 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICDAR 2025 Competition on FEw-Shot Text line segmentation of ancient handwritten documents (FEST)
Sep 16, 2025Text line segmentation is a critical step in handwritten document image analysis. Segmenting text lines in historical handwritten documents, however, presents unique challenges due to irregular handwriting, faded ink, and complex layouts with overlapping lines and non-linear text flow. Furthermore, the scarcity of large annotated datasets renders fully supervised learning approaches impractical for such materials. To address these challenges, we introduce the Few-Shot Text Line Segmentation of Ancient Handwritten Documents (FEST) Competition. Participants are tasked with developing systems capable of segmenting text lines in U-DIADS-TL dataset, using only three annotated images per manuscript for training. The competition dataset features a diverse collection of ancient manuscripts exhibiting a wide range of layouts, degradation levels, and non-standard formatting, closely reflecting real-world conditions. By emphasizing few-shot learning, FEST competition aims to promote the development of robust and adaptable methods that can be employed by humanities scholars with minimal manual annotation effort, thus fostering broader adoption of automated document analysis tools in historical research.
* Accepted to ICDAR 2025
Digital Shielding for Cross-Domain Wi-Fi Signal Adaptation using Relativistic Average Generative Adversarial Network
Apr 29, 2025Wi-Fi sensing uses radio-frequency signals from Wi-Fi devices to analyze environments, enabling tasks such as tracking people, detecting intrusions, and recognizing gestures. The rise of this technology is driven by the IEEE 802.11bf standard and growing demand for tools that can ensure privacy and operate through obstacles. However, the performance of Wi-Fi sensing is heavily influenced by environmental conditions, especially when extracting spatial and temporal features from the surrounding scene. A key challenge is achieving robust generalization across domains, ensuring stable performance even when the sensing environment changes significantly. This paper introduces a novel deep learning model for cross-domain adaptation of Wi-Fi signals, inspired by physical signal shielding. The model uses a Relativistic average Generative Adversarial Network (RaGAN) with Bidirectional Long Short-Term Memory (Bi-LSTM) architectures for both the generator and discriminator. To simulate physical shielding, an acrylic box lined with electromagnetic shielding fabric was constructed, mimicking a Faraday cage. Wi-Fi signal spectra were collected from various materials both inside (domain-free) and outside (domain-dependent) the box to train the model. A multi-class Support Vector Machine (SVM) was trained on domain-free spectra and tested on signals denoised by the RaGAN. The system achieved 96% accuracy and demonstrated strong material discrimination capabilities, offering potential for use in security applications to identify concealed objects based on their composition.
U-DIADS-Bib: a full and few-shot pixel-precise dataset for document layout analysis of ancient manuscripts
Jan 16, 2024Document Layout Analysis, which is the task of identifying different semantic regions inside of a document page, is a subject of great interest for both computer scientists and humanities scholars as it represents a fundamental step towards further analysis tasks for the former and a powerful tool to improve and facilitate the study of the documents for the latter. However, many of the works currently present in the literature, especially when it comes to the available datasets, fail to meet the needs of both worlds and, in particular, tend to lean towards the needs and common practices of the computer science side, leading to resources that are not representative of the humanities real needs. For this reason, the present paper introduces U-DIADS-Bib, a novel, pixel-precise, non-overlapping and noiseless document layout analysis dataset developed in close collaboration between specialists in the fields of computer vision and humanities. Furthermore, we propose a novel, computer-aided, segmentation pipeline in order to alleviate the burden represented by the time-consuming process of manual annotation, necessary for the generation of the ground truth segmentation maps. Finally, we present a standardized few-shot version of the dataset (U-DIADS-BibFS), with the aim of encouraging the development of models and solutions able to address this task with as few samples as possible, which would allow for more effective use in a real-world scenario, where collecting a large number of segmentations is not always feasible.
Federated Learning for Data and Model Heterogeneity in Medical Imaging
Jul 31, 2023



Federated Learning (FL) is an evolving machine learning method in which multiple clients participate in collaborative learning without sharing their data with each other and the central server. In real-world applications such as hospitals and industries, FL counters the challenges of data heterogeneity and model heterogeneity as an inevitable part of the collaborative training. More specifically, different organizations, such as hospitals, have their own private data and customized models for local training. To the best of our knowledge, the existing methods do not effectively address both problems of model heterogeneity and data heterogeneity in FL. In this paper, we exploit the data and model heterogeneity simultaneously, and propose a method, MDH-FL (Exploiting Model and Data Heterogeneity in FL) to solve such problems to enhance the efficiency of the global model in FL. We use knowledge distillation and a symmetric loss to minimize the heterogeneity and its impact on the model performance. Knowledge distillation is used to solve the problem of model heterogeneity, and symmetric loss tackles with the data and label heterogeneity. We evaluate our method on the medical datasets to conform the real-world scenario of hospitals, and compare with the existing methods. The experimental results demonstrate the superiority of the proposed approach over the other existing methods.
Efficient few-shot learning for pixel-precise handwritten document layout analysis
Oct 27, 2022



Layout analysis is a task of uttermost importance in ancient handwritten document analysis and represents a fundamental step toward the simplification of subsequent tasks such as optical character recognition and automatic transcription. However, many of the approaches adopted to solve this problem rely on a fully supervised learning paradigm. While these systems achieve very good performance on this task, the drawback is that pixel-precise text labeling of the entire training set is a very time-consuming process, which makes this type of information rarely available in a real-world scenario. In the present paper, we address this problem by proposing an efficient few-shot learning framework that achieves performances comparable to current state-of-the-art fully supervised methods on the publicly available DIVA-HisDB dataset.
Masked Transformer for image Anomaly Localization
Oct 27, 2022Image anomaly detection consists in detecting images or image portions that are visually different from the majority of the samples in a dataset. The task is of practical importance for various real-life applications like biomedical image analysis, visual inspection in industrial production, banking, traffic management, etc. Most of the current deep learning approaches rely on image reconstruction: the input image is projected in some latent space and then reconstructed, assuming that the network (mostly trained on normal data) will not be able to reconstruct the anomalous portions. However, this assumption does not always hold. We thus propose a new model based on the Vision Transformer architecture with patch masking: the input image is split in several patches, and each patch is reconstructed only from the surrounding data, thus ignoring the potentially anomalous information contained in the patch itself. We then show that multi-resolution patches and their collective embeddings provide a large improvement in the model's performance compared to the exclusive use of the traditional square patches. The proposed model has been tested on popular anomaly detection datasets such as MVTec and head CT and achieved good results when compared to other state-of-the-art approaches.
Medicinal Boxes Recognition on a Deep Transfer Learning Augmented Reality Mobile Application
Mar 26, 2022



Taking medicines is a fundamental aspect to cure illnesses. However, studies have shown that it can be hard for patients to remember the correct posology. More aggravating, a wrong dosage generally causes the disease to worsen. Although, all relevant instructions for a medicine are summarized in the corresponding patient information leaflet, the latter is generally difficult to navigate and understand. To address this problem and help patients with their medication, in this paper we introduce an augmented reality mobile application that can present to the user important details on the framed medicine. In particular, the app implements an inference engine based on a deep neural network, i.e., a densenet, fine-tuned to recognize a medicinal from its package. Subsequently, relevant information, such as posology or a simplified leaflet, is overlaid on the camera feed to help a patient when taking a medicine. Extensive experiments to select the best hyperparameters were performed on a dataset specifically collected to address this task; ultimately obtaining up to 91.30\% accuracy as well as real-time capabilities.
Analyzing EEG Data with Machine and Deep Learning: A Benchmark
Mar 18, 2022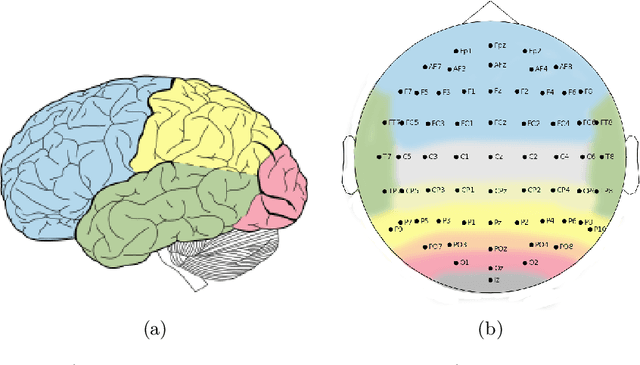


Nowadays, machine and deep learning techniques are widely used in different areas, ranging from economics to biology. In general, these techniques can be used in two ways: trying to adapt well-known models and architectures to the available data, or designing custom architectures. In both cases, to speed up the research process, it is useful to know which type of models work best for a specific problem and/or data type. By focusing on EEG signal analysis, and for the first time in literature, in this paper a benchmark of machine and deep learning for EEG signal classification is proposed. For our experiments we used the four most widespread models, i.e., multilayer perceptron, convolutional neural network, long short-term memory, and gated recurrent unit, highlighting which one can be a good starting point for developing EEG classification models.
Human Silhouette and Skeleton Video Synthesis through Wi-Fi signals
Mar 11, 2022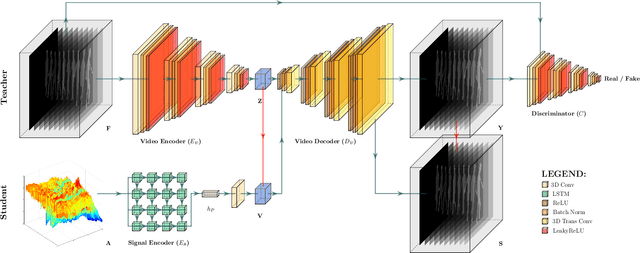
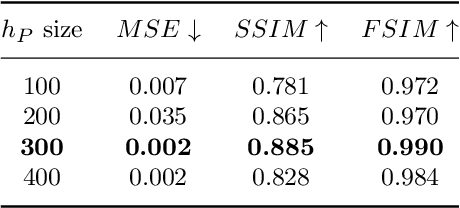
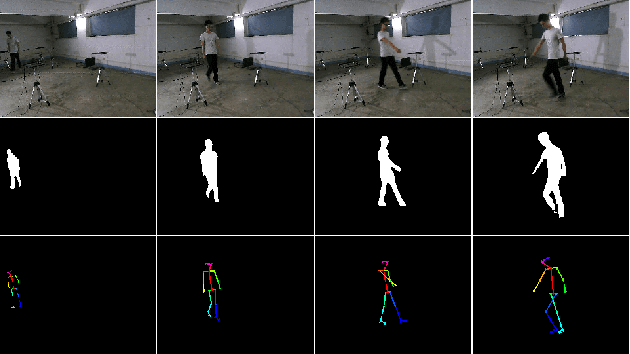
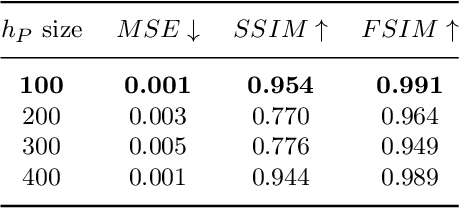
The increasing availability of wireless access points (APs) is leading towards human sensing applications based on Wi-Fi signals as support or alternative tools to the widespread visual sensors, where the signals enable to address well-known vision-related problems such as illumination changes or occlusions. Indeed, using image synthesis techniques to translate radio frequencies to the visible spectrum can become essential to obtain otherwise unavailable visual data. This domain-to-domain translation is feasible because both objects and people affect electromagnetic waves, causing radio and optical frequencies variations. In literature, models capable of inferring radio-to-visual features mappings have gained momentum in the last few years since frequency changes can be observed in the radio domain through the channel state information (CSI) of Wi-Fi APs, enabling signal-based feature extraction, e.g., amplitude. On this account, this paper presents a novel two-branch generative neural network that effectively maps radio data into visual features, following a teacher-student design that exploits a cross-modality supervision strategy. The latter conditions signal-based features in the visual domain to completely replace visual data. Once trained, the proposed method synthesizes human silhouette and skeleton videos using exclusively Wi-Fi signals. The approach is evaluated on publicly available data, where it obtains remarkable results for both silhouette and skeleton videos generation, demonstrating the effectiveness of the proposed cross-modality supervision strategy.
SIRe-Networks: Skip Connections over Interlaced Multi-Task Learning and Residual Connections for Structure Preserving Object Classification
Oct 06, 2021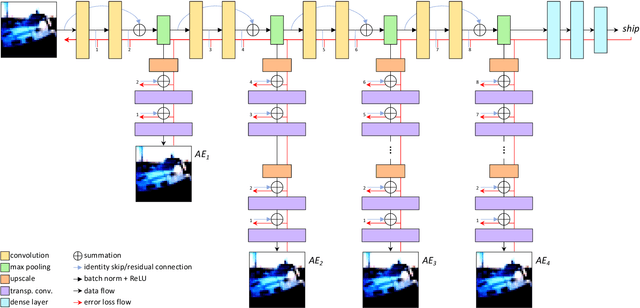
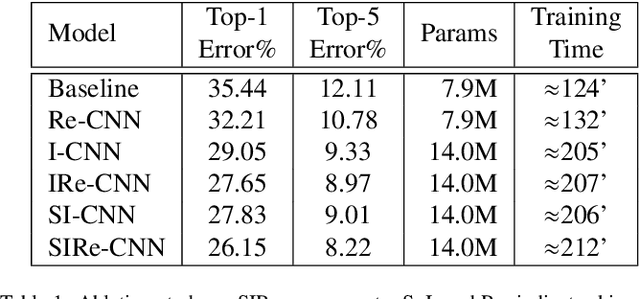

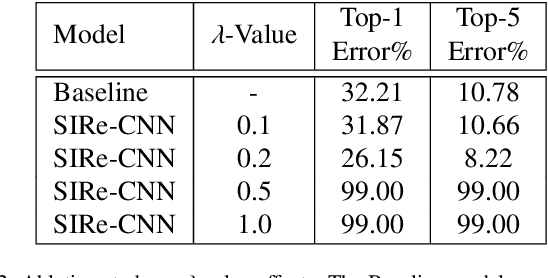
Improving existing neural network architectures can involve several design choices such as manipulating the loss functions, employing a diverse learning strategy, exploiting gradient evolution at training time, optimizing the network hyper-parameters, or increasing the architecture depth. The latter approach is a straightforward solution, since it directly enhances the representation capabilities of a network; however, the increased depth generally incurs in the well-known vanishing gradient problem. In this paper, borrowing from different methods addressing this issue, we introduce an interlaced multi-task learning strategy, defined SIRe, to reduce the vanishing gradient in relation to the object classification task. The presented methodology directly improves a convolutional neural network (CNN) by enforcing the input image structure preservation through interlaced auto-encoders, and further refines the base network architecture by means of skip and residual connections. To validate the presented methodology, a simple CNN and various implementations of famous networks are extended via the SIRe strategy and extensively tested on the CIFAR100 dataset; where the SIRe-extended architectures achieve significantly increased performances across all models, thus confirming the presented approach effectiveness.