper. The algorithm is efficient, robust, and practical as it is able to mitigate maximization bias problems under covariate shifts, neither incurring additional online serving costs nor compromising the ranking performance. We demonstrate the effectiveness of the proposed algorithm using a state-of-the-art recommendation neural network model on a large-scale real-world dataset.