 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Hand Pose and Shape Estimation from RGB Images for Improved Keypoint-Based Hand-Gesture Recognition
Paper and Code
Sep 28, 2021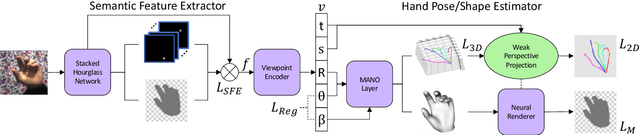

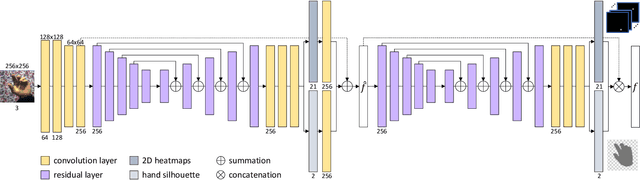
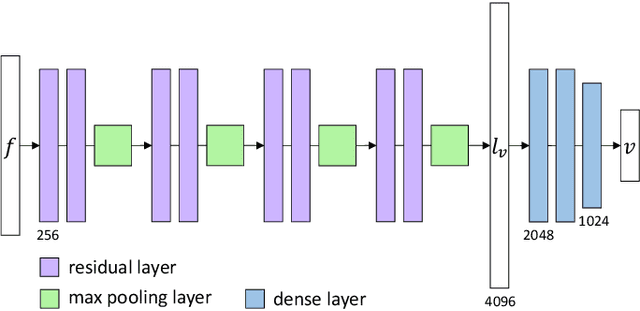
Estimating the 3D hand pose from a 2D image is a well-studied problem and a requirement for several real-life applications such as virtual reality, augmented reality, and hand-gesture recognition. Currently, good estimations can be computed starting from single RGB images, especially when forcing the system to also consider, through a multi-task learning approach, the hand shape when the pose is determined. However, when addressing the aforementioned real-life tasks, performances can drop considerably depending on the hand representation, thus suggesting that stable descriptions are required to achieve satisfactory results. As a consequence, in this paper we present a keypoint-based end-to-end framework for the 3D hand and pose estimation, and successfully apply it to the hand-gesture recognition task as a study case. Specifically, after a pre-processing step where the images are normalized, the proposed pipeline comprises a multi-task semantic feature extractor generating 2D heatmaps and hand silhouettes from RGB images; a viewpoint encoder predicting hand and camera view parameters; a stable hand estimator producing the 3D hand pose and shape; and a loss function designed to jointly guide all of the components during the learning phase. To assess the proposed framework, tests were performed on a 3D pose and shape estimation benchmark dataset, obtaining state-of-the-art performances. What is more, the devised system was also evaluated on 2 hand-gesture recognition benchmark datasets, where the framework significantly outperforms other keypoint-based approaches; indicating that the presented method is an effective solution able to generate stable 3D estimates for the hand pose and shape.