 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Pick-and-Place: Tackling Robotic Stacking of Diverse Shapes
Nov 03, 2021
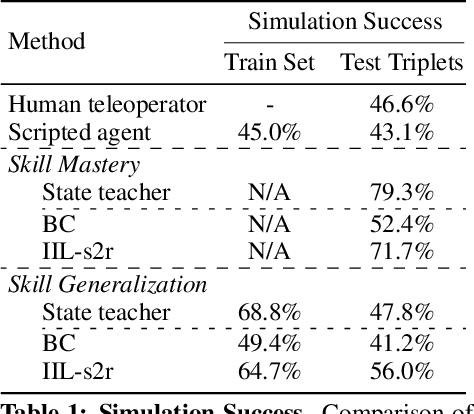
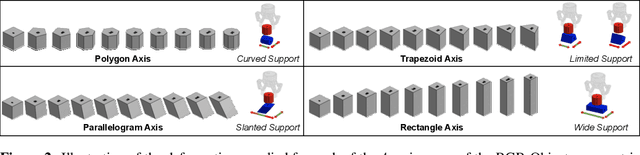
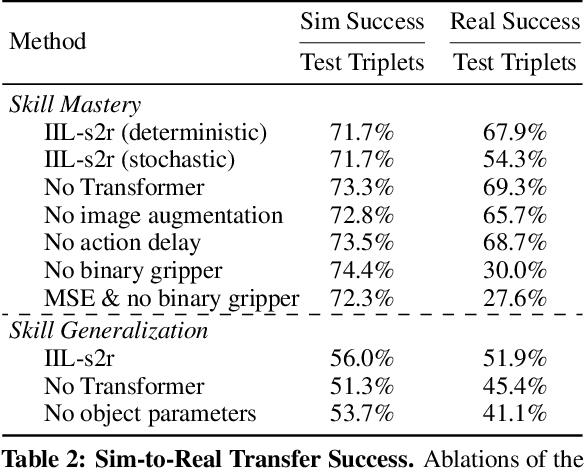
We study the problem of robotic stacking with objects of complex geometry. We propose a challenging and diverse set of such objects that was carefully designed to require strategies beyond a simple "pick-and-place" solution. Our method is a reinforcement learning (RL) approach combined with vision-based interactive policy distillation and simulation-to-reality transfer. Our learned policies can efficiently handle multiple object combinations in the real world and exhibit a large variety of stacking skills. In a large experimental study, we investigate what choices matter for learning such general vision-based agents in simulation, and what affects optimal transfer to the real robot. We then leverage data collected by such policies and improve upon them with offline RL. A video and a blog post of our work are provided as supplementary material.
Self-Supervised Sim-to-Real Adaptation for Visual Robotic Manipulation
Oct 21, 2019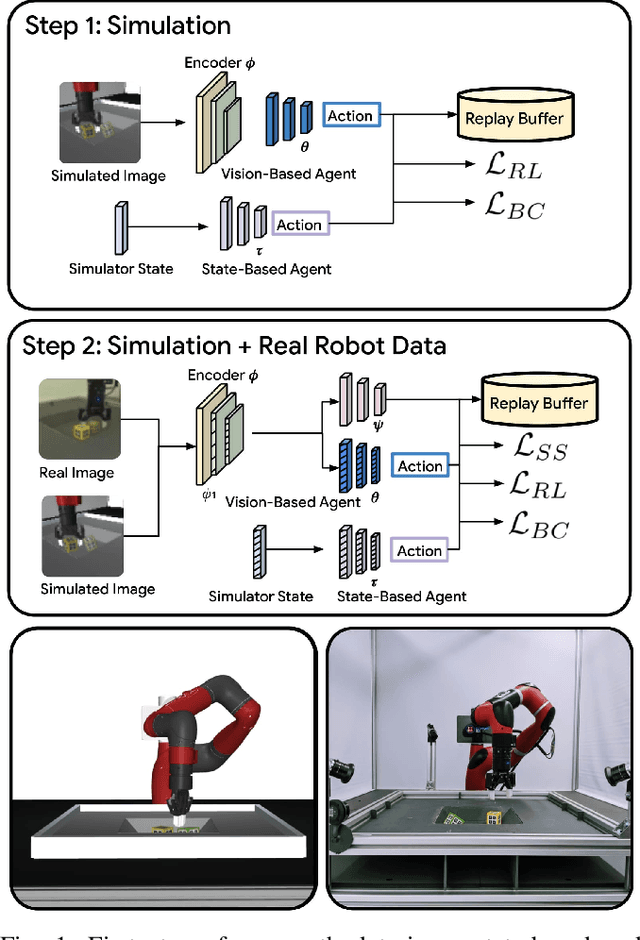

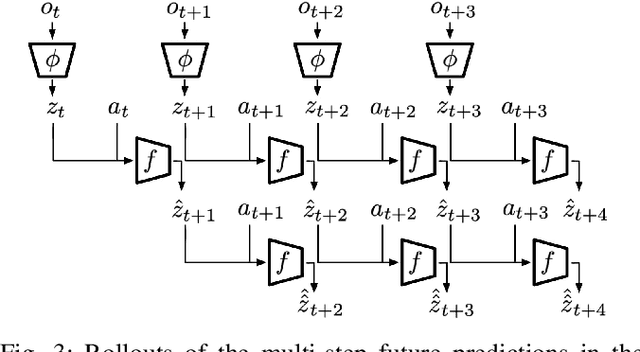
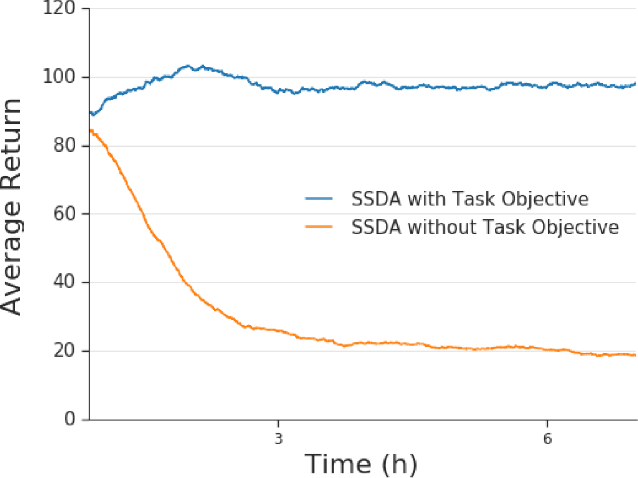
Collecting and automatically obtaining reward signals from real robotic visual data for the purposes of training reinforcement learning algorithms can be quite challenging and time-consuming. Methods for utilizing unlabeled data can have a huge potential to further accelerate robotic learning. We consider here the problem of performing manipulation tasks from pixels. In such tasks, choosing an appropriate state representation is crucial for planning and control. This is even more relevant with real images where noise, occlusions and resolution affect the accuracy and reliability of state estimation. In this work, we learn a latent state representation implicitly with deep reinforcement learning in simulation, and then adapt it to the real domain using unlabeled real robot data. We propose to do so by optimizing sequence-based self supervised objectives. These exploit the temporal nature of robot experience, and can be common in both the simulated and real domains, without assuming any alignment of underlying states in simulated and unlabeled real images. We propose Contrastive Forward Dynamics loss, which combines dynamics model learning with time-contrastive techniques. The learned state representation that results from our methods can be used to robustly solve a manipulation task in simulation and to successfully transfer the learned skill on a real system. We demonstrate the effectiveness of our approaches by training a vision-based reinforcement learning agent for cube stacking. Agents trained with our method, using only 5 hours of unlabeled real robot data for adaptation, shows a clear improvement over domain randomization, and standard visual domain adaptation techniques for sim-to-real transfer.