 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloud Atlas: Efficient Fault Localization for Cloud Systems using Language Models and Causal Insight
Jul 11, 2024Runtime failure and performance degradation is commonplace in modern cloud systems. For cloud providers, automatically determining the root cause of incidents is paramount to ensuring high reliability and availability as prompt fault localization can enable faster diagnosis and triage for timely resolution. A compelling solution explored in recent work is causal reasoning using causal graphs to capture relationships between varied cloud system performance metrics. To be effective, however, systems developers must correctly define the causal graph of their system, which is a time-consuming, brittle, and challenging task that increases in difficulty for large and dynamic systems and requires domain expertise. Alternatively, automated data-driven approaches have limited efficacy for cloud systems due to the inherent rarity of incidents. In this work, we present Atlas, a novel approach to automatically synthesizing causal graphs for cloud systems. Atlas leverages large language models (LLMs) to generate causal graphs using system documentation, telemetry, and deployment feedback. Atlas is complementary to data-driven causal discovery techniques, and we further enhance Atlas with a data-driven validation step. We evaluate Atlas across a range of fault localization scenarios and demonstrate that Atlas is capable of generating causal graphs in a scalable and generalizable manner, with performance that far surpasses that of data-driven algorithms and is commensurate to the ground-truth baseline.
Automatic Code Generation using Pre-Trained Language Models
Feb 21, 2021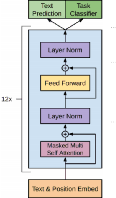
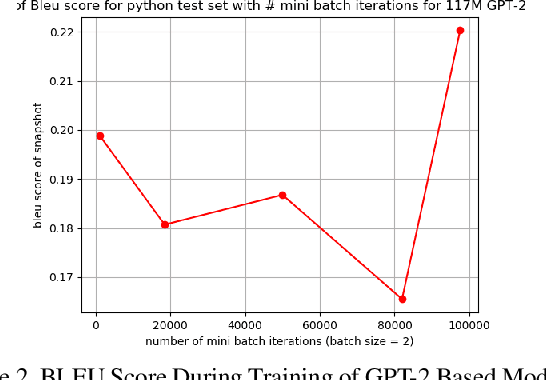
Recent advancements in natural language processing \cite{gpt2} \cite{BERT} have led to near-human performance in multiple natural language tasks. In this paper, we seek to understand whether similar techniques can be applied to a highly structured environment with strict syntax rules. Specifically, we propose an end-to-end machine learning model for code generation in the Python language built on-top of pre-trained language models. We demonstrate that a fine-tuned model can perform well in code generation tasks, achieving a BLEU score of 0.22, an improvement of 46\% over a reasonable sequence-to-sequence baseline. All results and related code used for training and data processing are available on GitHub.