 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Auxiliary Information in Text-to-Video Retrieval: A Review
May 29, 2025
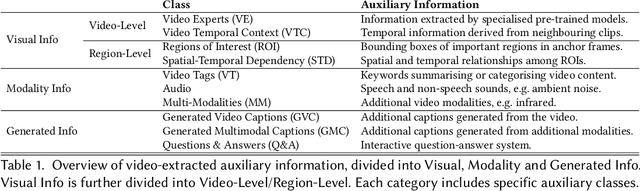


Text-to-Video (T2V) retrieval aims to identify the most relevant item from a gallery of videos based on a user's text query. Traditional methods rely solely on aligning video and text modalities to compute the similarity and retrieve relevant items. However, recent advancements emphasise incorporating auxiliary information extracted from video and text modalities to improve retrieval performance and bridge the semantic gap between these modalities. Auxiliary information can include visual attributes, such as objects; temporal and spatial context; and textual descriptions, such as speech and rephrased captions. This survey comprehensively reviews 81 research papers on Text-to-Video retrieval that utilise such auxiliary information. It provides a detailed analysis of their methodologies; highlights state-of-the-art results on benchmark datasets; and discusses available datasets and their auxiliary information. Additionally, it proposes promising directions for future research, focusing on different ways to further enhance retrieval performance using this information.
Leveraging Modality Tags for Enhanced Cross-Modal Video Retrieval
Apr 03, 2025


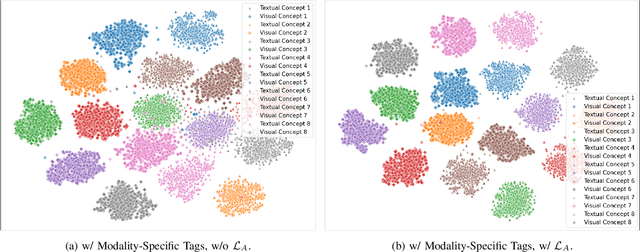
Video retrieval requires aligning visual content with corresponding natural language descriptions. In this paper, we introduce Modality Auxiliary Concepts for Video Retrieval (MAC-VR), a novel approach that leverages modality-specific tags -- automatically extracted from foundation models -- to enhance video retrieval. We propose to align modalities in a latent space, along with learning and aligning auxiliary latent concepts, derived from the features of a video and its corresponding caption. We introduce these auxiliary concepts to improve the alignment of visual and textual latent concepts, and so are able to distinguish concepts from one other. We conduct extensive experiments on five diverse datasets: MSR-VTT, DiDeMo, TGIF, Charades and YouCook2. The experimental results consistently demonstrate that modality-specific tags improve cross-modal alignment, outperforming current state-of-the-art methods across three datasets and performing comparably or better across the other two.
Video Editing for Video Retrieval
Feb 04, 2024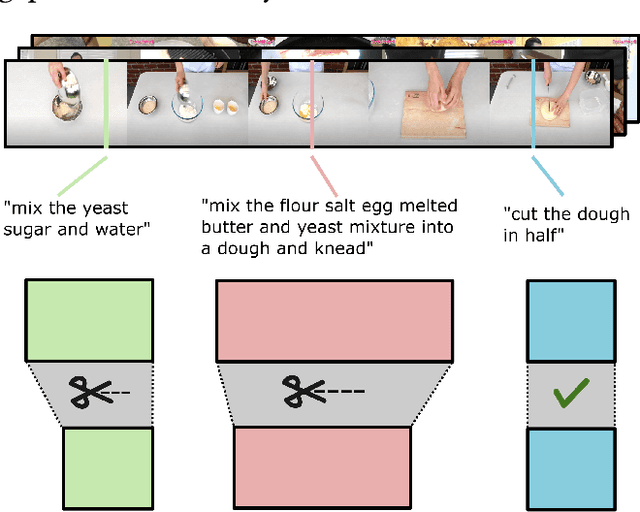
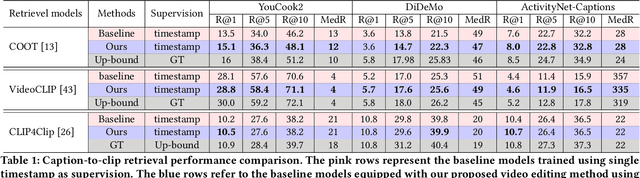
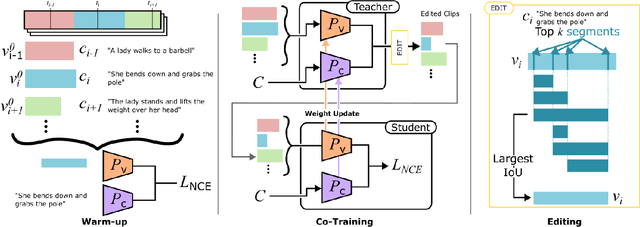
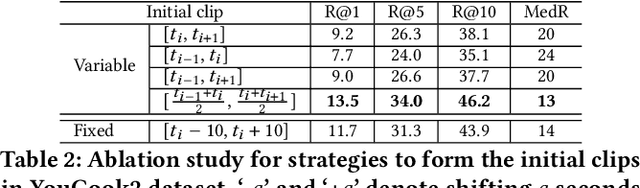
Though pre-training vision-language models have demonstrated significant benefits in boosting video-text retrieval performance from large-scale web videos, fine-tuning still plays a critical role with manually annotated clips with start and end times, which requires considerable human effort. To address this issue, we explore an alternative cheaper source of annotations, single timestamps, for video-text retrieval. We initialise clips from timestamps in a heuristic way to warm up a retrieval model. Then a video clip editing method is proposed to refine the initial rough boundaries to improve retrieval performance. A student-teacher network is introduced for video clip editing. The teacher model is employed to edit the clips in the training set whereas the student model trains on the edited clips. The teacher weights are updated from the student's after the student's performance increases. Our method is model agnostic and applicable to any retrieval models. We conduct experiments based on three state-of-the-art retrieval models, COOT, VideoCLIP and CLIP4Clip. Experiments conducted on three video retrieval datasets, YouCook2, DiDeMo and ActivityNet-Captions show that our edited clips consistently improve retrieval performance over initial clips across all the three retrieval models.
ConTra: text nsformer for Cross-Modal Video Retrieval
Oct 09, 2022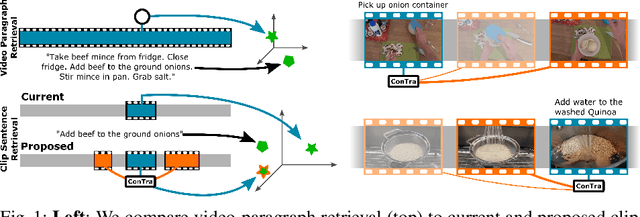
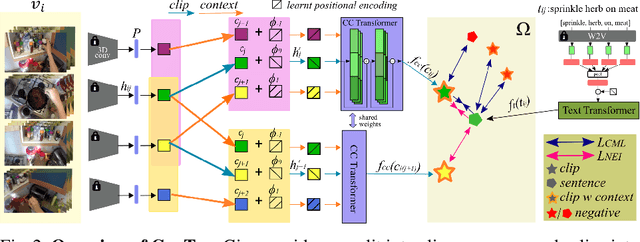
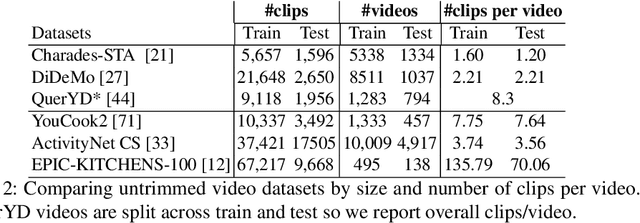
In this paper, we re-examine the task of cross-modal clip-sentence retrieval, where the clip is part of a longer untrimmed video. When the clip is short or visually ambiguous, knowledge of its local temporal context (i.e. surrounding video segments) can be used to improve the retrieval performance. We propose Context Transformer (ConTra); an encoder architecture that models the interaction between a video clip and its local temporal context in order to enhance its embedded representations. Importantly, we supervise the context transformer using contrastive losses in the cross-modal embedding space. We explore context transformers for video and text modalities. Results consistently demonstrate improved performance on three datasets: YouCook2, EPIC-KITCHENS and a clip-sentence version of ActivityNet Captions. Exhaustive ablation studies and context analysis show the efficacy of the proposed method.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021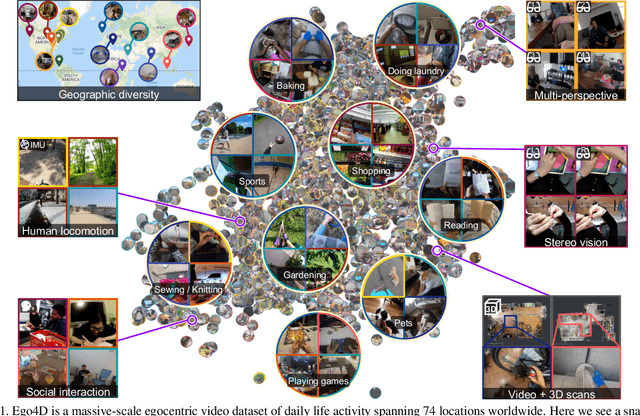
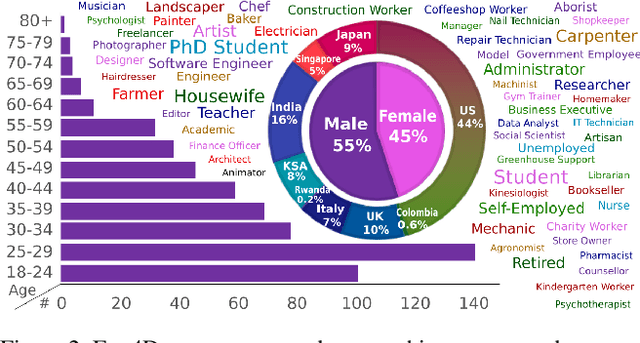

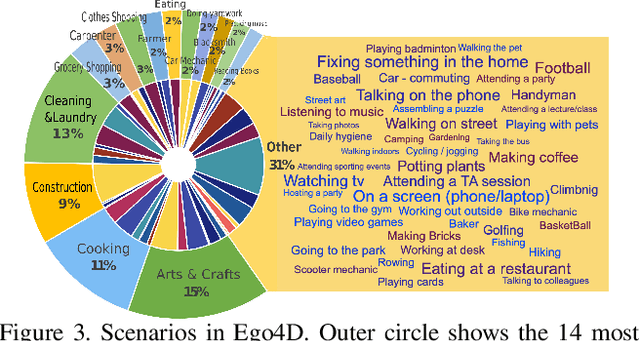
We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
3D Hand Pose and Shape Estimation from RGB Images for Improved Keypoint-Based Hand-Gesture Recognition
Sep 28, 2021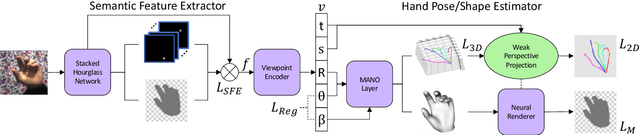

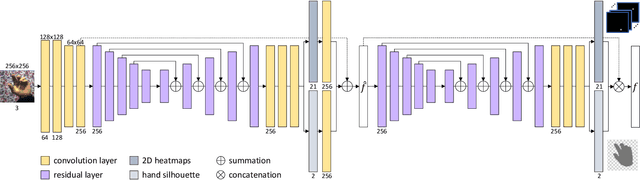
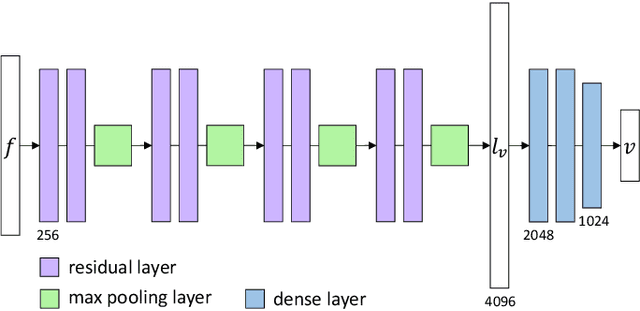
Estimating the 3D hand pose from a 2D image is a well-studied problem and a requirement for several real-life applications such as virtual reality, augmented reality, and hand-gesture recognition. Currently, good estimations can be computed starting from single RGB images, especially when forcing the system to also consider, through a multi-task learning approach, the hand shape when the pose is determined. However, when addressing the aforementioned real-life tasks, performances can drop considerably depending on the hand representation, thus suggesting that stable descriptions are required to achieve satisfactory results. As a consequence, in this paper we present a keypoint-based end-to-end framework for the 3D hand and pose estimation, and successfully apply it to the hand-gesture recognition task as a study case. Specifically, after a pre-processing step where the images are normalized, the proposed pipeline comprises a multi-task semantic feature extractor generating 2D heatmaps and hand silhouettes from RGB images; a viewpoint encoder predicting hand and camera view parameters; a stable hand estimator producing the 3D hand pose and shape; and a loss function designed to jointly guide all of the components during the learning phase. To assess the proposed framework, tests were performed on a 3D pose and shape estimation benchmark dataset, obtaining state-of-the-art performances. What is more, the devised system was also evaluated on 2 hand-gesture recognition benchmark datasets, where the framework significantly outperforms other keypoint-based approaches; indicating that the presented method is an effective solution able to generate stable 3D estimates for the hand pose and shape.