 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception Test 2025: Challenge Summary and a Unified VQA Extension
Jan 09, 2026The Third Perception Test challenge was organised as a full-day workshop alongside the IEEE/CVF International Conference on Computer Vision (ICCV) 2025. Its primary goal is to benchmark state-of-the-art video models and measure the progress in multimodal perception. This year, the workshop featured 2 guest tracks as well: KiVA (an image understanding challenge) and Physic-IQ (a video generation challenge). In this report, we summarise the results from the main Perception Test challenge, detailing both the existing tasks as well as novel additions to the benchmark. In this iteration, we placed an emphasis on task unification, as this poses a more challenging test for current SOTA multimodal models. The challenge included five consolidated tracks: unified video QA, unified object and point tracking, unified action and sound localisation, grounded video QA, and hour-long video QA, alongside an analysis and interpretability track that is still open for submissions. Notably, the unified video QA track introduced a novel subset that reformulates traditional perception tasks (such as point tracking and temporal action localisation) as multiple-choice video QA questions that video-language models can natively tackle. The unified object and point tracking merged the original object tracking and point tracking tasks, whereas the unified action and sound localisation merged the original temporal action localisation and temporal sound localisation tracks. Accordingly, we required competitors to use unified approaches rather than engineered pipelines with task-specific models. By proposing such a unified challenge, Perception Test 2025 highlights the significant difficulties existing models face when tackling diverse perception tasks through unified interfaces.
Learning from Streaming Video with Orthogonal Gradients
Apr 02, 2025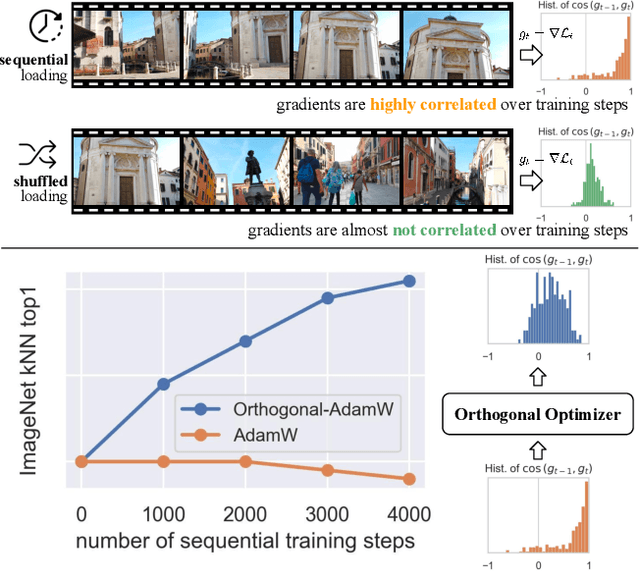
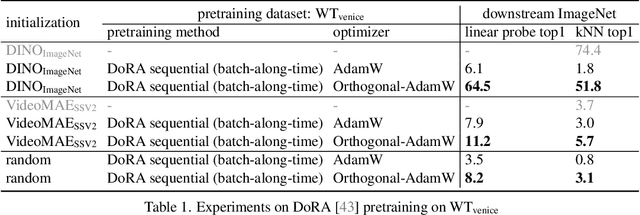
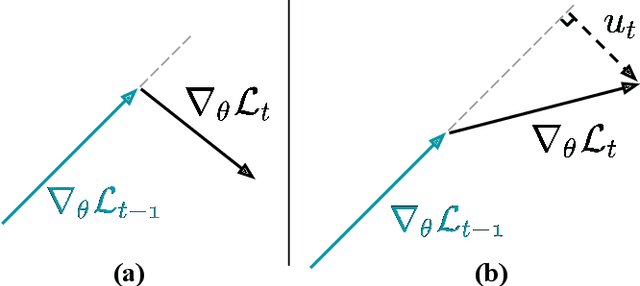
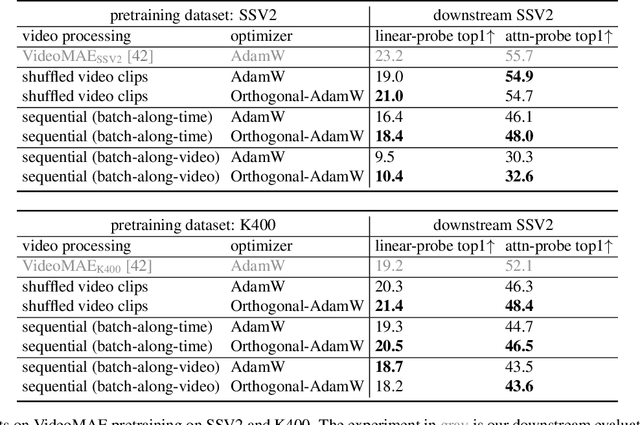
We address the challenge of representation learning from a continuous stream of video as input, in a self-supervised manner. This differs from the standard approaches to video learning where videos are chopped and shuffled during training in order to create a non-redundant batch that satisfies the independently and identically distributed (IID) sample assumption expected by conventional training paradigms. When videos are only available as a continuous stream of input, the IID assumption is evidently broken, leading to poor performance. We demonstrate the drop in performance when moving from shuffled to sequential learning on three tasks: the one-video representation learning method DoRA, standard VideoMAE on multi-video datasets, and the task of future video prediction. To address this drop, we propose a geometric modification to standard optimizers, to decorrelate batches by utilising orthogonal gradients during training. The proposed modification can be applied to any optimizer -- we demonstrate it with Stochastic Gradient Descent (SGD) and AdamW. Our proposed orthogonal optimizer allows models trained from streaming videos to alleviate the drop in representation learning performance, as evaluated on downstream tasks. On three scenarios (DoRA, VideoMAE, future prediction), we show our orthogonal optimizer outperforms the strong AdamW in all three scenarios.
Scaling 4D Representations
Dec 19, 2024



Scaling has not yet been convincingly demonstrated for pure self-supervised learning from video. However, prior work has focused evaluations on semantic-related tasks $\unicode{x2013}$ action classification, ImageNet classification, etc. In this paper we focus on evaluating self-supervised learning on non-semantic vision tasks that are more spatial (3D) and temporal (+1D = 4D), such as camera pose estimation, point and object tracking, and depth estimation. We show that by learning from very large video datasets, masked auto-encoding (MAE) with transformer video models actually scales, consistently improving performance on these 4D tasks, as model size increases from 20M all the way to the largest by far reported self-supervised video model $\unicode{x2013}$ 22B parameters. Rigorous apples-to-apples comparison with many recent image and video models demonstrates the benefits of scaling 4D representations.
TRecViT: A Recurrent Video Transformer
Dec 18, 2024We propose a novel block for video modelling. It relies on a time-space-channel factorisation with dedicated blocks for each dimension: gated linear recurrent units (LRUs) perform information mixing over time, self-attention layers perform mixing over space, and MLPs over channels. The resulting architecture TRecViT performs well on sparse and dense tasks, trained in supervised or self-supervised regimes. Notably, our model is causal and outperforms or is on par with a pure attention model ViViT-L on large scale video datasets (SSv2, Kinetics400), while having $3\times$ less parameters, $12\times$ smaller memory footprint, and $5\times$ lower FLOPs count. Code and checkpoints will be made available online at https://github.com/google-deepmind/trecvit.
Perception Test 2024: Challenge Summary and a Novel Hour-Long VideoQA Benchmark
Nov 29, 2024



Following the successful 2023 edition, we organised the Second Perception Test challenge as a half-day workshop alongside the IEEE/CVF European Conference on Computer Vision (ECCV) 2024, with the goal of benchmarking state-of-the-art video models and measuring the progress since last year using the Perception Test benchmark. This year, the challenge had seven tracks (up from six last year) and covered low-level and high-level tasks, with language and non-language interfaces, across video, audio, and text modalities; the additional track covered hour-long video understanding and introduced a novel video QA benchmark 1h-walk VQA. Overall, the tasks in the different tracks were: object tracking, point tracking, temporal action localisation, temporal sound localisation, multiple-choice video question-answering, grounded video question-answering, and hour-long video question-answering. We summarise in this report the challenge tasks and results, and introduce in detail the novel hour-long video QA benchmark 1h-walk VQA.
Moving Off-the-Grid: Scene-Grounded Video Representations
Nov 08, 2024



Current vision models typically maintain a fixed correspondence between their representation structure and image space. Each layer comprises a set of tokens arranged "on-the-grid," which biases patches or tokens to encode information at a specific spatio(-temporal) location. In this work we present Moving Off-the-Grid (MooG), a self-supervised video representation model that offers an alternative approach, allowing tokens to move "off-the-grid" to better enable them to represent scene elements consistently, even as they move across the image plane through time. By using a combination of cross-attention and positional embeddings we disentangle the representation structure and image structure. We find that a simple self-supervised objective--next frame prediction--trained on video data, results in a set of latent tokens which bind to specific scene structures and track them as they move. We demonstrate the usefulness of MooG's learned representation both qualitatively and quantitatively by training readouts on top of the learned representation on a variety of downstream tasks. We show that MooG can provide a strong foundation for different vision tasks when compared to "on-the-grid" baselines.
BootsTAP: Bootstrapped Training for Tracking-Any-Point
Feb 01, 2024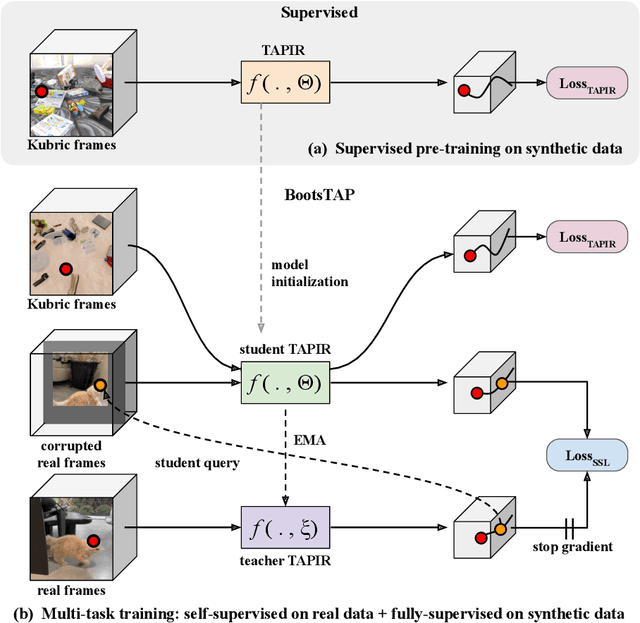
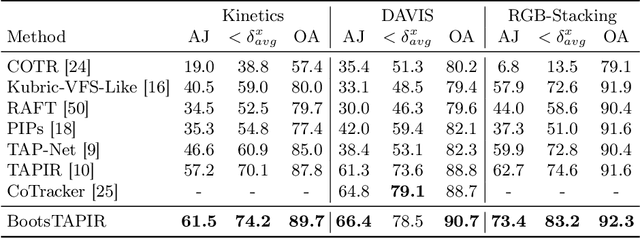
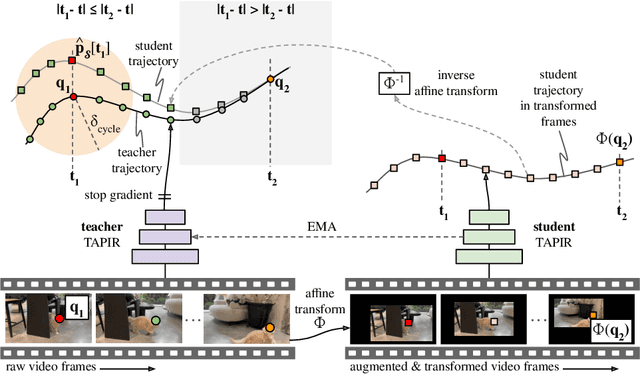
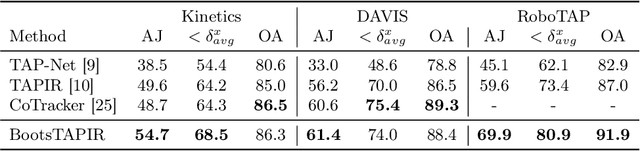
To endow models with greater understanding of physics and motion, it is useful to enable them to perceive how solid surfaces move and deform in real scenes. This can be formalized as Tracking-Any-Point (TAP), which requires the algorithm to be able to track any point corresponding to a solid surface in a video, potentially densely in space and time. Large-scale ground-truth training data for TAP is only available in simulation, which currently has limited variety of objects and motion. In this work, we demonstrate how large-scale, unlabeled, uncurated real-world data can improve a TAP model with minimal architectural changes, using a self-supervised student-teacher setup. We demonstrate state-of-the-art performance on the TAP-Vid benchmark surpassing previous results by a wide margin: for example, TAP-Vid-DAVIS performance improves from 61.3% to 66.4%, and TAP-Vid-Kinetics from 57.2% to 61.5%.
Perception Test 2023: A Summary of the First Challenge And Outcome
Dec 20, 2023



The First Perception Test challenge was held as a half-day workshop alongside the IEEE/CVF International Conference on Computer Vision (ICCV) 2023, with the goal of benchmarking state-of-the-art video models on the recently proposed Perception Test benchmark. The challenge had six tracks covering low-level and high-level tasks, with both a language and non-language interface, across video, audio, and text modalities, and covering: object tracking, point tracking, temporal action localisation, temporal sound localisation, multiple-choice video question-answering, and grounded video question-answering. We summarise in this report the task descriptions, metrics, baselines, and results.
Learning from One Continuous Video Stream
Dec 01, 2023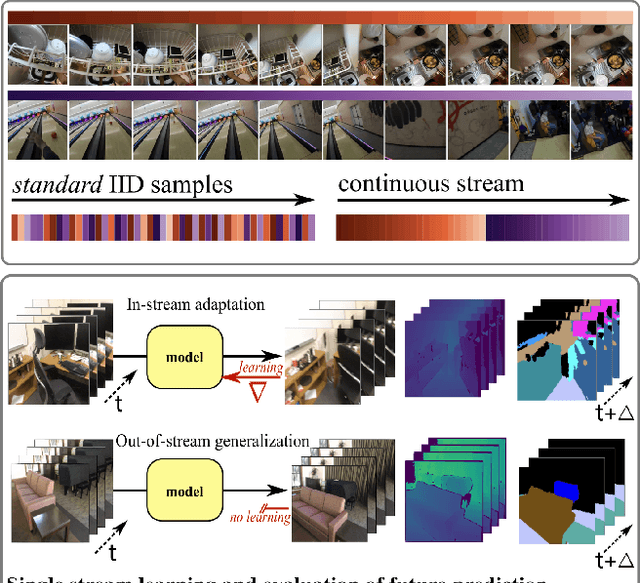

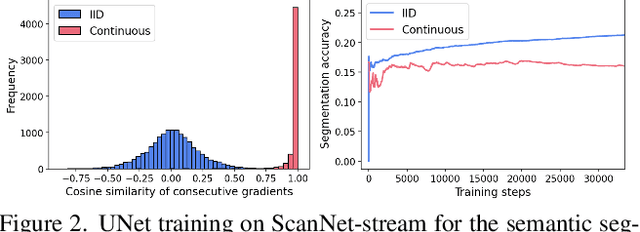

We introduce a framework for online learning from a single continuous video stream -- the way people and animals learn, without mini-batches, data augmentation or shuffling. This poses great challenges given the high correlation between consecutive video frames and there is very little prior work on it. Our framework allows us to do a first deep dive into the topic and includes a collection of streams and tasks composed from two existing video datasets, plus methodology for performance evaluation that considers both adaptation and generalization. We employ pixel-to-pixel modelling as a practical and flexible way to switch between pre-training and single-stream evaluation as well as between arbitrary tasks, without ever requiring changes to models and always using the same pixel loss. Equipped with this framework we obtained large single-stream learning gains from pre-training with a novel family of future prediction tasks, found that momentum hurts, and that the pace of weight updates matters. The combination of these insights leads to matching the performance of IID learning with batch size 1, when using the same architecture and without costly replay buffers.
Perception Test: A Diagnostic Benchmark for Multimodal Video Models
May 23, 2023


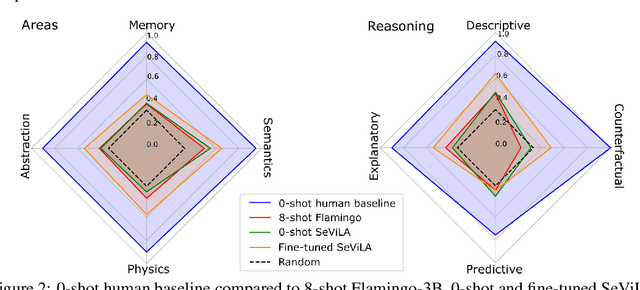
We propose a novel multimodal video benchmark - the Perception Test - to evaluate the perception and reasoning skills of pre-trained multimodal models (e.g. Flamingo, BEiT-3, or GPT-4). Compared to existing benchmarks that focus on computational tasks (e.g. classification, detection or tracking), the Perception Test focuses on skills (Memory, Abstraction, Physics, Semantics) and types of reasoning (descriptive, explanatory, predictive, counterfactual) across video, audio, and text modalities, to provide a comprehensive and efficient evaluation tool. The benchmark probes pre-trained models for their transfer capabilities, in a zero-shot / few-shot or limited finetuning regime. For these purposes, the Perception Test introduces 11.6k real-world videos, 23s average length, designed to show perceptually interesting situations, filmed by around 100 participants worldwide. The videos are densely annotated with six types of labels (multiple-choice and grounded video question-answers, object and point tracks, temporal action and sound segments), enabling both language and non-language evaluations. The fine-tuning and validation splits of the benchmark are publicly available (CC-BY license), in addition to a challenge server with a held-out test split. Human baseline results compared to state-of-the-art video QA models show a significant gap in performance (91.4% vs 43.6%), suggesting that there is significant room for improvement in multimodal video understanding. Dataset, baselines code, and challenge server are available at https://github.com/deepmind/perception_test