 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETA Prediction with Graph Neural Networks in Google Maps
Aug 25, 2021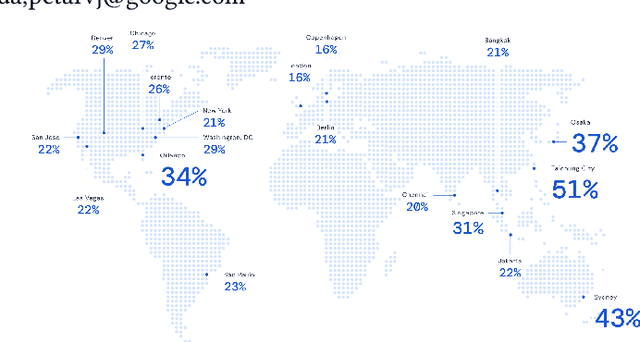


Travel-time prediction constitutes a task of high importance in transportation networks, with web mapping services like Google Maps regularly serving vast quantities of travel time queries from users and enterprises alike. Further, such a task requires accounting for complex spatiotemporal interactions (modelling both the topological properties of the road network and anticipating events -- such as rush hours -- that may occur in the future). Hence, it is an ideal target for graph representation learning at scale. Here we present a graph neural network estimator for estimated time of arrival (ETA) which we have deployed in production at Google Maps. While our main architecture consists of standard GNN building blocks, we further detail the usage of training schedule methods such as MetaGradients in order to make our model robust and production-ready. We also provide prescriptive studies: ablating on various architectural decisions and training regimes, and qualitative analyses on real-world situations where our model provides a competitive edge. Our GNN proved powerful when deployed, significantly reducing negative ETA outcomes in several regions compared to the previous production baseline (40+% in cities like Sydney).
Mastering Terra Mystica: Applying Self-Play to Multi-agent Cooperative Board Games
Feb 21, 2021
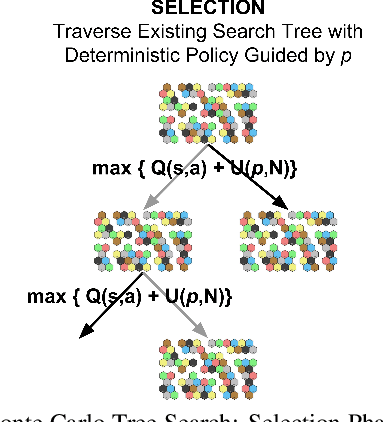


In this paper, we explore and compare multiple algorithms for solving the complex strategy game of Terra Mystica, hereafter abbreviated as TM. Previous work in the area of super-human game-play using AI has proven effective, with recent break-through for generic algorithms in games such as Go, Chess, and Shogi \cite{AlphaZero}. We directly apply these breakthroughs to a novel state-representation of TM with the goal of creating an AI that will rival human players. Specifically, we present the initial results of applying AlphaZero to this state-representation and analyze the strategies developed. A brief analysis is presented. We call this modified algorithm with our novel state-representation AlphaTM. In the end, we discuss the success and shortcomings of this method by comparing against multiple baselines and typical human scores. All code used for this paper is available at on \href{https://github.com/kandluis/terrazero}{GitHub}.
Automatic Code Generation using Pre-Trained Language Models
Feb 21, 2021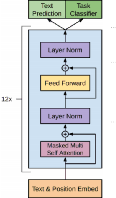
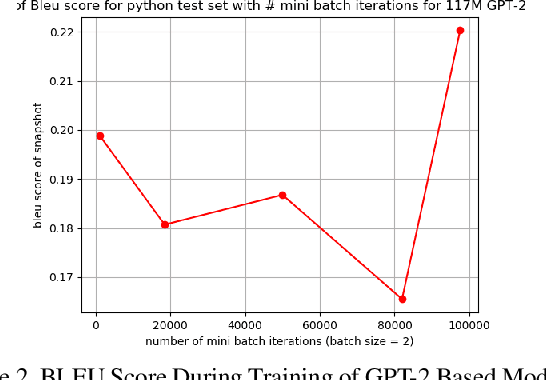
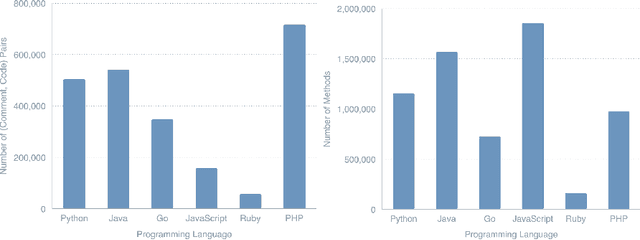
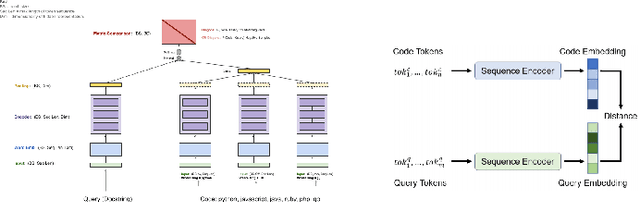
Recent advancements in natural language processing \cite{gpt2} \cite{BERT} have led to near-human performance in multiple natural language tasks. In this paper, we seek to understand whether similar techniques can be applied to a highly structured environment with strict syntax rules. Specifically, we propose an end-to-end machine learning model for code generation in the Python language built on-top of pre-trained language models. We demonstrate that a fine-tuned model can perform well in code generation tasks, achieving a BLEU score of 0.22, an improvement of 46\% over a reasonable sequence-to-sequence baseline. All results and related code used for training and data processing are available on GitHub.
The Effectiveness of Data Augmentation in Image Classification using Deep Learning
Dec 13, 2017
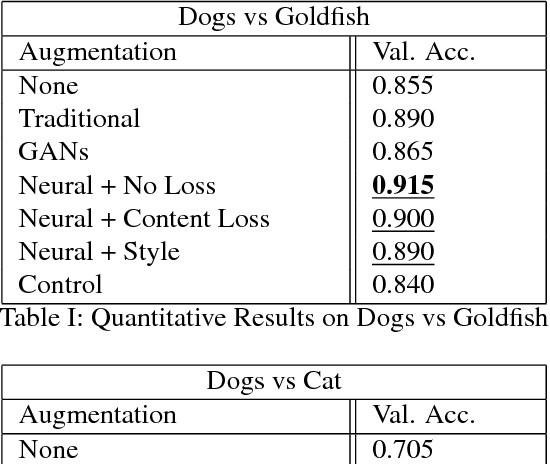

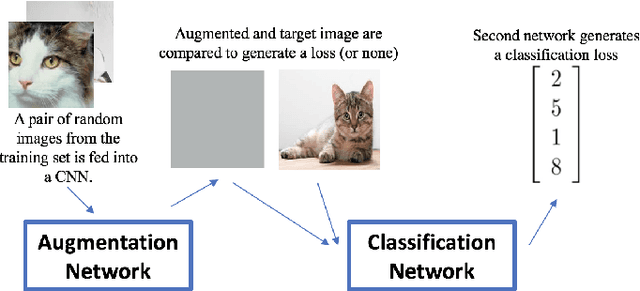
In this paper, we explore and compare multiple solutions to the problem of data augmentation in image classification. Previous work has demonstrated the effectiveness of data augmentation through simple techniques, such as cropping, rotating, and flipping input images. We artificially constrain our access to data to a small subset of the ImageNet dataset, and compare each data augmentation technique in turn. One of the more successful data augmentations strategies is the traditional transformations mentioned above. We also experiment with GANs to generate images of different styles. Finally, we propose a method to allow a neural net to learn augmentations that best improve the classifier, which we call neural augmentation. We discuss the successes and shortcomings of this method on various datasets.
Predicting Yelp Star Reviews Based on Network Structure with Deep Learning
Dec 11, 2017
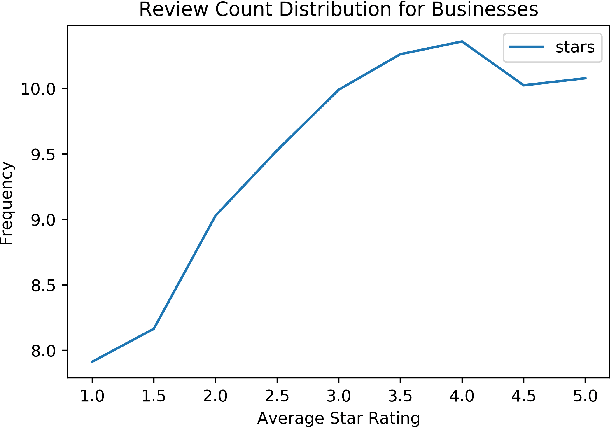

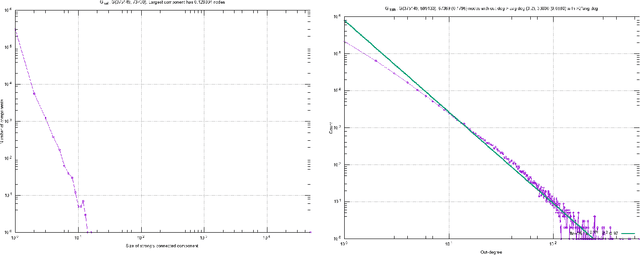
In this paper, we tackle the real-world problem of predicting Yelp star-review rating based on business features (such as images, descriptions), user features (average previous ratings), and, of particular interest, network properties (which businesses has a user rated before). We compare multiple models on different sets of features -- from simple linear regression on network features only to deep learning models on network and item features. In recent years, breakthroughs in deep learning have led to increased accuracy in common supervised learning tasks, such as image classification, captioning, and language understanding. However, the idea of combining deep learning with network feature and structure appears to be novel. While the problem of predicting future interactions in a network has been studied at length, these approaches have often ignored either node-specific data or global structure. We demonstrate that taking a mixed approach combining both node-level features and network information can effectively be used to predict Yelp-review star ratings. We evaluate on the Yelp dataset by splitting our data along the time dimension (as would naturally occur in the real-world) and comparing our model against others which do no take advantage of the network structure and/or deep learning.