 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Generalist to Specialist Representation
May 12, 2026Given a generalist model, learning a task-relevant specialist representation is fundamental for downstream applications. Identifiability, the asymptotic guarantee of recovering the ground-truth representation, is critical because it sets the ultimate limit of any model, even with infinite data and computation. We study this problem in a completely nonparametric setting, without relying on interventions, parametric forms, or structural constraints. We first prove that the structure between time steps and tasks is identifiable in a fully unsupervised manner, even when sequences lack strict temporal dependence and may exhibit disconnections, and task assignments can follow arbitrarily complex and interleaving structures. We then prove that, within each time step, the task-relevant latent representation can be disentangled from the irrelevant part under a simple sparsity regularization, without any additional information or parametric constraints. Together, these results establish a hierarchical foundation: task structure is identifiable across time steps, and task-relevant latent representations are identifiable within each step. To our knowledge, each result provides a first general nonparametric identifiability guarantee, and together they mark a step toward provably moving from generalist to specialist models.
A General Representation-Based Approach to Multi-Source Domain Adaptation
Apr 26, 2026A central problem in unsupervised domain adaptation is determining what to transfer from labeled source domains to an unlabeled target domain. To handle high-dimensional observations (e.g., images), a line of approaches use deep learning to learn latent representations of the observations, which facilitate knowledge transfer in the latent space. However, existing approaches often rely on restrictive assumptions to establish identifiability of the joint distribution in the target domain, such as independent latent variables or invariant label distributions, limiting their real-world applicability. In this work, we propose a general domain adaptation framework that learns compact latent representations to capture distribution shifts relative to the prediction task and address the fundamental question of what representations should be learned and transferred. Notably, we first demonstrate that learning representations based on all the predictive information, i.e., the label's Markov blanket in terms of the learned representations, is often underspecified in general settings. Instead, we show that, interestingly, general domain adaptation can be achieved by partitioning the representations of Markov blanket into those of the label's parents, children, and spouses. Moreover, its identifiability guarantee can be established. Building on these theoretical insights, we develop a practical, nonparametric approach for domain adaptation in a general setting, which can handle different types of distribution shifts.
Diverse Dictionary Learning
Apr 19, 2026Given only observational data $X = g(Z)$, where both the latent variables $Z$ and the generating process $g$ are unknown, recovering $Z$ is ill-posed without additional assumptions. Existing methods often assume linearity or rely on auxiliary supervision and functional constraints. However, such assumptions are rarely verifiable in practice, and most theoretical guarantees break down under even mild violations, leaving uncertainty about how to reliably understand the hidden world. To make identifiability actionable in the real-world scenarios, we take a complementary view: in the general settings where full identifiability is unattainable, what can still be recovered with guarantees, and what biases could be universally adopted? We introduce the problem of diverse dictionary learning to formalize this view. Specifically, we show that intersections, complements, and symmetric differences of latent variables linked to arbitrary observations, along with the latent-to-observed dependency structure, are still identifiable up to appropriate indeterminacies even without strong assumptions. These set-theoretic results can be composed using set algebra to construct structured and essential views of the hidden world, such as genus-differentia definitions. When sufficient structural diversity is present, they further imply full identifiability of all latent variables. Notably, all identifiability benefits follow from a simple inductive bias during estimation that can be readily integrated into most models. We validate the theory and demonstrate the benefits of the bias on both synthetic and real-world data.
ParamMem: Augmenting Language Agents with Parametric Reflective Memory
Feb 26, 2026Self-reflection enables language agents to iteratively refine solutions, yet often produces repetitive outputs that limit reasoning performance. Recent studies have attempted to address this limitation through various approaches, among which increasing reflective diversity has shown promise. Our empirical analysis reveals a strong positive correlation between reflective diversity and task success, further motivating the need for diverse reflection signals. We introduce ParamMem, a parametric memory module that encodes cross-sample reflection patterns into model parameters, enabling diverse reflection generation through temperature-controlled sampling. Building on this module, we propose ParamAgent, a reflection-based agent framework that integrates parametric memory with episodic and cross-sample memory. Extensive experiments on code generation, mathematical reasoning, and multi-hop question answering demonstrate consistent improvements over state-of-the-art baselines. Further analysis reveals that ParamMem is sample-efficient, enables weak-to-strong transfer across model scales, and supports self-improvement without reliance on stronger external model, highlighting the potential of ParamMem as an effective component for enhancing language agents.
Emerging from Ground: Addressing Intent Deviation in Tool-Using Agents via Deriving Real Calls into Virtual Trajectories
Jan 21, 2026LLMs have advanced tool-using agents for real-world applications, yet they often lead to unexpected behaviors or results. Beyond obvious failures, the subtle issue of "intent deviation" severely hinders reliable evaluation and performance improvement. Existing post-training methods generally leverage either real system samples or virtual data simulated by LLMs. However, the former is costly due to reliance on hand-crafted user requests, while the latter suffers from distribution shift from the real tools in the wild. Additionally, both methods lack negative samples tailored to intent deviation scenarios, hindering effective guidance on preference learning. We introduce RISE, a "Real-to-Virtual" method designed to mitigate intent deviation. Anchoring on verified tool primitives, RISE synthesizes virtual trajectories and generates diverse negative samples through mutation on critical parameters. With synthetic data, RISE fine-tunes backbone LLMs via the two-stage training for intent alignment. Evaluation results demonstrate that data synthesized by RISE achieve promising results in eight metrics covering user requires, execution trajectories and agent responses. Integrating with training, RISE achieves an average 35.28% improvement in Acctask (task completion) and 23.27% in Accintent (intent alignment), outperforming SOTA baselines by 1.20--42.09% and 1.17--54.93% respectively.
Higher-Order Causal Structure Learning with Additive Models
Nov 05, 2025Causal structure learning has long been the central task of inferring causal insights from data. Despite the abundance of real-world processes exhibiting higher-order mechanisms, however, an explicit treatment of interactions in causal discovery has received little attention. In this work, we focus on extending the causal additive model (CAM) to additive models with higher-order interactions. This second level of modularity we introduce to the structure learning problem is most easily represented by a directed acyclic hypergraph which extends the DAG. We introduce the necessary definitions and theoretical tools to handle the novel structure we introduce and then provide identifiability results for the hyper DAG, extending the typical Markov equivalence classes. We next provide insights into why learning the more complex hypergraph structure may actually lead to better empirical results. In particular, more restrictive assumptions like CAM correspond to easier-to-learn hyper DAGs and better finite sample complexity. We finally develop an extension of the greedy CAM algorithm which can handle the more complex hyper DAG search space and demonstrate its empirical usefulness in synthetic experiments.
Thought Communication in Multiagent Collaboration
Oct 23, 2025Natural language has long enabled human cooperation, but its lossy, ambiguous, and indirect nature limits the potential of collective intelligence. While machines are not subject to these constraints, most LLM-based multi-agent systems still rely solely on natural language, exchanging tokens or their embeddings. To go beyond language, we introduce a new paradigm, thought communication, which enables agents to interact directly mind-to-mind, akin to telepathy. To uncover these latent thoughts in a principled way, we formalize the process as a general latent variable model, where agent states are generated by an unknown function of underlying thoughts. We prove that, in a nonparametric setting without auxiliary information, both shared and private latent thoughts between any pair of agents can be identified. Moreover, the global structure of thought sharing, including which agents share which thoughts and how these relationships are structured, can also be recovered with theoretical guarantees. Guided by the established theory, we develop a framework that extracts latent thoughts from all agents prior to communication and assigns each agent the relevant thoughts, along with their sharing patterns. This paradigm naturally extends beyond LLMs to all modalities, as most observational data arise from hidden generative processes. Experiments on both synthetic and real-world benchmarks validate the theory and demonstrate the collaborative advantages of thought communication. We hope this work illuminates the potential of leveraging the hidden world, as many challenges remain unsolvable through surface-level observation alone, regardless of compute or data scale.
A Survey of Vibe Coding with Large Language Models
Oct 14, 2025The advancement of large language models (LLMs) has catalyzed a paradigm shift from code generation assistance to autonomous coding agents, enabling a novel development methodology termed "Vibe Coding" where developers validate AI-generated implementations through outcome observation rather than line-by-line code comprehension. Despite its transformative potential, the effectiveness of this emergent paradigm remains under-explored, with empirical evidence revealing unexpected productivity losses and fundamental challenges in human-AI collaboration. To address this gap, this survey provides the first comprehensive and systematic review of Vibe Coding with large language models, establishing both theoretical foundations and practical frameworks for this transformative development approach. Drawing from systematic analysis of over 1000 research papers, we survey the entire vibe coding ecosystem, examining critical infrastructure components including LLMs for coding, LLM-based coding agent, development environment of coding agent, and feedback mechanisms. We first introduce Vibe Coding as a formal discipline by formalizing it through a Constrained Markov Decision Process that captures the dynamic triadic relationship among human developers, software projects, and coding agents. Building upon this theoretical foundation, we then synthesize existing practices into five distinct development models: Unconstrained Automation, Iterative Conversational Collaboration, Planning-Driven, Test-Driven, and Context-Enhanced Models, thus providing the first comprehensive taxonomy in this domain. Critically, our analysis reveals that successful Vibe Coding depends not merely on agent capabilities but on systematic context engineering, well-established development environments, and human-agent collaborative development models.
SmartCLIP: Modular Vision-language Alignment with Identification Guarantees
Jul 29, 2025
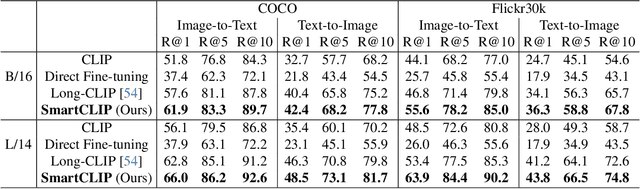
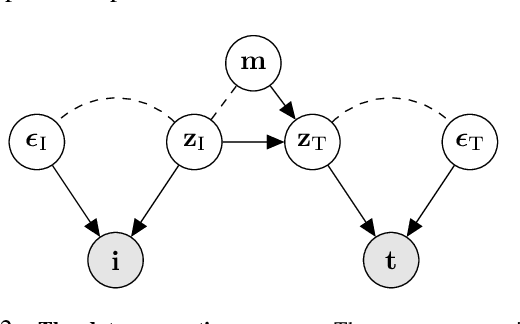
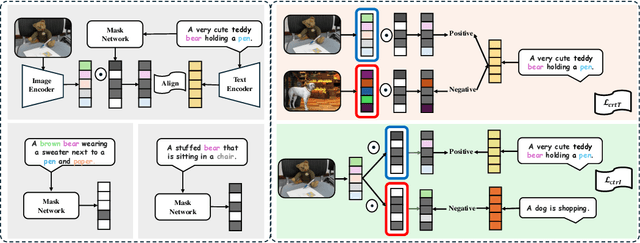
Contrastive Language-Image Pre-training (CLIP)~\citep{radford2021learning} has emerged as a pivotal model in computer vision and multimodal learning, achieving state-of-the-art performance at aligning visual and textual representations through contrastive learning. However, CLIP struggles with potential information misalignment in many image-text datasets and suffers from entangled representation. On the one hand, short captions for a single image in datasets like MSCOCO may describe disjoint regions in the image, leaving the model uncertain about which visual features to retain or disregard. On the other hand, directly aligning long captions with images can lead to the retention of entangled details, preventing the model from learning disentangled, atomic concepts -- ultimately limiting its generalization on certain downstream tasks involving short prompts. In this paper, we establish theoretical conditions that enable flexible alignment between textual and visual representations across varying levels of granularity. Specifically, our framework ensures that a model can not only \emph{preserve} cross-modal semantic information in its entirety but also \emph{disentangle} visual representations to capture fine-grained textual concepts. Building on this foundation, we introduce \ours, a novel approach that identifies and aligns the most relevant visual and textual representations in a modular manner. Superior performance across various tasks demonstrates its capability to handle information misalignment and supports our identification theory. The code is available at https://github.com/Mid-Push/SmartCLIP.
Position: Mechanistic Interpretability Should Prioritize Feature Consistency in SAEs
May 26, 2025Sparse Autoencoders (SAEs) are a prominent tool in mechanistic interpretability (MI) for decomposing neural network activations into interpretable features. However, the aspiration to identify a canonical set of features is challenged by the observed inconsistency of learned SAE features across different training runs, undermining the reliability and efficiency of MI research. This position paper argues that mechanistic interpretability should prioritize feature consistency in SAEs -- the reliable convergence to equivalent feature sets across independent runs. We propose using the Pairwise Dictionary Mean Correlation Coefficient (PW-MCC) as a practical metric to operationalize consistency and demonstrate that high levels are achievable (0.80 for TopK SAEs on LLM activations) with appropriate architectural choices. Our contributions include detailing the benefits of prioritizing consistency; providing theoretical grounding and synthetic validation using a model organism, which verifies PW-MCC as a reliable proxy for ground-truth recovery; and extending these findings to real-world LLM data, where high feature consistency strongly correlates with the semantic similarity of learned feature explanations. We call for a community-wide shift towards systematically measuring feature consistency to foster robust cumulative progress in MI.