 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExoStart: Efficient learning for dexterous manipulation with sensorized exoskeleton demonstrations
Jun 13, 2025



Recent advancements in teleoperation systems have enabled high-quality data collection for robotic manipulators, showing impressive results in learning manipulation at scale. This progress suggests that extending these capabilities to robotic hands could unlock an even broader range of manipulation skills, especially if we could achieve the same level of dexterity that human hands exhibit. However, teleoperating robotic hands is far from a solved problem, as it presents a significant challenge due to the high degrees of freedom of robotic hands and the complex dynamics occurring during contact-rich settings. In this work, we present ExoStart, a general and scalable learning framework that leverages human dexterity to improve robotic hand control. In particular, we obtain high-quality data by collecting direct demonstrations without a robot in the loop using a sensorized low-cost wearable exoskeleton, capturing the rich behaviors that humans can demonstrate with their own hands. We also propose a simulation-based dynamics filter that generates dynamically feasible trajectories from the collected demonstrations and use the generated trajectories to bootstrap an auto-curriculum reinforcement learning method that relies only on simple sparse rewards. The ExoStart pipeline is generalizable and yields robust policies that transfer zero-shot to the real robot. Our results demonstrate that ExoStart can generate dexterous real-world hand skills, achieving a success rate above 50% on a wide range of complex tasks such as opening an AirPods case or inserting and turning a key in a lock. More details and videos can be found in https://sites.google.com/view/exostart.
DemoStart: Demonstration-led auto-curriculum applied to sim-to-real with multi-fingered robots
Sep 10, 2024

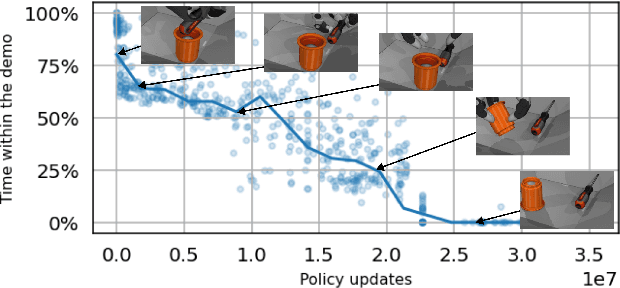
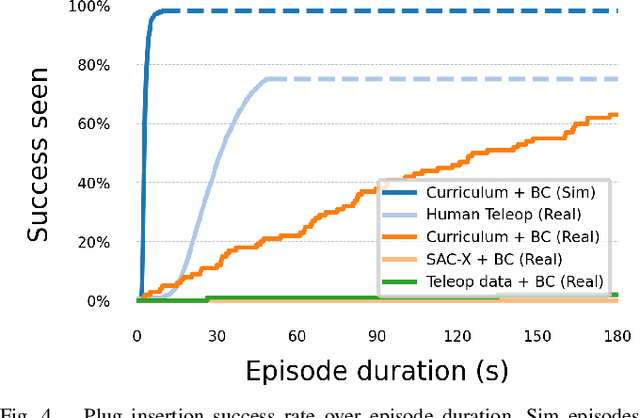
We present DemoStart, a novel auto-curriculum reinforcement learning method capable of learning complex manipulation behaviors on an arm equipped with a three-fingered robotic hand, from only a sparse reward and a handful of demonstrations in simulation. Learning from simulation drastically reduces the development cycle of behavior generation, and domain randomization techniques are leveraged to achieve successful zero-shot sim-to-real transfer. Transferred policies are learned directly from raw pixels from multiple cameras and robot proprioception. Our approach outperforms policies learned from demonstrations on the real robot and requires 100 times fewer demonstrations, collected in simulation. More details and videos in https://sites.google.com/view/demostart.
Learning to Learn Faster from Human Feedback with Language Model Predictive Control
Feb 18, 2024



Large language models (LLMs) have been shown to exhibit a wide range of capabilities, such as writing robot code from language commands -- enabling non-experts to direct robot behaviors, modify them based on feedback, or compose them to perform new tasks. However, these capabilities (driven by in-context learning) are limited to short-term interactions, where users' feedback remains relevant for only as long as it fits within the context size of the LLM, and can be forgotten over longer interactions. In this work, we investigate fine-tuning the robot code-writing LLMs, to remember their in-context interactions and improve their teachability i.e., how efficiently they adapt to human inputs (measured by average number of corrections before the user considers the task successful). Our key observation is that when human-robot interactions are formulated as a partially observable Markov decision process (in which human language inputs are observations, and robot code outputs are actions), then training an LLM to complete previous interactions can be viewed as training a transition dynamics model -- that can be combined with classic robotics techniques such as model predictive control (MPC) to discover shorter paths to success. This gives rise to Language Model Predictive Control (LMPC), a framework that fine-tunes PaLM 2 to improve its teachability on 78 tasks across 5 robot embodiments -- improving non-expert teaching success rates of unseen tasks by 26.9% while reducing the average number of human corrections from 2.4 to 1.9. Experiments show that LMPC also produces strong meta-learners, improving the success rate of in-context learning new tasks on unseen robot embodiments and APIs by 31.5%. See videos, code, and demos at: https://robot-teaching.github.io/.
Language to Rewards for Robotic Skill Synthesis
Jun 16, 2023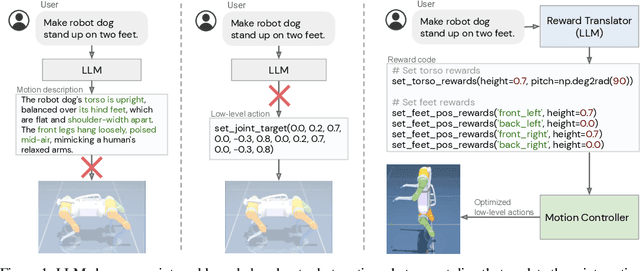
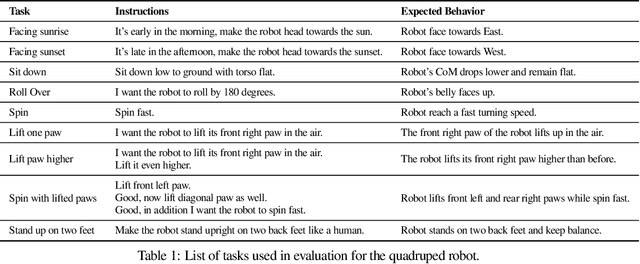

Large language models (LLMs) have demonstrated exciting progress in acquiring diverse new capabilities through in-context learning, ranging from logical reasoning to code-writing. Robotics researchers have also explored using LLMs to advance the capabilities of robotic control. However, since low-level robot actions are hardware-dependent and underrepresented in LLM training corpora, existing efforts in applying LLMs to robotics have largely treated LLMs as semantic planners or relied on human-engineered control primitives to interface with the robot. On the other hand, reward functions are shown to be flexible representations that can be optimized for control policies to achieve diverse tasks, while their semantic richness makes them suitable to be specified by LLMs. In this work, we introduce a new paradigm that harnesses this realization by utilizing LLMs to define reward parameters that can be optimized and accomplish variety of robotic tasks. Using reward as the intermediate interface generated by LLMs, we can effectively bridge the gap between high-level language instructions or corrections to low-level robot actions. Meanwhile, combining this with a real-time optimizer, MuJoCo MPC, empowers an interactive behavior creation experience where users can immediately observe the results and provide feedback to the system. To systematically evaluate the performance of our proposed method, we designed a total of 17 tasks for a simulated quadruped robot and a dexterous manipulator robot. We demonstrate that our proposed method reliably tackles 90% of the designed tasks, while a baseline using primitive skills as the interface with Code-as-policies achieves 50% of the tasks. We further validated our method on a real robot arm where complex manipulation skills such as non-prehensile pushing emerge through our interactive system.
RoboPianist: A Benchmark for High-Dimensional Robot Control
Apr 09, 2023



We introduce a new benchmarking suite for high-dimensional control, targeted at testing high spatial and temporal precision, coordination, and planning, all with an underactuated system frequently making-and-breaking contacts. The proposed challenge is mastering the piano through bi-manual dexterity, using a pair of simulated anthropomorphic robot hands. We call it RoboPianist, and the initial version covers a broad set of 150 variable-difficulty songs. We investigate both model-free and model-based methods on the benchmark, characterizing their performance envelopes. We observe that while certain existing methods, when well-tuned, can achieve impressive levels of performance in certain aspects, there is significant room for improvement. RoboPianist provides a rich quantitative benchmarking environment, with human-interpretable results, high ease of expansion by simply augmenting the repertoire with new songs, and opportunities for further research, including in multi-task learning, zero-shot generalization, multimodal (sound, vision, touch) learning, and imitation. Supplementary information, including videos of our control policies, can be found at https://kzakka.com/robopianist/
Predictive Sampling: Real-time Behaviour Synthesis with MuJoCo
Dec 01, 2022We introduce MuJoCo MPC (MJPC), an open-source, interactive application and software framework for real-time predictive control, based on MuJoCo physics. MJPC allows the user to easily author and solve complex robotics tasks, and currently supports three shooting-based planners: derivative-based iLQG and Gradient Descent, and a simple derivative-free method we call Predictive Sampling. Predictive Sampling was designed as an elementary baseline, mostly for its pedagogical value, but turned out to be surprisingly competitive with the more established algorithms. This work does not present algorithmic advances, and instead, prioritises performant algorithms, simple code, and accessibility of model-based methods via intuitive and interactive software. MJPC is available at: github.com/deepmind/mujoco_mpc, a video summary can be viewed at: dpmd.ai/mjpc.
Beyond Pick-and-Place: Tackling Robotic Stacking of Diverse Shapes
Nov 03, 2021
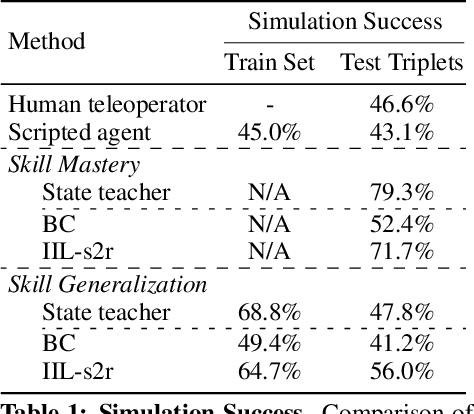
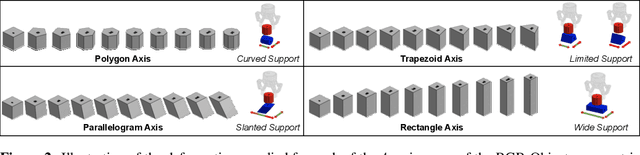
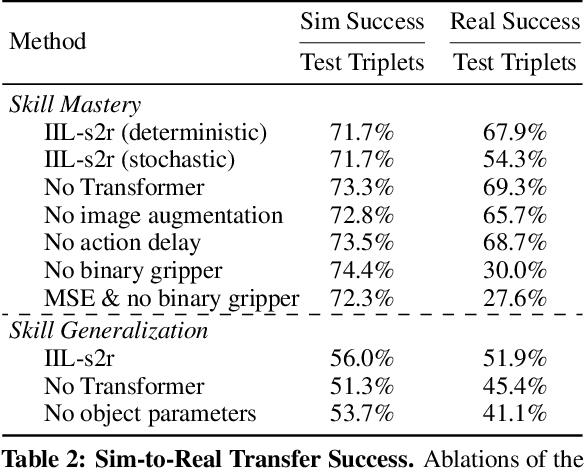
We study the problem of robotic stacking with objects of complex geometry. We propose a challenging and diverse set of such objects that was carefully designed to require strategies beyond a simple "pick-and-place" solution. Our method is a reinforcement learning (RL) approach combined with vision-based interactive policy distillation and simulation-to-reality transfer. Our learned policies can efficiently handle multiple object combinations in the real world and exhibit a large variety of stacking skills. In a large experimental study, we investigate what choices matter for learning such general vision-based agents in simulation, and what affects optimal transfer to the real robot. We then leverage data collected by such policies and improve upon them with offline RL. A video and a blog post of our work are provided as supplementary material.