 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Prompting: Controlling Video Generation with Motion Trajectories
Dec 03, 2024Motion control is crucial for generating expressive and compelling video content; however, most existing video generation models rely mainly on text prompts for control, which struggle to capture the nuances of dynamic actions and temporal compositions. To this end, we train a video generation model conditioned on spatio-temporally sparse or dense motion trajectories. In contrast to prior motion conditioning work, this flexible representation can encode any number of trajectories, object-specific or global scene motion, and temporally sparse motion; due to its flexibility we refer to this conditioning as motion prompts. While users may directly specify sparse trajectories, we also show how to translate high-level user requests into detailed, semi-dense motion prompts, a process we term motion prompt expansion. We demonstrate the versatility of our approach through various applications, including camera and object motion control, "interacting" with an image, motion transfer, and image editing. Our results showcase emergent behaviors, such as realistic physics, suggesting the potential of motion prompts for probing video models and interacting with future generative world models. Finally, we evaluate quantitatively, conduct a human study, and demonstrate strong performance. Video results are available on our webpage: https://motion-prompting.github.io/
A Short Note on Evaluating RepNet for Temporal Repetition Counting in Videos
Nov 13, 2024


We discuss some consistent issues on how RepNet has been evaluated in various papers. As a way to mitigate these issues, we report RepNet performance results on different datasets, and release evaluation code and the RepNet checkpoint to obtain these results. Code URL: https://github.com/google-research/google-research/blob/master/repnet/
OVR: A Dataset for Open Vocabulary Temporal Repetition Counting in Videos
Jul 24, 2024



We introduce a dataset of annotations of temporal repetitions in videos. The dataset, OVR (pronounced as over), contains annotations for over 72K videos, with each annotation specifying the number of repetitions, the start and end time of the repetitions, and also a free-form description of what is repeating. The annotations are provided for videos sourced from Kinetics and Ego4D, and consequently cover both Exo and Ego viewing conditions, with a huge variety of actions and activities. Moreover, OVR is almost an order of magnitude larger than previous datasets for video repetition. We also propose a baseline transformer-based counting model, OVRCounter, that can localise and count repetitions in videos that are up to 320 frames long. The model is trained and evaluated on the OVR dataset, and its performance assessed with and without using text to specify the target class to count. The performance is also compared to a prior repetition counting model. The dataset is available for download at: https://sites.google.com/view/openvocabreps/
Neural Assets: 3D-Aware Multi-Object Scene Synthesis with Image Diffusion Models
Jun 13, 2024
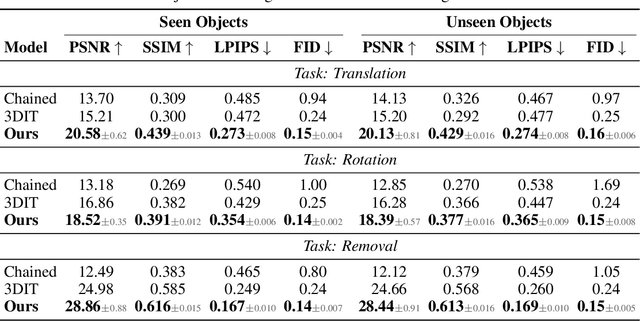

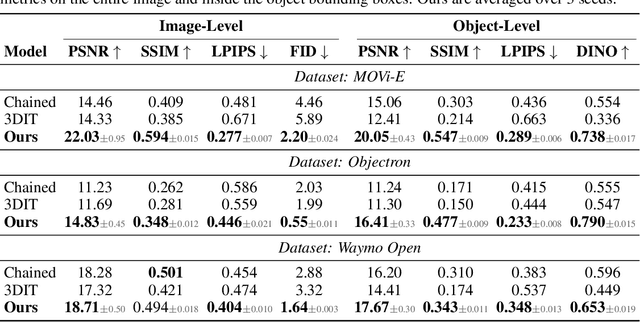
We address the problem of multi-object 3D pose control in image diffusion models. Instead of conditioning on a sequence of text tokens, we propose to use a set of per-object representations, Neural Assets, to control the 3D pose of individual objects in a scene. Neural Assets are obtained by pooling visual representations of objects from a reference image, such as a frame in a video, and are trained to reconstruct the respective objects in a different image, e.g., a later frame in the video. Importantly, we encode object visuals from the reference image while conditioning on object poses from the target frame. This enables learning disentangled appearance and pose features. Combining visual and 3D pose representations in a sequence-of-tokens format allows us to keep the text-to-image architecture of existing models, with Neural Assets in place of text tokens. By fine-tuning a pre-trained text-to-image diffusion model with this information, our approach enables fine-grained 3D pose and placement control of individual objects in a scene. We further demonstrate that Neural Assets can be transferred and recomposed across different scenes. Our model achieves state-of-the-art multi-object editing results on both synthetic 3D scene datasets, as well as two real-world video datasets (Objectron, Waymo Open).
FlexCap: Generating Rich, Localized, and Flexible Captions in Images
Mar 18, 2024



We introduce a versatile $\textit{flexible-captioning}$ vision-language model (VLM) capable of generating region-specific descriptions of varying lengths. The model, FlexCap, is trained to produce length-conditioned captions for input bounding boxes, and this allows control over the information density of its output, with descriptions ranging from concise object labels to detailed captions. To achieve this we create large-scale training datasets of image region descriptions of varying length, starting from captioned images. This flexible-captioning capability has several valuable applications. First, FlexCap demonstrates superior performance in dense captioning tasks on the Visual Genome dataset. Second, a visual question answering (VQA) system can be built by employing FlexCap to generate localized descriptions as inputs to a large language model. The resulting system achieves state-of-the-art zero-shot performance on a number of VQA datasets. We also demonstrate a $\textit{localize-then-describe}$ approach with FlexCap can be better at open-ended object detection than a $\textit{describe-then-localize}$ approach with other VLMs. We highlight a novel characteristic of FlexCap, which is its ability to extract diverse visual information through prefix conditioning. Finally, we qualitatively demonstrate FlexCap's broad applicability in tasks such as image labeling, object attribute recognition, and visual dialog. Project webpage: https://flex-cap.github.io .
Genie: Generative Interactive Environments
Feb 23, 2024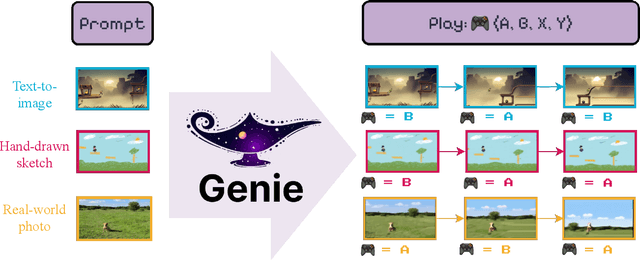
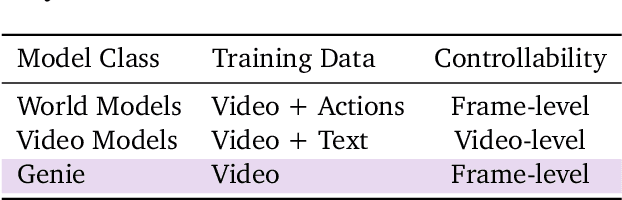
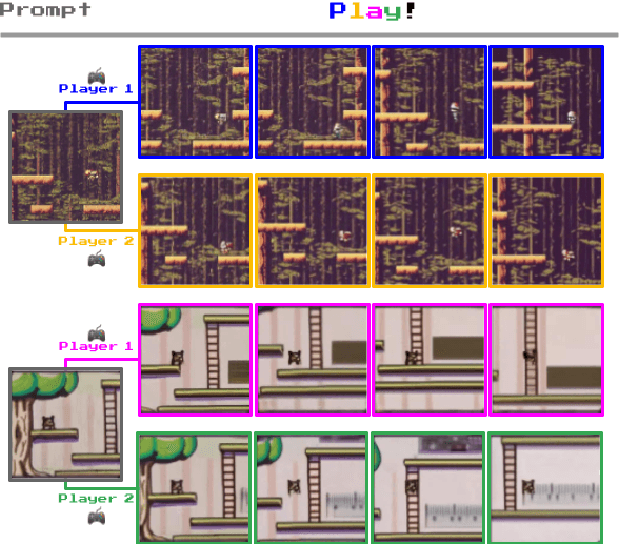
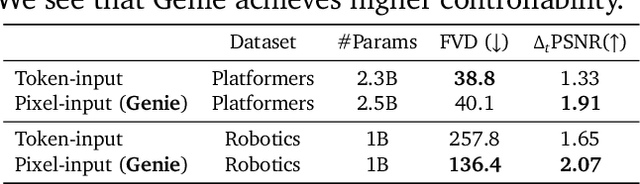
We introduce Genie, the first generative interactive environment trained in an unsupervised manner from unlabelled Internet videos. The model can be prompted to generate an endless variety of action-controllable virtual worlds described through text, synthetic images, photographs, and even sketches. At 11B parameters, Genie can be considered a foundation world model. It is comprised of a spatiotemporal video tokenizer, an autoregressive dynamics model, and a simple and scalable latent action model. Genie enables users to act in the generated environments on a frame-by-frame basis despite training without any ground-truth action labels or other domain-specific requirements typically found in the world model literature. Further the resulting learned latent action space facilitates training agents to imitate behaviors from unseen videos, opening the path for training generalist agents of the future.
Learning from One Continuous Video Stream
Dec 01, 2023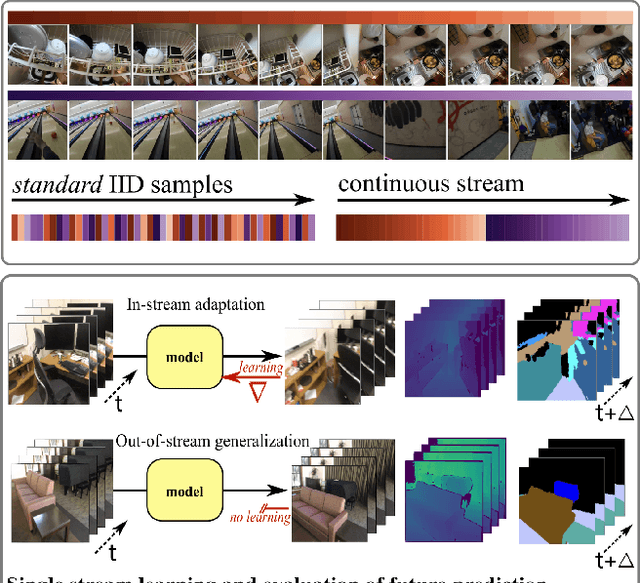

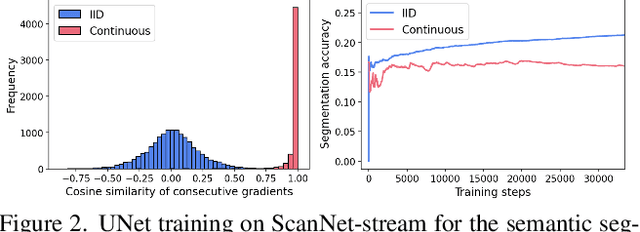

We introduce a framework for online learning from a single continuous video stream -- the way people and animals learn, without mini-batches, data augmentation or shuffling. This poses great challenges given the high correlation between consecutive video frames and there is very little prior work on it. Our framework allows us to do a first deep dive into the topic and includes a collection of streams and tasks composed from two existing video datasets, plus methodology for performance evaluation that considers both adaptation and generalization. We employ pixel-to-pixel modelling as a practical and flexible way to switch between pre-training and single-stream evaluation as well as between arbitrary tasks, without ever requiring changes to models and always using the same pixel loss. Equipped with this framework we obtained large single-stream learning gains from pre-training with a novel family of future prediction tasks, found that momentum hurts, and that the pace of weight updates matters. The combination of these insights leads to matching the performance of IID learning with batch size 1, when using the same architecture and without costly replay buffers.
RoboTAP: Tracking Arbitrary Points for Few-Shot Visual Imitation
Aug 31, 2023



For robots to be useful outside labs and specialized factories we need a way to teach them new useful behaviors quickly. Current approaches lack either the generality to onboard new tasks without task-specific engineering, or else lack the data-efficiency to do so in an amount of time that enables practical use. In this work we explore dense tracking as a representational vehicle to allow faster and more general learning from demonstration. Our approach utilizes Track-Any-Point (TAP) models to isolate the relevant motion in a demonstration, and parameterize a low-level controller to reproduce this motion across changes in the scene configuration. We show this results in robust robot policies that can solve complex object-arrangement tasks such as shape-matching, stacking, and even full path-following tasks such as applying glue and sticking objects together, all from demonstrations that can be collected in minutes.
RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation
Jun 20, 2023



The ability to leverage heterogeneous robotic experience from different robots and tasks to quickly master novel skills and embodiments has the potential to transform robot learning. Inspired by recent advances in foundation models for vision and language, we propose a foundation agent for robotic manipulation. This agent, named RoboCat, is a visual goal-conditioned decision transformer capable of consuming multi-embodiment action-labelled visual experience. This data spans a large repertoire of motor control skills from simulated and real robotic arms with varying sets of observations and actions. With RoboCat, we demonstrate the ability to generalise to new tasks and robots, both zero-shot as well as through adaptation using only 100--1000 examples for the target task. We also show how a trained model itself can be used to generate data for subsequent training iterations, thus providing a basic building block for an autonomous improvement loop. We investigate the agent's capabilities, with large-scale evaluations both in simulation and on three different real robot embodiments. We find that as we grow and diversify its training data, RoboCat not only shows signs of cross-task transfer, but also becomes more efficient at adapting to new tasks.
TAPIR: Tracking Any Point with per-frame Initialization and temporal Refinement
Jun 14, 2023We present a novel model for Tracking Any Point (TAP) that effectively tracks any queried point on any physical surface throughout a video sequence. Our approach employs two stages: (1) a matching stage, which independently locates a suitable candidate point match for the query point on every other frame, and (2) a refinement stage, which updates both the trajectory and query features based on local correlations. The resulting model surpasses all baseline methods by a significant margin on the TAP-Vid benchmark, as demonstrated by an approximate 20% absolute average Jaccard (AJ) improvement on DAVIS. Our model facilitates fast inference on long and high-resolution video sequences. On a modern GPU, our implementation has the capacity to track points faster than real-time. Visualizations, source code, and pretrained models can be found on our project webpage.