 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Trajectory Bundle Method: Unifying Sequential-Convex Programming and Sampling-Based Trajectory Optimization
Sep 30, 2025



We present a unified framework for solving trajectory optimization problems in a derivative-free manner through the use of sequential convex programming. Traditionally, nonconvex optimization problems are solved by forming and solving a sequence of convex optimization problems, where the cost and constraint functions are approximated locally through Taylor series expansions. This presents a challenge for functions where differentiation is expensive or unavailable. In this work, we present a derivative-free approach to form these convex approximations by computing samples of the dynamics, cost, and constraint functions and letting the solver interpolate between them. Our framework includes sample-based trajectory optimization techniques like model-predictive path integral (MPPI) control as a special case and generalizes them to enable features like multiple shooting and general equality and inequality constraints that are traditionally associated with derivative-based sequential convex programming methods. The resulting framework is simple, flexible, and capable of solving a wide variety of practical motion planning and control problems.
Whole-Body Model-Predictive Control of Legged Robots with MuJoCo
Mar 06, 2025
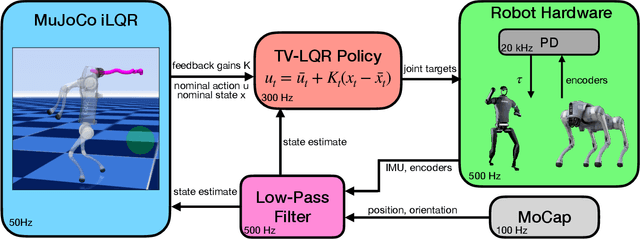

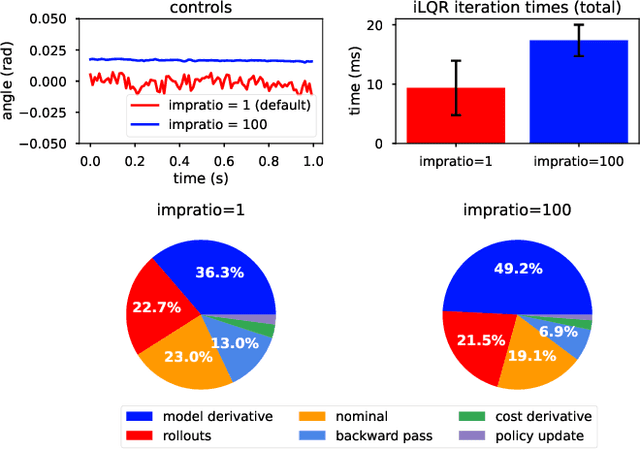
We demonstrate the surprising real-world effectiveness of a very simple approach to whole-body model-predictive control (MPC) of quadruped and humanoid robots: the iterative LQR (iLQR) algorithm with MuJoCo dynamics and finite-difference approximated derivatives. Building upon the previous success of model-based behavior synthesis and control of locomotion and manipulation tasks with MuJoCo in simulation, we show that these policies can easily generalize to the real world with few sim-to-real considerations. Our baseline method achieves real-time whole-body MPC on a variety of hardware experiments, including dynamic quadruped locomotion, quadruped walking on two legs, and full-sized humanoid bipedal locomotion. We hope this easy-to-reproduce hardware baseline lowers the barrier to entry for real-world whole-body MPC research and contributes to accelerating research velocity in the community. Our code and experiment videos will be available online at:https://johnzhang3.github.io/mujoco_ilqr
MuJoCo Playground
Feb 12, 2025We introduce MuJoCo Playground, a fully open-source framework for robot learning built with MJX, with the express goal of streamlining simulation, training, and sim-to-real transfer onto robots. With a simple "pip install playground", researchers can train policies in minutes on a single GPU. Playground supports diverse robotic platforms, including quadrupeds, humanoids, dexterous hands, and robotic arms, enabling zero-shot sim-to-real transfer from both state and pixel inputs. This is achieved through an integrated stack comprising a physics engine, batch renderer, and training environments. Along with video results, the entire framework is freely available at playground.mujoco.org
Achieving Human Level Competitive Robot Table Tennis
Aug 07, 2024



Achieving human-level speed and performance on real world tasks is a north star for the robotics research community. This work takes a step towards that goal and presents the first learned robot agent that reaches amateur human-level performance in competitive table tennis. Table tennis is a physically demanding sport which requires human players to undergo years of training to achieve an advanced level of proficiency. In this paper, we contribute (1) a hierarchical and modular policy architecture consisting of (i) low level controllers with their detailed skill descriptors which model the agent's capabilities and help to bridge the sim-to-real gap and (ii) a high level controller that chooses the low level skills, (2) techniques for enabling zero-shot sim-to-real including an iterative approach to defining the task distribution that is grounded in the real-world and defines an automatic curriculum, and (3) real time adaptation to unseen opponents. Policy performance was assessed through 29 robot vs. human matches of which the robot won 45% (13/29). All humans were unseen players and their skill level varied from beginner to tournament level. Whilst the robot lost all matches vs. the most advanced players it won 100% matches vs. beginners and 55% matches vs. intermediate players, demonstrating solidly amateur human-level performance. Videos of the matches can be viewed at https://sites.google.com/view/competitive-robot-table-tennis
Efficient Online Learning of Contact Force Models for Connector Insertion
Dec 14, 2023Contact-rich manipulation tasks with stiff frictional elements like connector insertion are difficult to model with rigid-body simulators. In this work, we propose a new approach for modeling these environments by learning a quasi-static contact force model instead of a full simulator. Using a feature vector that contains information about the configuration and control, we find a linear mapping adequately captures the relationship between this feature vector and the sensed contact forces. A novel Linear Model Learning (LML) algorithm is used to solve for the globally optimal mapping in real time without any matrix inversions, resulting in an algorithm that runs in nearly constant time on a GPU as the model size increases. We validate the proposed approach for connector insertion both in simulation and hardware experiments, where the learned model is combined with an optimization-based controller to achieve smooth insertions in the presence of misalignments and uncertainty. Our website featuring videos, code, and more materials is available at https://model-based-plugging.github.io/.
Language to Rewards for Robotic Skill Synthesis
Jun 16, 2023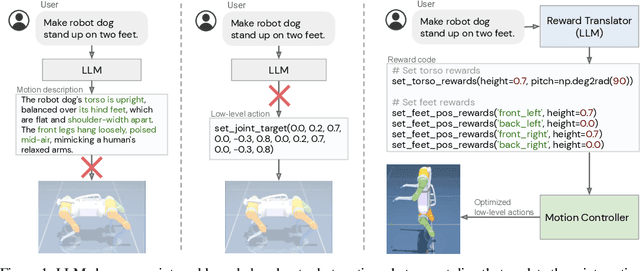
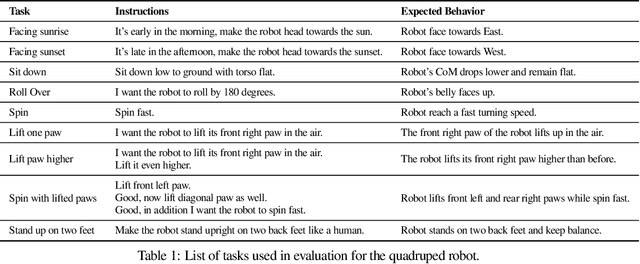

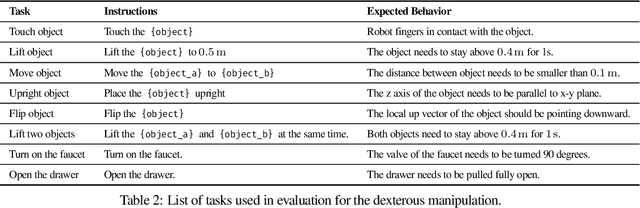
Large language models (LLMs) have demonstrated exciting progress in acquiring diverse new capabilities through in-context learning, ranging from logical reasoning to code-writing. Robotics researchers have also explored using LLMs to advance the capabilities of robotic control. However, since low-level robot actions are hardware-dependent and underrepresented in LLM training corpora, existing efforts in applying LLMs to robotics have largely treated LLMs as semantic planners or relied on human-engineered control primitives to interface with the robot. On the other hand, reward functions are shown to be flexible representations that can be optimized for control policies to achieve diverse tasks, while their semantic richness makes them suitable to be specified by LLMs. In this work, we introduce a new paradigm that harnesses this realization by utilizing LLMs to define reward parameters that can be optimized and accomplish variety of robotic tasks. Using reward as the intermediate interface generated by LLMs, we can effectively bridge the gap between high-level language instructions or corrections to low-level robot actions. Meanwhile, combining this with a real-time optimizer, MuJoCo MPC, empowers an interactive behavior creation experience where users can immediately observe the results and provide feedback to the system. To systematically evaluate the performance of our proposed method, we designed a total of 17 tasks for a simulated quadruped robot and a dexterous manipulator robot. We demonstrate that our proposed method reliably tackles 90% of the designed tasks, while a baseline using primitive skills as the interface with Code-as-policies achieves 50% of the tasks. We further validated our method on a real robot arm where complex manipulation skills such as non-prehensile pushing emerge through our interactive system.
Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning
Apr 26, 2023We investigate whether Deep Reinforcement Learning (Deep RL) is able to synthesize sophisticated and safe movement skills for a low-cost, miniature humanoid robot that can be composed into complex behavioral strategies in dynamic environments. We used Deep RL to train a humanoid robot with 20 actuated joints to play a simplified one-versus-one (1v1) soccer game. We first trained individual skills in isolation and then composed those skills end-to-end in a self-play setting. The resulting policy exhibits robust and dynamic movement skills such as rapid fall recovery, walking, turning, kicking and more; and transitions between them in a smooth, stable, and efficient manner - well beyond what is intuitively expected from the robot. The agents also developed a basic strategic understanding of the game, and learned, for instance, to anticipate ball movements and to block opponent shots. The full range of behaviors emerged from a small set of simple rewards. Our agents were trained in simulation and transferred to real robots zero-shot. We found that a combination of sufficiently high-frequency control, targeted dynamics randomization, and perturbations during training in simulation enabled good-quality transfer, despite significant unmodeled effects and variations across robot instances. Although the robots are inherently fragile, minor hardware modifications together with basic regularization of the behavior during training led the robots to learn safe and effective movements while still performing in a dynamic and agile way. Indeed, even though the agents were optimized for scoring, in experiments they walked 156% faster, took 63% less time to get up, and kicked 24% faster than a scripted baseline, while efficiently combining the skills to achieve the longer term objectives. Examples of the emergent behaviors and full 1v1 matches are available on the supplementary website.
RoboPianist: A Benchmark for High-Dimensional Robot Control
Apr 09, 2023



We introduce a new benchmarking suite for high-dimensional control, targeted at testing high spatial and temporal precision, coordination, and planning, all with an underactuated system frequently making-and-breaking contacts. The proposed challenge is mastering the piano through bi-manual dexterity, using a pair of simulated anthropomorphic robot hands. We call it RoboPianist, and the initial version covers a broad set of 150 variable-difficulty songs. We investigate both model-free and model-based methods on the benchmark, characterizing their performance envelopes. We observe that while certain existing methods, when well-tuned, can achieve impressive levels of performance in certain aspects, there is significant room for improvement. RoboPianist provides a rich quantitative benchmarking environment, with human-interpretable results, high ease of expansion by simply augmenting the repertoire with new songs, and opportunities for further research, including in multi-task learning, zero-shot generalization, multimodal (sound, vision, touch) learning, and imitation. Supplementary information, including videos of our control policies, can be found at https://kzakka.com/robopianist/
Predictive Sampling: Real-time Behaviour Synthesis with MuJoCo
Dec 01, 2022We introduce MuJoCo MPC (MJPC), an open-source, interactive application and software framework for real-time predictive control, based on MuJoCo physics. MJPC allows the user to easily author and solve complex robotics tasks, and currently supports three shooting-based planners: derivative-based iLQG and Gradient Descent, and a simple derivative-free method we call Predictive Sampling. Predictive Sampling was designed as an elementary baseline, mostly for its pedagogical value, but turned out to be surprisingly competitive with the more established algorithms. This work does not present algorithmic advances, and instead, prioritises performant algorithms, simple code, and accessibility of model-based methods via intuitive and interactive software. MJPC is available at: github.com/deepmind/mujoco_mpc, a video summary can be viewed at: dpmd.ai/mjpc.
Imitate and Repurpose: Learning Reusable Robot Movement Skills From Human and Animal Behaviors
Mar 31, 2022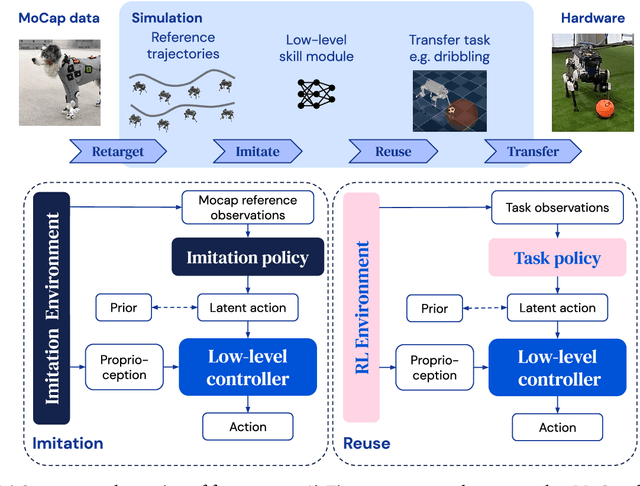

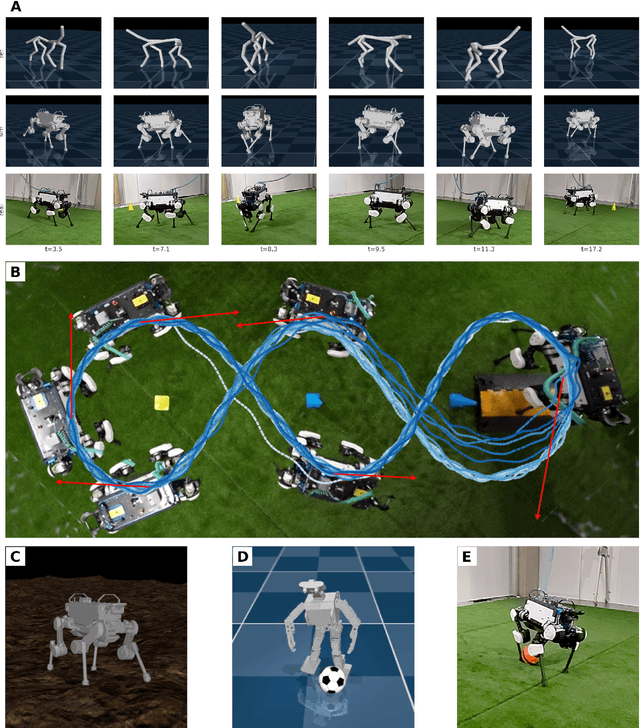
We investigate the use of prior knowledge of human and animal movement to learn reusable locomotion skills for real legged robots. Our approach builds upon previous work on imitating human or dog Motion Capture (MoCap) data to learn a movement skill module. Once learned, this skill module can be reused for complex downstream tasks. Importantly, due to the prior imposed by the MoCap data, our approach does not require extensive reward engineering to produce sensible and natural looking behavior at the time of reuse. This makes it easy to create well-regularized, task-oriented controllers that are suitable for deployment on real robots. We demonstrate how our skill module can be used for imitation, and train controllable walking and ball dribbling policies for both the ANYmal quadruped and OP3 humanoid. These policies are then deployed on hardware via zero-shot simulation-to-reality transfer. Accompanying videos are available at https://bit.ly/robot-npmp.