 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving and Evaluating Hand-Object Interaction Detection
Jun 16, 2026Understanding hands and the objects they interact with, both directly and through tools, is a key step for tasks ranging from action perception to 3D reconstruction and robotics. Our paper provides several contributions to the Hand-Object Interaction (HOI) understanding literature: (1) HOI-DETR, a new framework that introduces hand-object and object-object interactions to the Co-DETR architecture to produce a state-of-the-art method; (2) a comprehensive HOI evaluation suite of 4 diverse datasets, including a video benchmark derived from the HD-EPIC dataset and fresh annotations that improve the Hands23 benchmark and (3) a trained checkpoint that significantly improves the state of the art across Hands23, HOIST, FineBio, and HD-EPIC, including mAP gains of over 20 percentage points on Hands23 and FineBio. Our ablations confirm the contributions of each model component.
Beyond Caption-Based Queries for Video Moment Retrieval
Mar 02, 2026In this work, we investigate the degradation of existing VMR methods, particularly of DETR architectures, when trained on caption-based queries but evaluated on search queries. For this, we introduce three benchmarks by modifying the textual queries in three public VMR datasets -- i.e., HD-EPIC, YouCook2 and ActivityNet-Captions. Our analysis reveals two key generalization challenges: (i) A language gap, arising from the linguistic under-specification of search queries, and (ii) a multi-moment gap, caused by the shift from single-moment to multi-moment queries. We also identify a critical issue in these architectures -- an active decoder-query collapse -- as a primary cause of the poor generalization to multi-moment instances. We mitigate this issue with architectural modifications that effectively increase the number of active decoder queries. Extensive experiments demonstrate that our approach improves performance on search queries by up to 14.82% mAP_m, and up to 21.83% mAP_m on multi-moment search queries. The code, models and data are available in the project webpage: https://davidpujol.github.io/beyond-vmr/
Perception Test 2025: Challenge Summary and a Unified VQA Extension
Jan 09, 2026The Third Perception Test challenge was organised as a full-day workshop alongside the IEEE/CVF International Conference on Computer Vision (ICCV) 2025. Its primary goal is to benchmark state-of-the-art video models and measure the progress in multimodal perception. This year, the workshop featured 2 guest tracks as well: KiVA (an image understanding challenge) and Physic-IQ (a video generation challenge). In this report, we summarise the results from the main Perception Test challenge, detailing both the existing tasks as well as novel additions to the benchmark. In this iteration, we placed an emphasis on task unification, as this poses a more challenging test for current SOTA multimodal models. The challenge included five consolidated tracks: unified video QA, unified object and point tracking, unified action and sound localisation, grounded video QA, and hour-long video QA, alongside an analysis and interpretability track that is still open for submissions. Notably, the unified video QA track introduced a novel subset that reformulates traditional perception tasks (such as point tracking and temporal action localisation) as multiple-choice video QA questions that video-language models can natively tackle. The unified object and point tracking merged the original object tracking and point tracking tasks, whereas the unified action and sound localisation merged the original temporal action localisation and temporal sound localisation tracks. Accordingly, we required competitors to use unified approaches rather than engineered pipelines with task-specific models. By proposing such a unified challenge, Perception Test 2025 highlights the significant difficulties existing models face when tackling diverse perception tasks through unified interfaces.
Prime and Reach: Synthesising Body Motion for Gaze-Primed Object Reach
Dec 18, 2025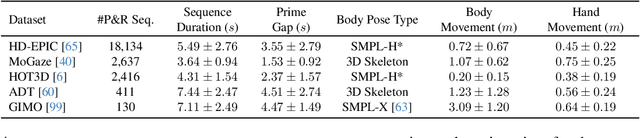



Human motion generation is a challenging task that aims to create realistic motion imitating natural human behaviour. We focus on the well-studied behaviour of priming an object/location for pick up or put down -- that is, the spotting of an object/location from a distance, known as gaze priming, followed by the motion of approaching and reaching the target location. To that end, we curate, for the first time, 23.7K gaze-primed human motion sequences for reaching target object locations from five publicly available datasets, i.e., HD-EPIC, MoGaze, HOT3D, ADT, and GIMO. We pre-train a text-conditioned diffusion-based motion generation model, then fine-tune it conditioned on goal pose or location, on our curated sequences. Importantly, we evaluate the ability of the generated motion to imitate natural human movement through several metrics, including the 'Reach Success' and a newly introduced 'Prime Success' metric. On the largest dataset, HD-EPIC, our model achieves 60% prime success and 89% reach success when conditioned on the goal object location.
The N-Body Problem: Parallel Execution from Single-Person Egocentric Video
Dec 12, 2025Humans can intuitively parallelise complex activities, but can a model learn this from observing a single person? Given one egocentric video, we introduce the N-Body Problem: how N individuals, can hypothetically perform the same set of tasks observed in this video. The goal is to maximise speed-up, but naive assignment of video segments to individuals often violates real-world constraints, leading to physically impossible scenarios like two people using the same object or occupying the same space. To address this, we formalise the N-Body Problem and propose a suite of metrics to evaluate both performance (speed-up, task coverage) and feasibility (spatial collisions, object conflicts and causal constraints). We then introduce a structured prompting strategy that guides a Vision-Language Model (VLM) to reason about the 3D environment, object usage, and temporal dependencies to produce a viable parallel execution. On 100 videos from EPIC-Kitchens and HD-EPIC, our method for N = 2 boosts action coverage by 45% over a baseline prompt for Gemini 2.5 Pro, while simultaneously slashing collision rates, object and causal conflicts by 55%, 45% and 55% respectively.
Reconstructing Objects along Hand Interaction Timelines in Egocentric Video
Dec 08, 2025We introduce the task of Reconstructing Objects along Hand Interaction Timelines (ROHIT). We first define the Hand Interaction Timeline (HIT) from a rigid object's perspective. In a HIT, an object is first static relative to the scene, then is held in hand following contact, where its pose changes. This is usually followed by a firm grip during use, before it is released to be static again w.r.t. to the scene. We model these pose constraints over the HIT, and propose to propagate the object's pose along the HIT enabling superior reconstruction using our proposed Constrained Optimisation and Propagation (COP) framework. Importantly, we focus on timelines with stable grasps - i.e. where the hand is stably holding an object, effectively maintaining constant contact during use. This allows us to efficiently annotate, study, and evaluate object reconstruction in videos without 3D ground truth. We evaluate our proposed task, ROHIT, over two egocentric datasets, HOT3D and in-the-wild EPIC-Kitchens. In HOT3D, we curate 1.2K clips of stable grasps. In EPIC-Kitchens, we annotate 2.4K clips of stable grasps including 390 object instances across 9 categories from videos of daily interactions in 141 environments. Without 3D ground truth, we utilise 2D projection error to assess the reconstruction. Quantitatively, COP improves stable grasp reconstruction by 6.2-11.3% and HIT reconstruction by up to 24.5% with constrained pose propagation.
Segmenting Collision Sound Sources in Egocentric Videos
Nov 17, 2025Humans excel at multisensory perception and can often recognise object properties from the sound of their interactions. Inspired by this, we propose the novel task of Collision Sound Source Segmentation (CS3), where we aim to segment the objects responsible for a collision sound in visual input (i.e. video frames from the collision clip), conditioned on the audio. This task presents unique challenges. Unlike isolated sound events, a collision sound arises from interactions between two objects, and the acoustic signature of the collision depends on both. We focus on egocentric video, where sounds are often clear, but the visual scene is cluttered, objects are small, and interactions are brief. To address these challenges, we propose a weakly-supervised method for audio-conditioned segmentation, utilising foundation models (CLIP and SAM2). We also incorporate egocentric cues, i.e. objects in hands, to find acting objects that can potentially be collision sound sources. Our approach outperforms competitive baselines by $3\times$ and $4.7\times$ in mIoU on two benchmarks we introduce for the CS3 task: EPIC-CS3 and Ego4D-CS3.
PointSt3R: Point Tracking through 3D Grounded Correspondence
Oct 30, 2025
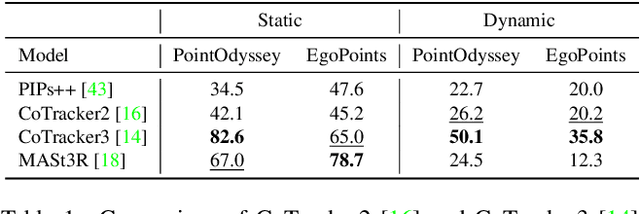
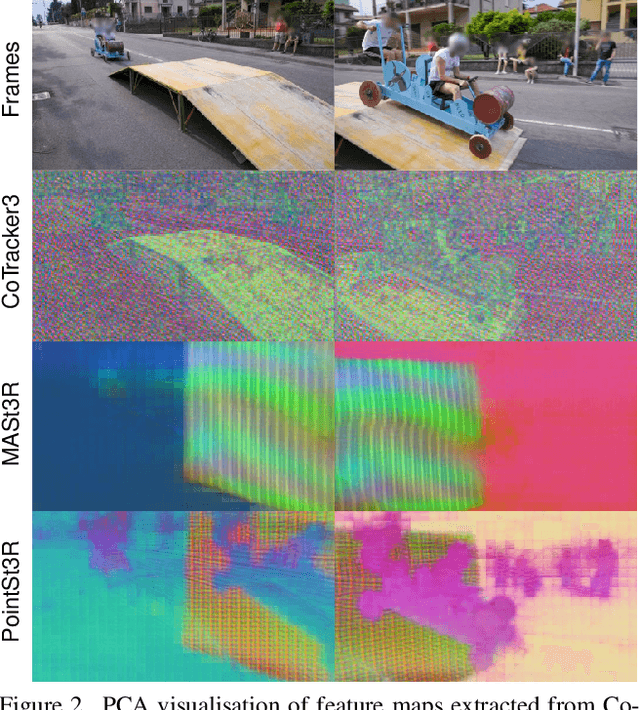
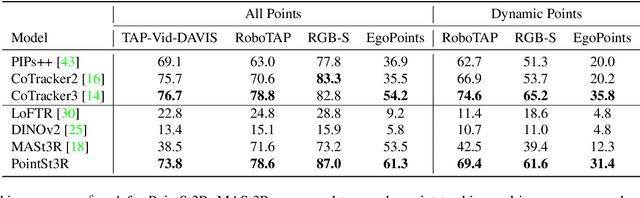
Recent advances in foundational 3D reconstruction models, such as DUSt3R and MASt3R, have shown great potential in 2D and 3D correspondence in static scenes. In this paper, we propose to adapt them for the task of point tracking through 3D grounded correspondence. We first demonstrate that these models are competitive point trackers when focusing on static points, present in current point tracking benchmarks ($+33.5\%$ on EgoPoints vs. CoTracker2). We propose to combine the reconstruction loss with training for dynamic correspondence along with a visibility head, and fine-tuning MASt3R for point tracking using a relatively small amount of synthetic data. Importantly, we only train and evaluate on pairs of frames where one contains the query point, effectively removing any temporal context. Using a mix of dynamic and static point correspondences, we achieve competitive or superior point tracking results on four datasets (e.g. competitive on TAP-Vid-DAVIS 73.8 $\delta_{avg}$ / 85.8\% occlusion acc. for PointSt3R compared to 75.7 / 88.3\% for CoTracker2; and significantly outperform CoTracker3 on EgoPoints 61.3 vs 54.2 and RGB-S 87.0 vs 82.8). We also present results on 3D point tracking along with several ablations on training datasets and percentage of dynamic correspondences.
Leveraging Auxiliary Information in Text-to-Video Retrieval: A Review
May 29, 2025
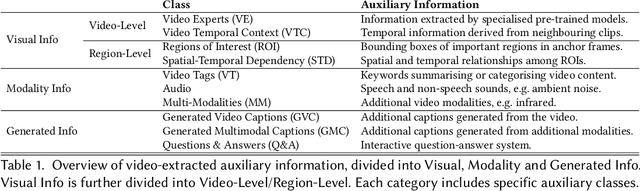


Text-to-Video (T2V) retrieval aims to identify the most relevant item from a gallery of videos based on a user's text query. Traditional methods rely solely on aligning video and text modalities to compute the similarity and retrieve relevant items. However, recent advancements emphasise incorporating auxiliary information extracted from video and text modalities to improve retrieval performance and bridge the semantic gap between these modalities. Auxiliary information can include visual attributes, such as objects; temporal and spatial context; and textual descriptions, such as speech and rephrased captions. This survey comprehensively reviews 81 research papers on Text-to-Video retrieval that utilise such auxiliary information. It provides a detailed analysis of their methodologies; highlights state-of-the-art results on benchmark datasets; and discusses available datasets and their auxiliary information. Additionally, it proposes promising directions for future research, focusing on different ways to further enhance retrieval performance using this information.
The Invisible EgoHand: 3D Hand Forecasting through EgoBody Pose Estimation
Apr 11, 2025Forecasting hand motion and pose from an egocentric perspective is essential for understanding human intention. However, existing methods focus solely on predicting positions without considering articulation, and only when the hands are visible in the field of view. This limitation overlooks the fact that approximate hand positions can still be inferred even when they are outside the camera's view. In this paper, we propose a method to forecast the 3D trajectories and poses of both hands from an egocentric video, both in and out of the field of view. We propose a diffusion-based transformer architecture for Egocentric Hand Forecasting, EgoH4, which takes as input the observation sequence and camera poses, then predicts future 3D motion and poses for both hands of the camera wearer. We leverage full-body pose information, allowing other joints to provide constraints on hand motion. We denoise the hand and body joints along with a visibility predictor for hand joints and a 3D-to-2D reprojection loss that minimizes the error when hands are in-view. We evaluate EgoH4 on the Ego-Exo4D dataset, combining subsets with body and hand annotations. We train on 156K sequences and evaluate on 34K sequences, respectively. EgoH4 improves the performance by 3.4cm and 5.1cm over the baseline in terms of ADE for hand trajectory forecasting and MPJPE for hand pose forecasting. Project page: https://masashi-hatano.github.io/EgoH4/