 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUpdate-Free On-Policy Steering via Verifiers
Mar 10, 2026In recent years, Behavior Cloning (BC) has become one of the most prevalent methods for enabling robots to mimic human demonstrations. However, despite their successes, BC policies are often brittle and struggle with precise manipulation. To overcome these issues, we propose UF-OPS, an Update-Free On-Policy Steering method that enables the robot to predict the success likelihood of its actions and adapt its strategy at execution time. We accomplish this by training verifier functions using policy rollout data obtained during an initial evaluation of the policy. These verifiers are subsequently used to steer the base policy toward actions with a higher likelihood of success. Our method improves the performance of black-box diffusion policy, without changing the base parameters, making it light-weight and flexible. We present results from both simulation and real-world data and achieve an average 49% improvement in success rate over the base policy across 5 real tasks.
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Predictive Red Teaming: Breaking Policies Without Breaking Robots
Feb 10, 2025Visuomotor policies trained via imitation learning are capable of performing challenging manipulation tasks, but are often extremely brittle to lighting, visual distractors, and object locations. These vulnerabilities can depend unpredictably on the specifics of training, and are challenging to expose without time-consuming and expensive hardware evaluations. We propose the problem of predictive red teaming: discovering vulnerabilities of a policy with respect to environmental factors, and predicting the corresponding performance degradation without hardware evaluations in off-nominal scenarios. In order to achieve this, we develop RoboART: an automated red teaming (ART) pipeline that (1) modifies nominal observations using generative image editing to vary different environmental factors, and (2) predicts performance under each variation using a policy-specific anomaly detector executed on edited observations. Experiments across 500+ hardware trials in twelve off-nominal conditions for visuomotor diffusion policies demonstrate that RoboART predicts performance degradation with high accuracy (less than 0.19 average difference between predicted and real success rates). We also demonstrate how predictive red teaming enables targeted data collection: fine-tuning with data collected under conditions predicted to be adverse boosts baseline performance by 2-7x.
Learning the RoPEs: Better 2D and 3D Position Encodings with STRING
Feb 04, 2025



We introduce STRING: Separable Translationally Invariant Position Encodings. STRING extends Rotary Position Encodings, a recently proposed and widely used algorithm in large language models, via a unifying theoretical framework. Importantly, STRING still provides exact translation invariance, including token coordinates of arbitrary dimensionality, whilst maintaining a low computational footprint. These properties are especially important in robotics, where efficient 3D token representation is key. We integrate STRING into Vision Transformers with RGB(-D) inputs (color plus optional depth), showing substantial gains, e.g. in open-vocabulary object detection and for robotics controllers. We complement our experiments with a rigorous mathematical analysis, proving the universality of our methods.
Mobility VLA: Multimodal Instruction Navigation with Long-Context VLMs and Topological Graphs
Jul 10, 2024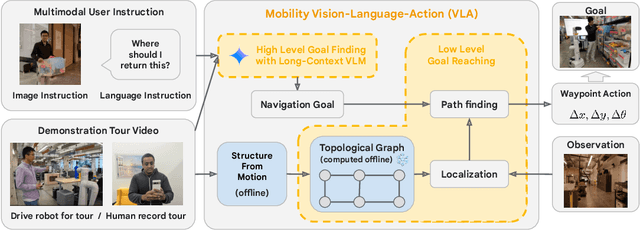
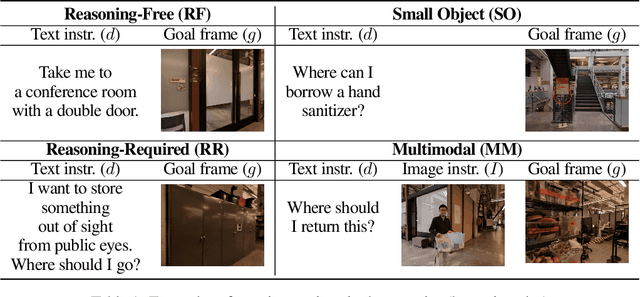


An elusive goal in navigation research is to build an intelligent agent that can understand multimodal instructions including natural language and image, and perform useful navigation. To achieve this, we study a widely useful category of navigation tasks we call Multimodal Instruction Navigation with demonstration Tours (MINT), in which the environment prior is provided through a previously recorded demonstration video. Recent advances in Vision Language Models (VLMs) have shown a promising path in achieving this goal as it demonstrates capabilities in perceiving and reasoning about multimodal inputs. However, VLMs are typically trained to predict textual output and it is an open research question about how to best utilize them in navigation. To solve MINT, we present Mobility VLA, a hierarchical Vision-Language-Action (VLA) navigation policy that combines the environment understanding and common sense reasoning power of long-context VLMs and a robust low-level navigation policy based on topological graphs. The high-level policy consists of a long-context VLM that takes the demonstration tour video and the multimodal user instruction as input to find the goal frame in the tour video. Next, a low-level policy uses the goal frame and an offline constructed topological graph to generate robot actions at every timestep. We evaluated Mobility VLA in a 836m^2 real world environment and show that Mobility VLA has a high end-to-end success rates on previously unsolved multimodal instructions such as "Where should I return this?" while holding a plastic bin.
Modeling the Real World with High-Density Visual Particle Dynamics
Jun 28, 2024



We present High-Density Visual Particle Dynamics (HD-VPD), a learned world model that can emulate the physical dynamics of real scenes by processing massive latent point clouds containing 100K+ particles. To enable efficiency at this scale, we introduce a novel family of Point Cloud Transformers (PCTs) called Interlacers leveraging intertwined linear-attention Performer layers and graph-based neighbour attention layers. We demonstrate the capabilities of HD-VPD by modeling the dynamics of high degree-of-freedom bi-manual robots with two RGB-D cameras. Compared to the previous graph neural network approach, our Interlacer dynamics is twice as fast with the same prediction quality, and can achieve higher quality using 4x as many particles. We illustrate how HD-VPD can evaluate motion plan quality with robotic box pushing and can grasping tasks. See videos and particle dynamics rendered by HD-VPD at https://sites.google.com/view/hd-vpd.
Embodied AI with Two Arms: Zero-shot Learning, Safety and Modularity
Apr 04, 2024We present an embodied AI system which receives open-ended natural language instructions from a human, and controls two arms to collaboratively accomplish potentially long-horizon tasks over a large workspace. Our system is modular: it deploys state of the art Large Language Models for task planning,Vision-Language models for semantic perception, and Point Cloud transformers for grasping. With semantic and physical safety in mind, these modules are interfaced with a real-time trajectory optimizer and a compliant tracking controller to enable human-robot proximity. We demonstrate performance for the following tasks: bi-arm sorting, bottle opening, and trash disposal tasks. These are done zero-shot where the models used have not been trained with any real world data from this bi-arm robot, scenes or workspace.Composing both learning- and non-learning-based components in a modular fashion with interpretable inputs and outputs allows the user to easily debug points of failures and fragilities. One may also in-place swap modules to improve the robustness of the overall platform, for instance with imitation-learned policies.
Revisiting Energy Based Models as Policies: Ranking Noise Contrastive Estimation and Interpolating Energy Models
Sep 11, 2023



A crucial design decision for any robot learning pipeline is the choice of policy representation: what type of model should be used to generate the next set of robot actions? Owing to the inherent multi-modal nature of many robotic tasks, combined with the recent successes in generative modeling, researchers have turned to state-of-the-art probabilistic models such as diffusion models for policy representation. In this work, we revisit the choice of energy-based models (EBM) as a policy class. We show that the prevailing folklore -- that energy models in high dimensional continuous spaces are impractical to train -- is false. We develop a practical training objective and algorithm for energy models which combines several key ingredients: (i) ranking noise contrastive estimation (R-NCE), (ii) learnable negative samplers, and (iii) non-adversarial joint training. We prove that our proposed objective function is asymptotically consistent and quantify its limiting variance. On the other hand, we show that the Implicit Behavior Cloning (IBC) objective is actually biased even at the population level, providing a mathematical explanation for the poor performance of IBC trained energy policies in several independent follow-up works. We further extend our algorithm to learn a continuous stochastic process that bridges noise and data, modeling this process with a family of EBMs indexed by scale variable. In doing so, we demonstrate that the core idea behind recent progress in generative modeling is actually compatible with EBMs. Altogether, our proposed training algorithms enable us to train energy-based models as policies which compete with -- and even outperform -- diffusion models and other state-of-the-art approaches in several challenging multi-modal benchmarks: obstacle avoidance path planning and contact-rich block pushing.
Robots That Ask For Help: Uncertainty Alignment for Large Language Model Planners
Jul 04, 2023
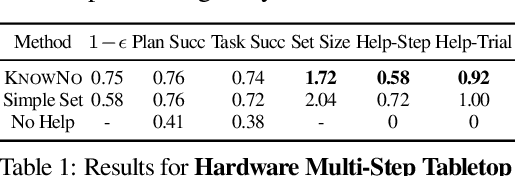


Large language models (LLMs) exhibit a wide range of promising capabilities -- from step-by-step planning to commonsense reasoning -- that may provide utility for robots, but remain prone to confidently hallucinated predictions. In this work, we present KnowNo, which is a framework for measuring and aligning the uncertainty of LLM-based planners such that they know when they don't know and ask for help when needed. KnowNo builds on the theory of conformal prediction to provide statistical guarantees on task completion while minimizing human help in complex multi-step planning settings. Experiments across a variety of simulated and real robot setups that involve tasks with different modes of ambiguity (e.g., from spatial to numeric uncertainties, from human preferences to Winograd schemas) show that KnowNo performs favorably over modern baselines (which may involve ensembles or extensive prompt tuning) in terms of improving efficiency and autonomy, while providing formal assurances. KnowNo can be used with LLMs out of the box without model-finetuning, and suggests a promising lightweight approach to modeling uncertainty that can complement and scale with the growing capabilities of foundation models. Website: https://robot-help.github.io
Agile Catching with Whole-Body MPC and Blackbox Policy Learning
Jun 14, 2023


We address a benchmark task in agile robotics: catching objects thrown at high-speed. This is a challenging task that involves tracking, intercepting, and cradling a thrown object with access only to visual observations of the object and the proprioceptive state of the robot, all within a fraction of a second. We present the relative merits of two fundamentally different solution strategies: (i) Model Predictive Control using accelerated constrained trajectory optimization, and (ii) Reinforcement Learning using zeroth-order optimization. We provide insights into various performance trade-offs including sample efficiency, sim-to-real transfer, robustness to distribution shifts, and whole-body multimodality via extensive on-hardware experiments. We conclude with proposals on fusing "classical" and "learning-based" techniques for agile robot control. Videos of our experiments may be found at https://sites.google.com/view/agile-catching