 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Pipeline Using Synthetic Data to Improve Interpretation of Paper ECG Images
Jul 29, 2025Cardiovascular diseases (CVDs) are the leading global cause of death, and early detection is essential to improve patient outcomes. Electrocardiograms (ECGs), especially 12-lead ECGs, play a key role in the identification of CVDs. These are routinely interpreted by human experts, a process that is time-consuming and requires expert knowledge. Historical research in this area has focused on automatic ECG interpretation from digital signals, with recent deep learning approaches achieving strong results. In practice, however, most ECG data in clinical practice are stored or shared in image form. To bridge this gap, we propose a deep learning framework designed specifically to classify paper-like ECG images into five main diagnostic categories. Our method was the winning entry to the 2024 British Heart Foundation Open Data Science Challenge. It addresses two main challenges of paper ECG classification: visual noise (e.g., shadows or creases) and the need to detect fine-detailed waveform patterns. We propose a pre-processing pipeline that reduces visual noise and a two-stage fine-tuning strategy: the model is first fine-tuned on synthetic and external ECG image datasets to learn domain-specific features, and then further fine-tuned on the target dataset to enhance disease-specific recognition. We adopt the ConvNeXt architecture as the backbone of our model. Our method achieved AUROC scores of 0.9688 on the public validation set and 0.9677 on the private test set of the British Heart Foundation Open Data Science Challenge, highlighting its potential as a practical tool for automated ECG interpretation in clinical workflows.
Eyes Tell the Truth: GazeVal Highlights Shortcomings of Generative AI in Medical Imaging
Mar 26, 2025



The demand for high-quality synthetic data for model training and augmentation has never been greater in medical imaging. However, current evaluations predominantly rely on computational metrics that fail to align with human expert recognition. This leads to synthetic images that may appear realistic numerically but lack clinical authenticity, posing significant challenges in ensuring the reliability and effectiveness of AI-driven medical tools. To address this gap, we introduce GazeVal, a practical framework that synergizes expert eye-tracking data with direct radiological evaluations to assess the quality of synthetic medical images. GazeVal leverages gaze patterns of radiologists as they provide a deeper understanding of how experts perceive and interact with synthetic data in different tasks (i.e., diagnostic or Turing tests). Experiments with sixteen radiologists revealed that 96.6% of the generated images (by the most recent state-of-the-art AI algorithm) were identified as fake, demonstrating the limitations of generative AI in producing clinically accurate images.
Flexible framework for generating synthetic electrocardiograms and photoplethysmograms
Aug 29, 2024



By generating synthetic biosignals, the quantity and variety of health data can be increased. This is especially useful when training machine learning models by enabling data augmentation and introduction of more physiologically plausible variation to the data. For these purposes, we have developed a synthetic biosignal model for two signal modalities, electrocardiography (ECG) and photoplethysmography (PPG). The model produces realistic signals that account for physiological effects such as breathing modulation and changes in heart rate due to physical stress. Arrhythmic signals can be generated with beat intervals extracted from real measurements. The model also includes a flexible approach to adding different kinds of noise and signal artifacts. The noise is generated from power spectral densities extracted from both measured noisy signals and modeled power spectra. Importantly, the model also automatically produces labels for noise, segmentation (e.g. P and T waves, QRS complex, for electrocardiograms), and artifacts. We assessed how this comprehensive model can be used in practice to improve the performance of models trained on ECG or PPG data. For example, we trained an LSTM to detect ECG R-peaks using both real ECG signals from the MIT-BIH arrythmia set and our new generator. The F1 score of the model was 0.83 using real data, in comparison to 0.98 using our generator. In addition, the model can be used for example in signal segmentation, quality detection and bench-marking detection algorithms. The model code has been released in \url{https://github.com/UTU-Health-Research/framework_for_synthetic_biosignals}
Empirical investigation of multi-source cross-validation in clinical machine learning
Mar 22, 2024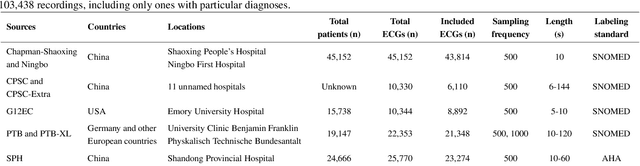
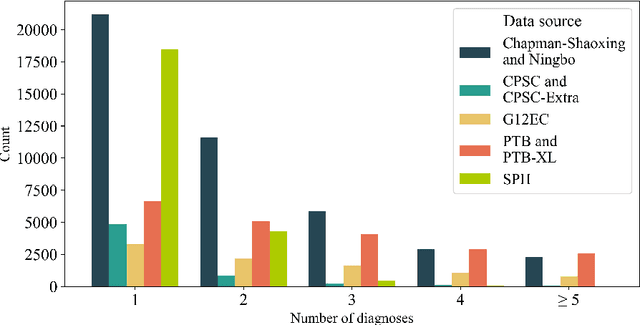
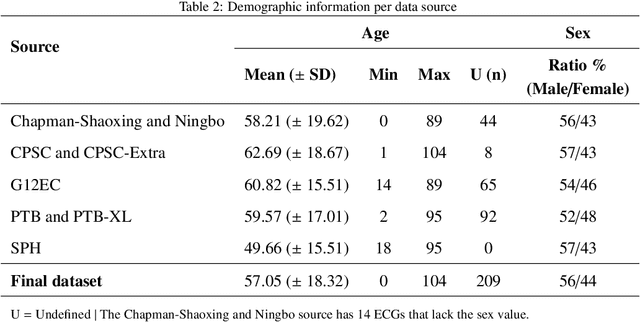
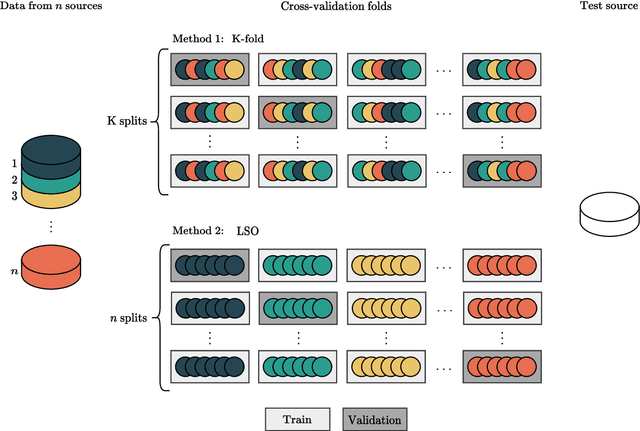
Traditionally, machine learning-based clinical prediction models have been trained and evaluated on patient data from a single source, such as a hospital. Cross-validation methods can be used to estimate the accuracy of such models on new patients originating from the same source, by repeated random splitting of the data. However, such estimates tend to be highly overoptimistic when compared to accuracy obtained from deploying models to sources not represented in the dataset, such as a new hospital. The increasing availability of multi-source medical datasets provides new opportunities for obtaining more comprehensive and realistic evaluations of expected accuracy through source-level cross-validation designs. In this study, we present a systematic empirical evaluation of standard K-fold cross-validation and leave-source-out cross-validation methods in a multi-source setting. We consider the task of electrocardiogram based cardiovascular disease classification, combining and harmonizing the openly available PhysioNet CinC Challenge 2021 and the Shandong Provincial Hospital datasets for our study. Our results show that K-fold cross-validation, both on single-source and multi-source data, systemically overestimates prediction performance when the end goal is to generalize to new sources. Leave-source-out cross-validation provides more reliable performance estimates, having close to zero bias though larger variability. The evaluation highlights the dangers of obtaining misleading cross-validation results on medical data and demonstrates how these issues can be mitigated when having access to multi-source data.
TF-GNN: Graph Neural Networks in TensorFlow
Jul 07, 2022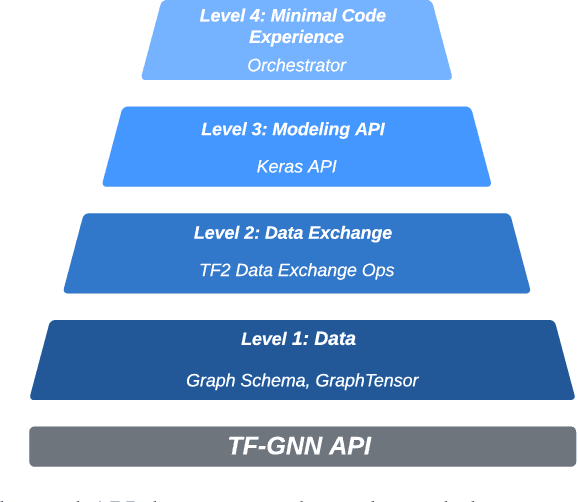
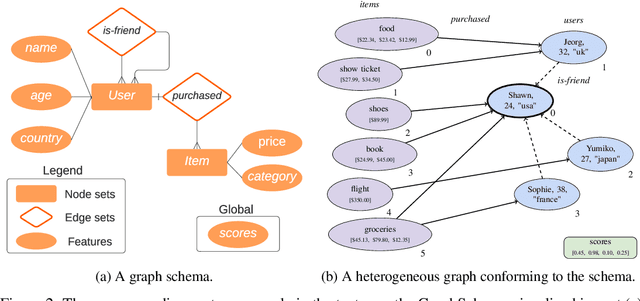
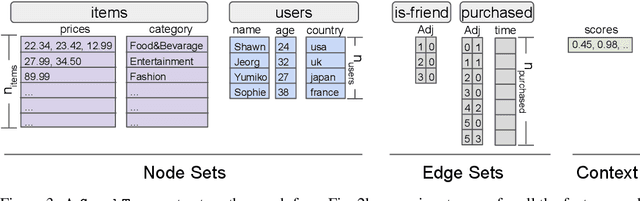
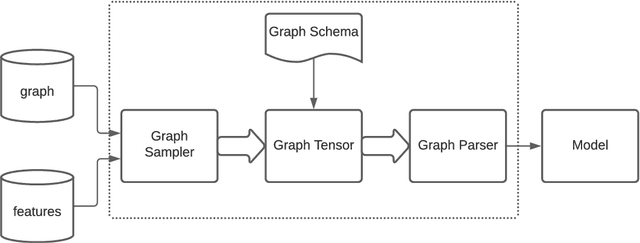
TensorFlow GNN (TF-GNN) is a scalable library for Graph Neural Networks in TensorFlow. It is designed from the bottom up to support the kinds of rich heterogeneous graph data that occurs in today's information ecosystems. Many production models at Google use TF-GNN and it has been recently released as an open source project. In this paper, we describe the TF-GNN data model, its Keras modeling API, and relevant capabilities such as graph sampling, distributed training, and accelerator support.
ETA Prediction with Graph Neural Networks in Google Maps
Aug 25, 2021


Travel-time prediction constitutes a task of high importance in transportation networks, with web mapping services like Google Maps regularly serving vast quantities of travel time queries from users and enterprises alike. Further, such a task requires accounting for complex spatiotemporal interactions (modelling both the topological properties of the road network and anticipating events -- such as rush hours -- that may occur in the future). Hence, it is an ideal target for graph representation learning at scale. Here we present a graph neural network estimator for estimated time of arrival (ETA) which we have deployed in production at Google Maps. While our main architecture consists of standard GNN building blocks, we further detail the usage of training schedule methods such as MetaGradients in order to make our model robust and production-ready. We also provide prescriptive studies: ablating on various architectural decisions and training regimes, and qualitative analyses on real-world situations where our model provides a competitive edge. Our GNN proved powerful when deployed, significantly reducing negative ETA outcomes in several regions compared to the previous production baseline (40+% in cities like Sydney).
Characterization of Multiple 3D LiDARs for Localization and Mapping using Normal Distributions Transform
Apr 03, 2020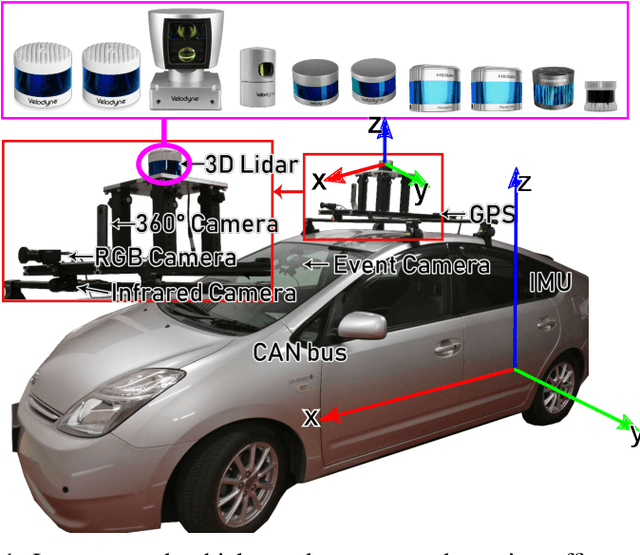

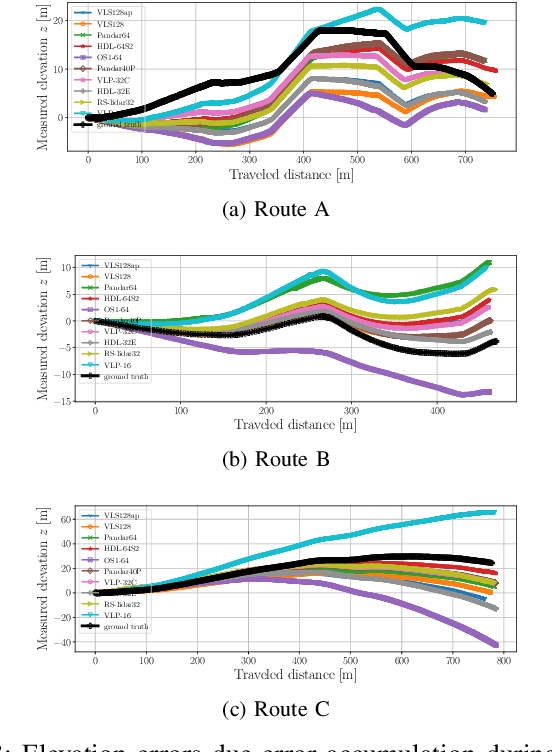

In this work, we present a detailed comparison of ten different 3D LiDAR sensors, covering a range of manufacturers, models, and laser configurations, for the tasks of mapping and vehicle localization, using as common reference the Normal Distributions Transform (NDT) algorithm implemented in the self-driving open source platform Autoware. LiDAR data used in this study is a subset of our LiDAR Benchmarking and Reference (LIBRE) dataset, captured independently from each sensor, from a vehicle driven on public urban roads multiple times, at different times of the day. In this study, we analyze the performance and characteristics of each LiDAR for the tasks of (1) 3D mapping including an assessment map quality based on mean map entropy, and (2) 6-DOF localization using a ground truth reference map.
LIBRE: The Multiple 3D LiDAR Dataset
Mar 13, 2020

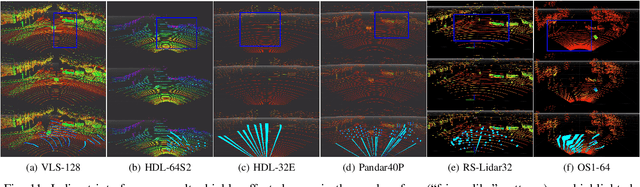

In this work, we present LIBRE: LiDAR Benchmarking and Reference, a first-of-its-kind dataset featuring 12 different LiDAR sensors, covering a range of manufacturers, models, and laser configurations. Data captured independently from each sensor includes four different environments and configurations: static obstacles placed at known distances and measured from a fixed position within a controlled environment; static obstacles measured from a moving vehicle, captured in a weather chamber where LiDARs were exposed to different conditions (fog, rain, strong light); dynamic objects actively measured from a fixed position by multiple LiDARs mounted side-by-side simultaneously, creating indirect interference conditions; and dynamic traffic objects captured from a vehicle driven on public urban roads multiple times at different times of the day, including data from supporting sensors such as cameras, infrared imaging, and odometry devices. LIBRE will contribute the research community to (1) provide a means for a fair comparison of currently available LiDARs, and (2) facilitate the improvement of existing self-driving vehicles and robotics-related software, in terms of development and tuning of LiDAR-based perception algorithms.