 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETA Prediction with Graph Neural Networks in Google Maps
Aug 25, 2021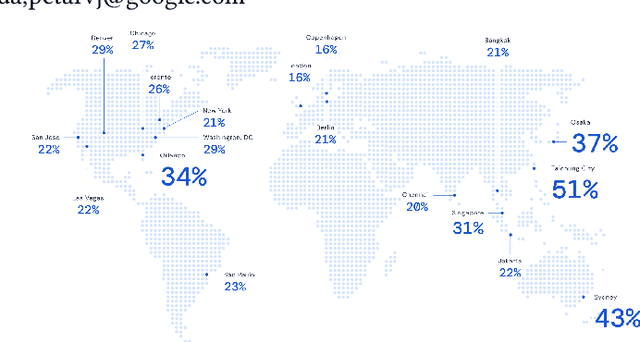


Travel-time prediction constitutes a task of high importance in transportation networks, with web mapping services like Google Maps regularly serving vast quantities of travel time queries from users and enterprises alike. Further, such a task requires accounting for complex spatiotemporal interactions (modelling both the topological properties of the road network and anticipating events -- such as rush hours -- that may occur in the future). Hence, it is an ideal target for graph representation learning at scale. Here we present a graph neural network estimator for estimated time of arrival (ETA) which we have deployed in production at Google Maps. While our main architecture consists of standard GNN building blocks, we further detail the usage of training schedule methods such as MetaGradients in order to make our model robust and production-ready. We also provide prescriptive studies: ablating on various architectural decisions and training regimes, and qualitative analyses on real-world situations where our model provides a competitive edge. Our GNN proved powerful when deployed, significantly reducing negative ETA outcomes in several regions compared to the previous production baseline (40+% in cities like Sydney).
An empirical investigation of the challenges of real-world reinforcement learning
Mar 24, 2020
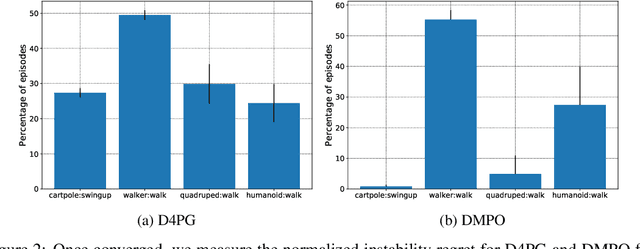

Reinforcement learning (RL) has proven its worth in a series of artificial domains, and is beginning to show some successes in real-world scenarios. However, much of the research advances in RL are hard to leverage in real-world systems due to a series of assumptions that are rarely satisfied in practice. In this work, we identify and formalize a series of independent challenges that embody the difficulties that must be addressed for RL to be commonly deployed in real-world systems. For each challenge, we define it formally in the context of a Markov Decision Process, analyze the effects of the challenge on state-of-the-art learning algorithms, and present some existing attempts at tackling it. We believe that an approach that addresses our set of proposed challenges would be readily deployable in a large number of real world problems. Our proposed challenges are implemented in a suite of continuous control environments called realworldrl-suite which we propose an as an open-source benchmark.
Robust Reinforcement Learning for Continuous Control with Model Misspecification
Jun 18, 2019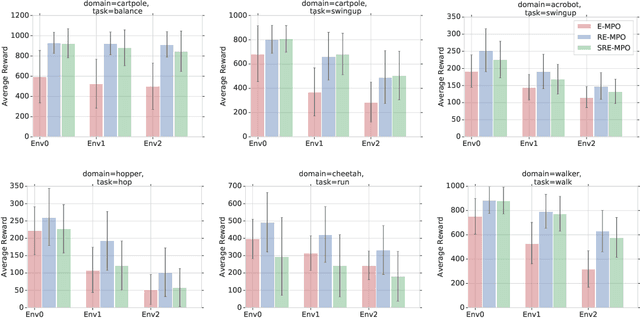

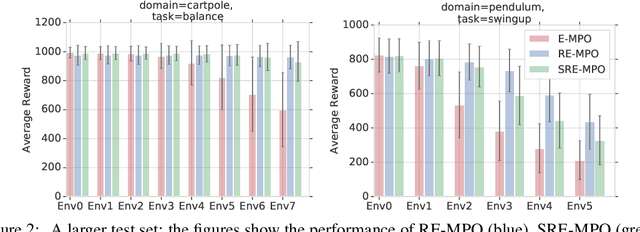
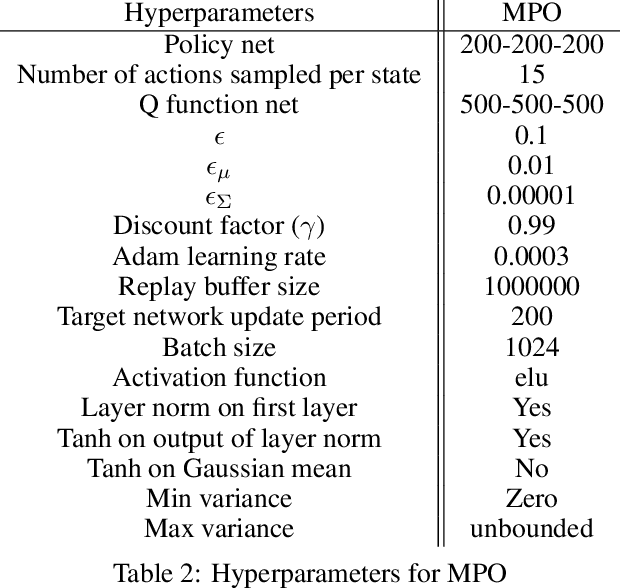
We provide a framework for incorporating robustness -- to perturbations in the transition dynamics which we refer to as model misspecification -- into continuous control Reinforcement Learning (RL) algorithms. We specifically focus on incorporating robustness into a state-of-the-art continuous control RL algorithm called Maximum a-posteriori Policy Optimization (MPO). We achieve this by learning a policy that optimizes for a worst case, entropy-regularized, expected return objective and derive a corresponding robust entropy-regularized Bellman contraction operator. In addition, we introduce a less conservative, soft-robust, entropy-regularized objective with a corresponding Bellman operator. We show that both, robust and soft-robust policies, outperform their non-robust counterparts in nine Mujoco domains with environment perturbations. Finally, we present multiple investigative experiments that provide a deeper insight into the robustness framework; including an adaptation to another continuous control RL algorithm as well as comparing this approach to domain randomization. Performance videos can be found online at https://sites.google.com/view/robust-rl.
Challenges of Real-World Reinforcement Learning
Apr 29, 2019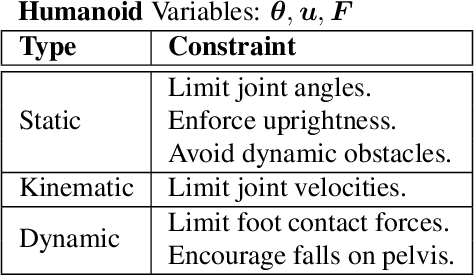
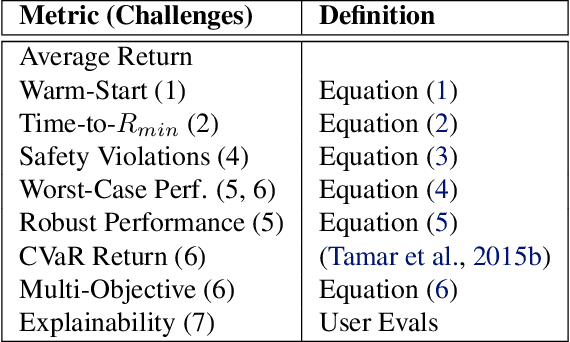

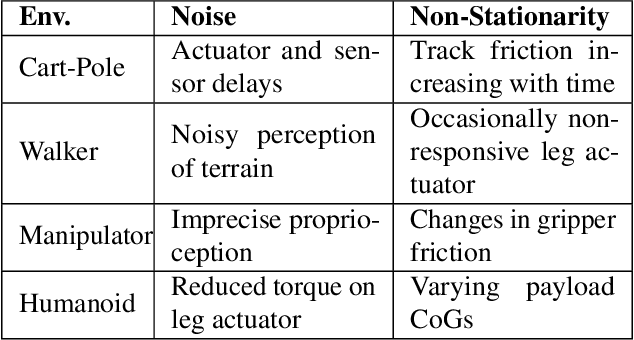
Reinforcement learning (RL) has proven its worth in a series of artificial domains, and is beginning to show some successes in real-world scenarios. However, much of the research advances in RL are often hard to leverage in real-world systems due to a series of assumptions that are rarely satisfied in practice. We present a set of nine unique challenges that must be addressed to productionize RL to real world problems. For each of these challenges, we specify the exact meaning of the challenge, present some approaches from the literature, and specify some metrics for evaluating that challenge. An approach that addresses all nine challenges would be applicable to a large number of real world problems. We also present an example domain that has been modified to present these challenges as a testbed for practical RL research.
Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards
Oct 08, 2018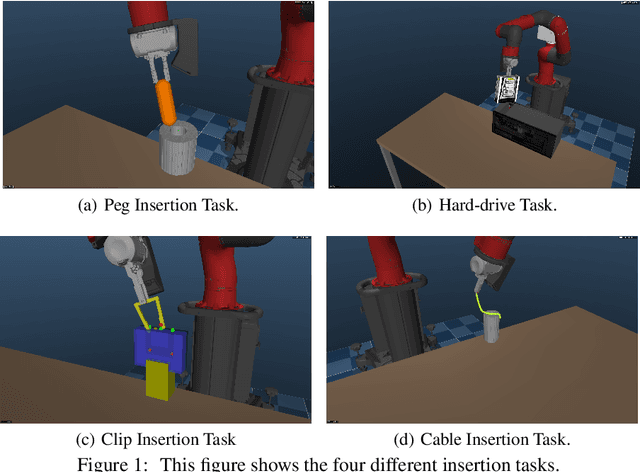

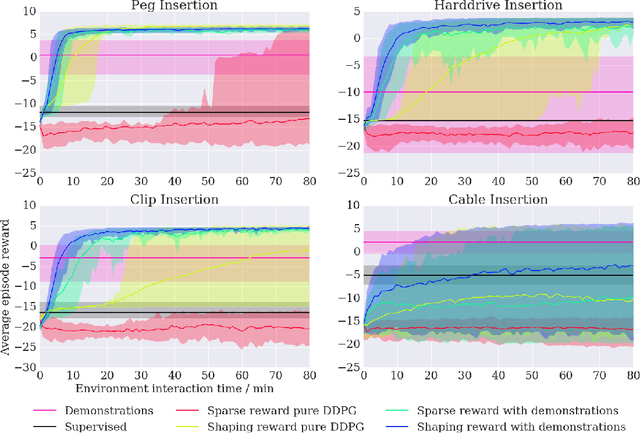
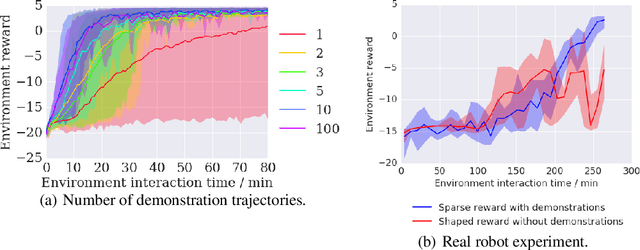
We propose a general and model-free approach for Reinforcement Learning (RL) on real robotics with sparse rewards. We build upon the Deep Deterministic Policy Gradient (DDPG) algorithm to use demonstrations. Both demonstrations and actual interactions are used to fill a replay buffer and the sampling ratio between demonstrations and transitions is automatically tuned via a prioritized replay mechanism. Typically, carefully engineered shaping rewards are required to enable the agents to efficiently explore on high dimensional control problems such as robotics. They are also required for model-based acceleration methods relying on local solvers such as iLQG (e.g. Guided Policy Search and Normalized Advantage Function). The demonstrations replace the need for carefully engineered rewards, and reduce the exploration problem encountered by classical RL approaches in these domains. Demonstrations are collected by a robot kinesthetically force-controlled by a human demonstrator. Results on four simulated insertion tasks show that DDPG from demonstrations out-performs DDPG, and does not require engineered rewards. Finally, we demonstrate the method on a real robotics task consisting of inserting a clip (flexible object) into a rigid object.
A Practical Approach to Insertion with Variable Socket Position Using Deep Reinforcement Learning
Oct 08, 2018
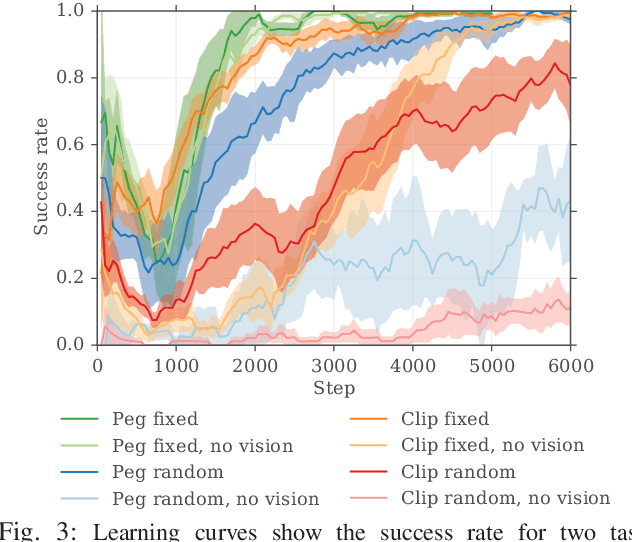
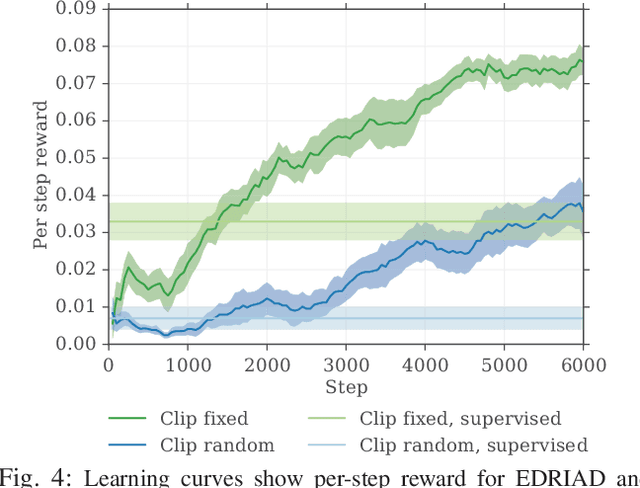
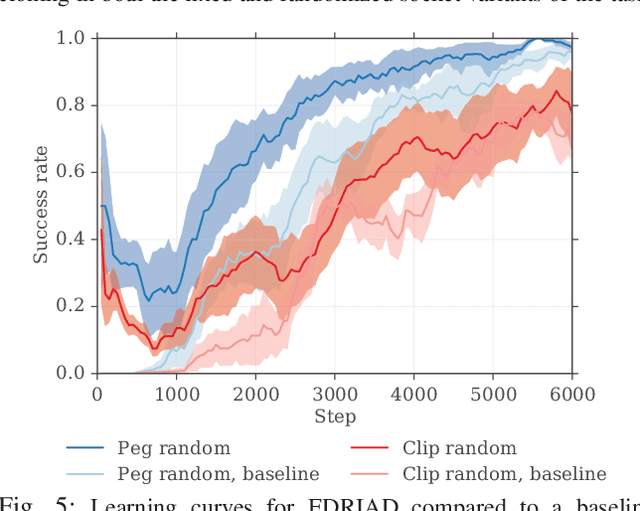
Insertion is a challenging haptic and visual control problem with significant practical value for manufacturing. Existing approaches in the model-based robotics community can be highly effective when task geometry is known, but are complex and cumbersome to implement, and must be tailored to each individual problem by a qualified engineer. Within the learning community there is a long history of insertion research, but existing approaches are typically either too sample-inefficient to run on real robots, or assume access to high-level object features, e.g. socket pose. In this paper we show that relatively minor modifications to an off-the-shelf Deep-RL algorithm (DDPG), combined with a small number of human demonstrations, allows the robot to quickly learn to solve these tasks efficiently and robustly. Our approach requires no modeling or simulation, no parameterized search or alignment behaviors, no vision system aside from raw images, and no reward shaping. We evaluate our approach on a narrow-clearance peg-insertion task and a deformable clip-insertion task, both of which include variability in the socket position. Our results show that these tasks can be solved reliably on the real robot in less than 10 minutes of interaction time, and that the resulting policies are robust to variance in the socket position and orientation.
Observe and Look Further: Achieving Consistent Performance on Atari
May 29, 2018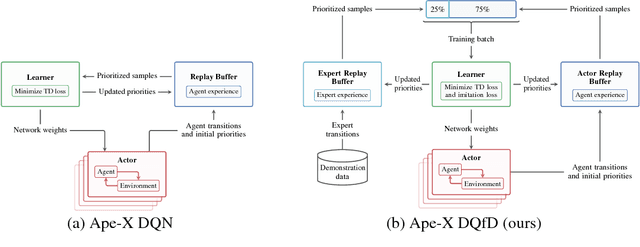
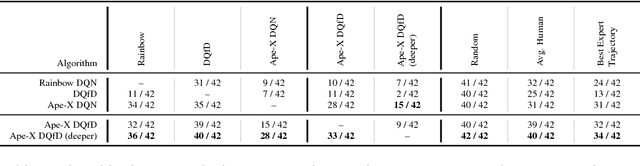
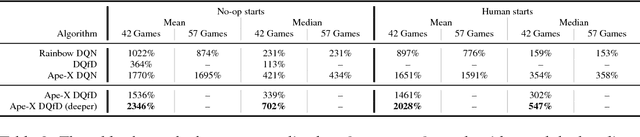
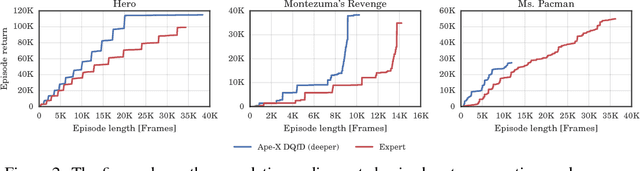
Despite significant advances in the field of deep Reinforcement Learning (RL), today's algorithms still fail to learn human-level policies consistently over a set of diverse tasks such as Atari 2600 games. We identify three key challenges that any algorithm needs to master in order to perform well on all games: processing diverse reward distributions, reasoning over long time horizons, and exploring efficiently. In this paper, we propose an algorithm that addresses each of these challenges and is able to learn human-level policies on nearly all Atari games. A new transformed Bellman operator allows our algorithm to process rewards of varying densities and scales; an auxiliary temporal consistency loss allows us to train stably using a discount factor of $\gamma = 0.999$ (instead of $\gamma = 0.99$) extending the effective planning horizon by an order of magnitude; and we ease the exploration problem by using human demonstrations that guide the agent towards rewarding states. When tested on a set of 42 Atari games, our algorithm exceeds the performance of an average human on 40 games using a common set of hyper parameters. Furthermore, it is the first deep RL algorithm to solve the first level of Montezuma's Revenge.
Safe Exploration in Continuous Action Spaces
Jan 26, 2018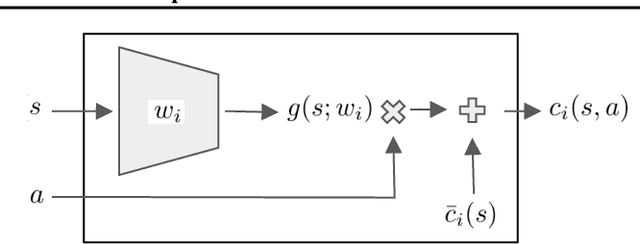
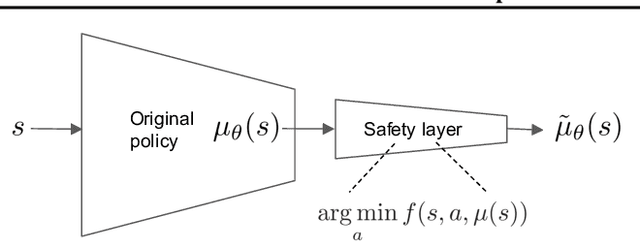


We address the problem of deploying a reinforcement learning (RL) agent on a physical system such as a datacenter cooling unit or robot, where critical constraints must never be violated. We show how to exploit the typically smooth dynamics of these systems and enable RL algorithms to never violate constraints during learning. Our technique is to directly add to the policy a safety layer that analytically solves an action correction formulation per each state. The novelty of obtaining an elegant closed-form solution is attained due to a linearized model, learned on past trajectories consisting of arbitrary actions. This is to mimic the real-world circumstances where data logs were generated with a behavior policy that is implausible to describe mathematically; such cases render the known safety-aware off-policy methods inapplicable. We demonstrate the efficacy of our approach on new representative physics-based environments, and prevail where reward shaping fails by maintaining zero constraint violations.
Deep Q-learning from Demonstrations
Nov 22, 2017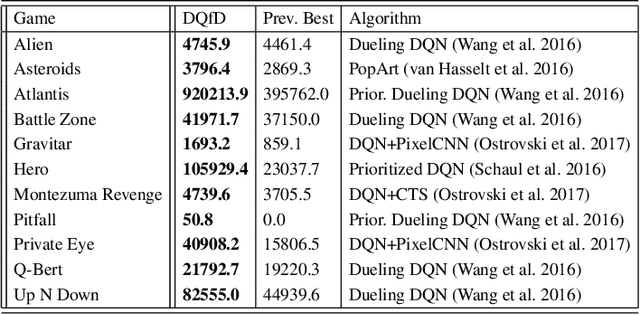
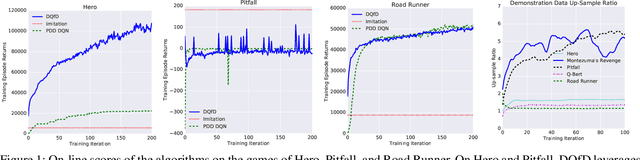
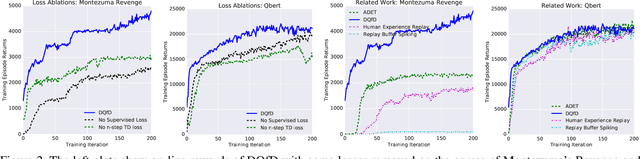
Deep reinforcement learning (RL) has achieved several high profile successes in difficult decision-making problems. However, these algorithms typically require a huge amount of data before they reach reasonable performance. In fact, their performance during learning can be extremely poor. This may be acceptable for a simulator, but it severely limits the applicability of deep RL to many real-world tasks, where the agent must learn in the real environment. In this paper we study a setting where the agent may access data from previous control of the system. We present an algorithm, Deep Q-learning from Demonstrations (DQfD), that leverages small sets of demonstration data to massively accelerate the learning process even from relatively small amounts of demonstration data and is able to automatically assess the necessary ratio of demonstration data while learning thanks to a prioritized replay mechanism. DQfD works by combining temporal difference updates with supervised classification of the demonstrator's actions. We show that DQfD has better initial performance than Prioritized Dueling Double Deep Q-Networks (PDD DQN) as it starts with better scores on the first million steps on 41 of 42 games and on average it takes PDD DQN 83 million steps to catch up to DQfD's performance. DQfD learns to out-perform the best demonstration given in 14 of 42 games. In addition, DQfD leverages human demonstrations to achieve state-of-the-art results for 11 games. Finally, we show that DQfD performs better than three related algorithms for incorporating demonstration data into DQN.
Adaptive Lambda Least-Squares Temporal Difference Learning
Dec 30, 2016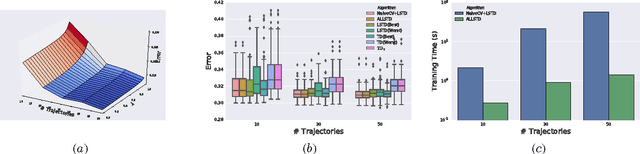
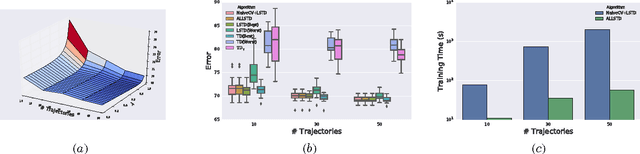
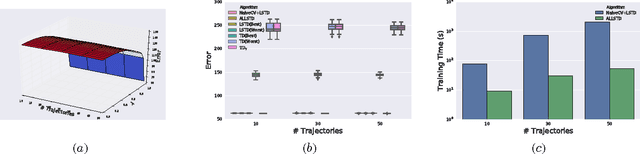
Temporal Difference learning or TD($\lambda$) is a fundamental algorithm in the field of reinforcement learning. However, setting TD's $\lambda$ parameter, which controls the timescale of TD updates, is generally left up to the practitioner. We formalize the $\lambda$ selection problem as a bias-variance trade-off where the solution is the value of $\lambda$ that leads to the smallest Mean Squared Value Error (MSVE). To solve this trade-off we suggest applying Leave-One-Trajectory-Out Cross-Validation (LOTO-CV) to search the space of $\lambda$ values. Unfortunately, this approach is too computationally expensive for most practical applications. For Least Squares TD (LSTD) we show that LOTO-CV can be implemented efficiently to automatically tune $\lambda$ and apply function optimization methods to efficiently search the space of $\lambda$ values. The resulting algorithm, ALLSTD, is parameter free and our experiments demonstrate that ALLSTD is significantly computationally faster than the na\"{i}ve LOTO-CV implementation while achieving similar performance.