 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling 4D Representations
Dec 19, 2024



Scaling has not yet been convincingly demonstrated for pure self-supervised learning from video. However, prior work has focused evaluations on semantic-related tasks $\unicode{x2013}$ action classification, ImageNet classification, etc. In this paper we focus on evaluating self-supervised learning on non-semantic vision tasks that are more spatial (3D) and temporal (+1D = 4D), such as camera pose estimation, point and object tracking, and depth estimation. We show that by learning from very large video datasets, masked auto-encoding (MAE) with transformer video models actually scales, consistently improving performance on these 4D tasks, as model size increases from 20M all the way to the largest by far reported self-supervised video model $\unicode{x2013}$ 22B parameters. Rigorous apples-to-apples comparison with many recent image and video models demonstrates the benefits of scaling 4D representations.
Learning from One Continuous Video Stream
Dec 01, 2023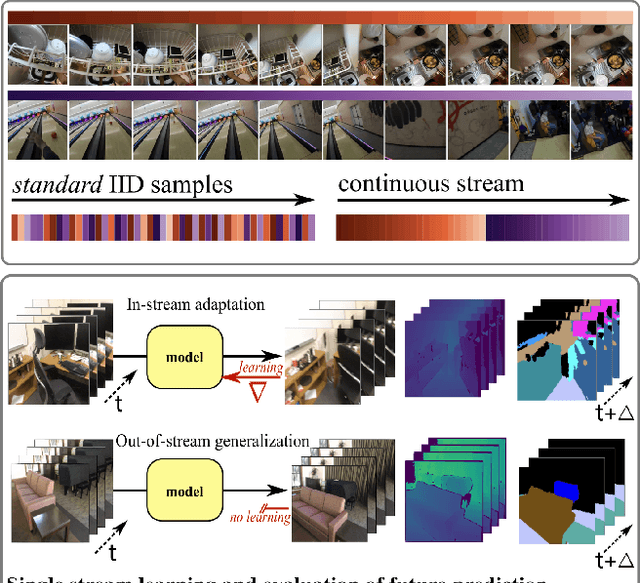

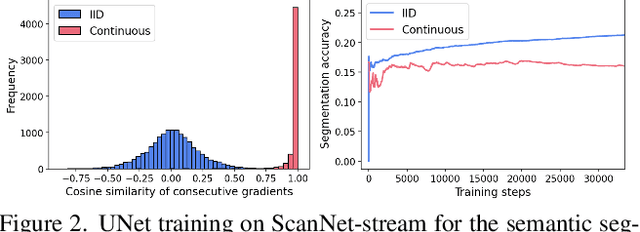

We introduce a framework for online learning from a single continuous video stream -- the way people and animals learn, without mini-batches, data augmentation or shuffling. This poses great challenges given the high correlation between consecutive video frames and there is very little prior work on it. Our framework allows us to do a first deep dive into the topic and includes a collection of streams and tasks composed from two existing video datasets, plus methodology for performance evaluation that considers both adaptation and generalization. We employ pixel-to-pixel modelling as a practical and flexible way to switch between pre-training and single-stream evaluation as well as between arbitrary tasks, without ever requiring changes to models and always using the same pixel loss. Equipped with this framework we obtained large single-stream learning gains from pre-training with a novel family of future prediction tasks, found that momentum hurts, and that the pace of weight updates matters. The combination of these insights leads to matching the performance of IID learning with batch size 1, when using the same architecture and without costly replay buffers.
Learning to estimate a surrogate respiratory signal from cardiac motion by signal-to-signal translation
Jul 20, 2022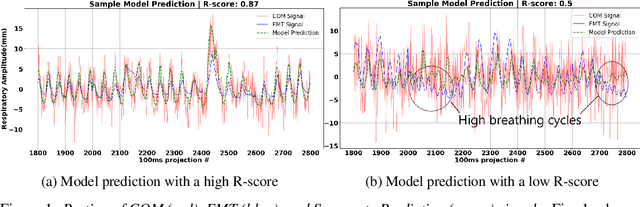
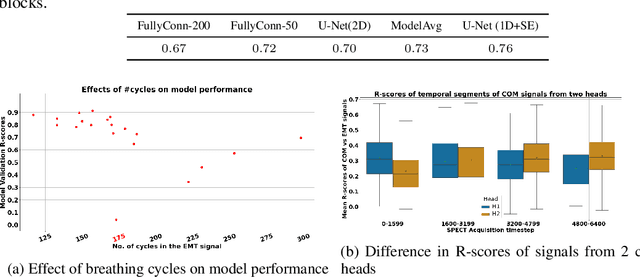
In this work, we develop a neural network-based method to convert a noisy motion signal generated from segmenting rebinned list-mode cardiac SPECT images, to that of a high-quality surrogate signal, such as those seen from external motion tracking systems (EMTs). This synthetic surrogate will be used as input to our pre-existing motion correction technique developed for EMT surrogate signals. In our method, we test two families of neural networks to translate noisy internal motion to external surrogate: 1) fully connected networks and 2) convolutional neural networks. Our dataset consists of cardiac perfusion SPECT acquisitions for which cardiac motion was estimated (input: center-of-count-mass - COM signals) in conjunction with a respiratory surrogate motion signal acquired using a commercial Vicon Motion Tracking System (GT: EMT signals). We obtained an average R-score of 0.76 between the predicted surrogate and the EMT signal. Our goal is to lay a foundation to guide the optimization of neural networks for respiratory motion correction from SPECT without the need for an EMT.
Alchemy: A structured task distribution for meta-reinforcement learning
Feb 04, 2021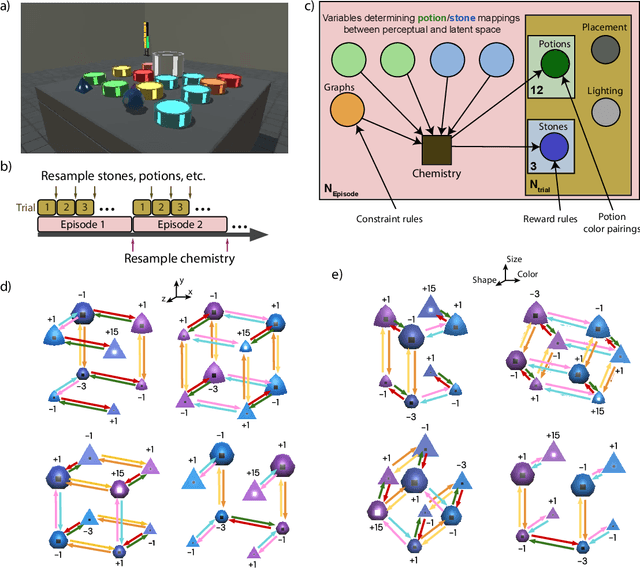

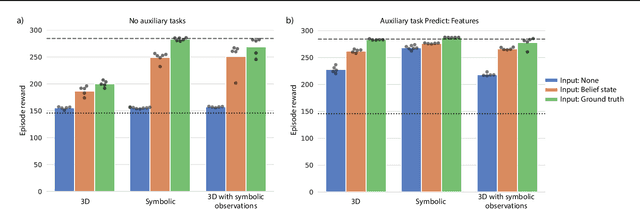

There has been rapidly growing interest in meta-learning as a method for increasing the flexibility and sample efficiency of reinforcement learning. One problem in this area of research, however, has been a scarcity of adequate benchmark tasks. In general, the structure underlying past benchmarks has either been too simple to be inherently interesting, or too ill-defined to support principled analysis. In the present work, we introduce a new benchmark for meta-RL research, which combines structural richness with structural transparency. Alchemy is a 3D video game, implemented in Unity, which involves a latent causal structure that is resampled procedurally from episode to episode, affording structure learning, online inference, hypothesis testing and action sequencing based on abstract domain knowledge. We evaluate a pair of powerful RL agents on Alchemy and present an in-depth analysis of one of these agents. Results clearly indicate a frank and specific failure of meta-learning, providing validation for Alchemy as a challenging benchmark for meta-RL. Concurrent with this report, we are releasing Alchemy as public resource, together with a suite of analysis tools and sample agent trajectories.
The Criminality From Face Illusion
Jun 06, 2020
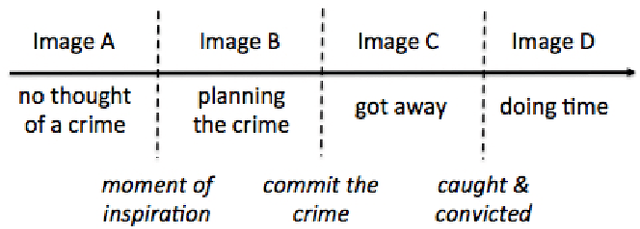

The automatic analysis of face images can generate predictions about a person's gender, age, race, facial expression, body mass index, and various other indices and conditions. A few recent publications have claimed success in analyzing an image of a person's face in order to predict the person's status as Criminal / Non-Criminal. Predicting criminality from face may initially seem similar to other facial analytics, but we argue that attempts to create a criminality-from-face algorithm are necessarily doomed to fail, that apparently promising experimental results in recent publications are an illusion resulting from inadequate experimental design, and that there is potentially a large social cost to belief in the criminality from face illusion.