 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICDAR 2025 Competition on FEw-Shot Text line segmentation of ancient handwritten documents (FEST)
Sep 16, 2025Text line segmentation is a critical step in handwritten document image analysis. Segmenting text lines in historical handwritten documents, however, presents unique challenges due to irregular handwriting, faded ink, and complex layouts with overlapping lines and non-linear text flow. Furthermore, the scarcity of large annotated datasets renders fully supervised learning approaches impractical for such materials. To address these challenges, we introduce the Few-Shot Text Line Segmentation of Ancient Handwritten Documents (FEST) Competition. Participants are tasked with developing systems capable of segmenting text lines in U-DIADS-TL dataset, using only three annotated images per manuscript for training. The competition dataset features a diverse collection of ancient manuscripts exhibiting a wide range of layouts, degradation levels, and non-standard formatting, closely reflecting real-world conditions. By emphasizing few-shot learning, FEST competition aims to promote the development of robust and adaptable methods that can be employed by humanities scholars with minimal manual annotation effort, thus fostering broader adoption of automated document analysis tools in historical research.
* Accepted to ICDAR 2025
U-DIADS-Bib: a full and few-shot pixel-precise dataset for document layout analysis of ancient manuscripts
Jan 16, 2024Document Layout Analysis, which is the task of identifying different semantic regions inside of a document page, is a subject of great interest for both computer scientists and humanities scholars as it represents a fundamental step towards further analysis tasks for the former and a powerful tool to improve and facilitate the study of the documents for the latter. However, many of the works currently present in the literature, especially when it comes to the available datasets, fail to meet the needs of both worlds and, in particular, tend to lean towards the needs and common practices of the computer science side, leading to resources that are not representative of the humanities real needs. For this reason, the present paper introduces U-DIADS-Bib, a novel, pixel-precise, non-overlapping and noiseless document layout analysis dataset developed in close collaboration between specialists in the fields of computer vision and humanities. Furthermore, we propose a novel, computer-aided, segmentation pipeline in order to alleviate the burden represented by the time-consuming process of manual annotation, necessary for the generation of the ground truth segmentation maps. Finally, we present a standardized few-shot version of the dataset (U-DIADS-BibFS), with the aim of encouraging the development of models and solutions able to address this task with as few samples as possible, which would allow for more effective use in a real-world scenario, where collecting a large number of segmentations is not always feasible.
Masked Transformer for image Anomaly Localization
Oct 27, 2022Image anomaly detection consists in detecting images or image portions that are visually different from the majority of the samples in a dataset. The task is of practical importance for various real-life applications like biomedical image analysis, visual inspection in industrial production, banking, traffic management, etc. Most of the current deep learning approaches rely on image reconstruction: the input image is projected in some latent space and then reconstructed, assuming that the network (mostly trained on normal data) will not be able to reconstruct the anomalous portions. However, this assumption does not always hold. We thus propose a new model based on the Vision Transformer architecture with patch masking: the input image is split in several patches, and each patch is reconstructed only from the surrounding data, thus ignoring the potentially anomalous information contained in the patch itself. We then show that multi-resolution patches and their collective embeddings provide a large improvement in the model's performance compared to the exclusive use of the traditional square patches. The proposed model has been tested on popular anomaly detection datasets such as MVTec and head CT and achieved good results when compared to other state-of-the-art approaches.
Efficient few-shot learning for pixel-precise handwritten document layout analysis
Oct 27, 2022



Layout analysis is a task of uttermost importance in ancient handwritten document analysis and represents a fundamental step toward the simplification of subsequent tasks such as optical character recognition and automatic transcription. However, many of the approaches adopted to solve this problem rely on a fully supervised learning paradigm. While these systems achieve very good performance on this task, the drawback is that pixel-precise text labeling of the entire training set is a very time-consuming process, which makes this type of information rarely available in a real-world scenario. In the present paper, we address this problem by proposing an efficient few-shot learning framework that achieves performances comparable to current state-of-the-art fully supervised methods on the publicly available DIVA-HisDB dataset.
Drone swarm patrolling with uneven coverage requirements
Jul 01, 2021


Swarms of drones are being more and more used in many practical scenarios, such as surveillance, environmental monitoring, search and rescue in hardly-accessible areas, etc.. While a single drone can be guided by a human operator, the deployment of a swarm of multiple drones requires proper algorithms for automatic task-oriented control. In this paper, we focus on visual coverage optimization with drone-mounted camera sensors. In particular, we consider the specific case in which the coverage requirements are uneven, meaning that different parts of the environment have different coverage priorities. We model these coverage requirements with relevance maps and propose a deep reinforcement learning algorithm to guide the swarm. The paper first defines a proper learning model for a single drone, and then extends it to the case of multiple drones both with greedy and cooperative strategies. Experimental results show the performance of the proposed method, also compared with a standard patrolling algorithm.
* This paper has been published on IET Computer Vision. Please cite it accordingly (see journal reference below)
VT-ADL: A Vision Transformer Network for Image Anomaly Detection and Localization
Apr 20, 2021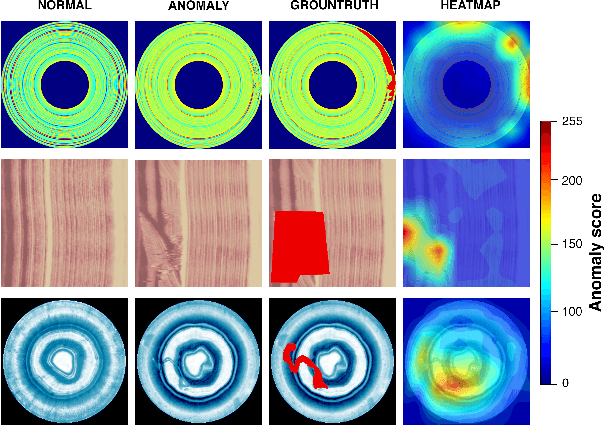
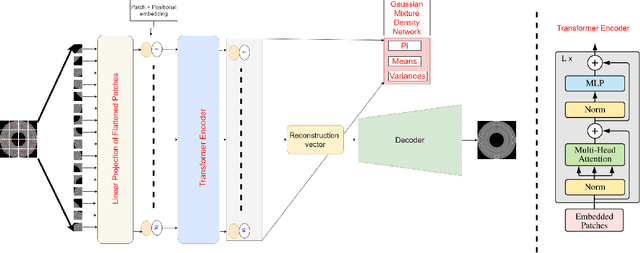

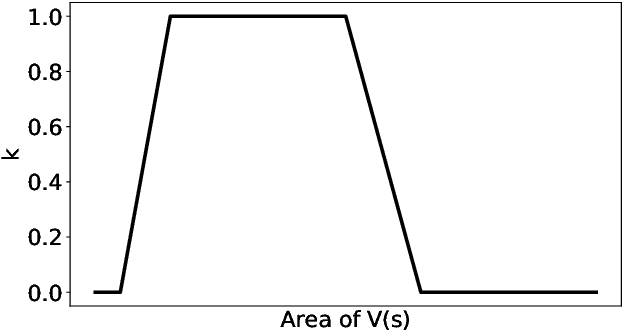
We present a transformer-based image anomaly detection and localization network. Our proposed model is a combination of a reconstruction-based approach and patch embedding. The use of transformer networks helps to preserve the spatial information of the embedded patches, which are later processed by a Gaussian mixture density network to localize the anomalous areas. In addition, we also publish BTAD, a real-world industrial anomaly dataset. Our results are compared with other state-of-the-art algorithms using publicly available datasets like MNIST and MVTec.
* 6 Pages, 4 images, conference published paper
Image Anomaly Detection by Aggregating Deep Pyramidal Representations
Nov 12, 2020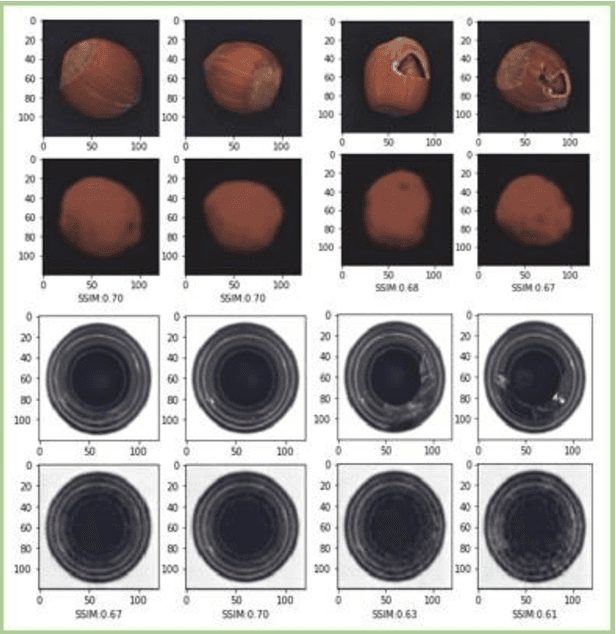
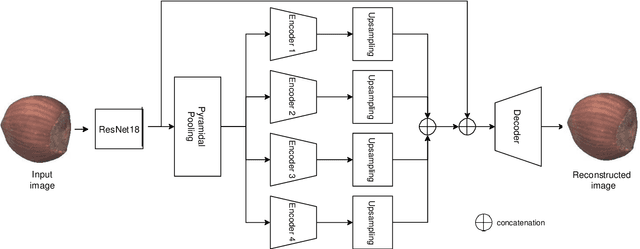
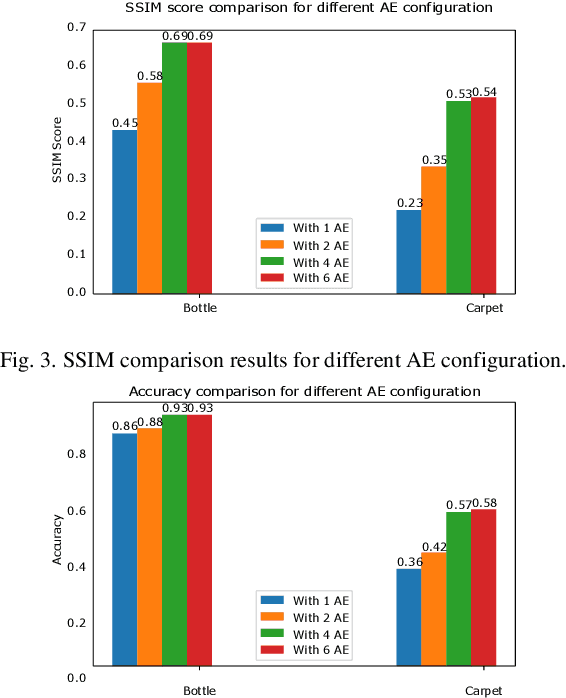
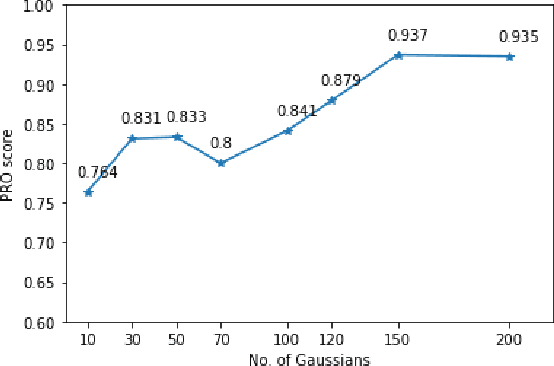
Anomaly detection consists in identifying, within a dataset, those samples that significantly differ from the majority of the data, representing the normal class. It has many practical applications, e.g. ranging from defective product detection in industrial systems to medical imaging. This paper focuses on image anomaly detection using a deep neural network with multiple pyramid levels to analyze the image features at different scales. We propose a network based on encoding-decoding scheme, using a standard convolutional autoencoders, trained on normal data only in order to build a model of normality. Anomalies can be detected by the inability of the network to reconstruct its input. Experimental results show a good accuracy on MNIST, FMNIST and the recent MVTec Anomaly Detection dataset
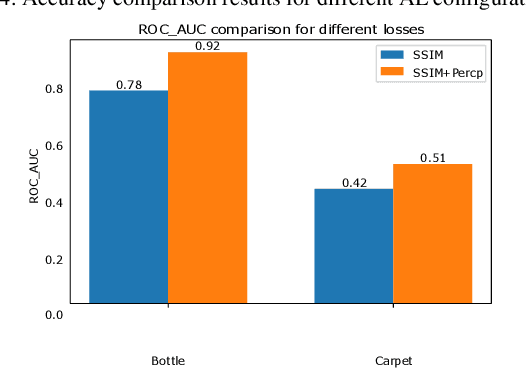
Image anomaly detection with capsule networks and imbalanced datasets
Sep 06, 2019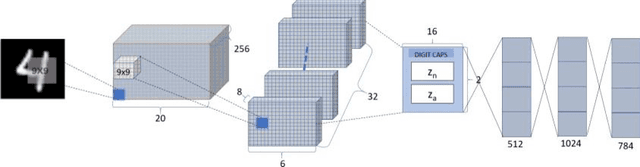

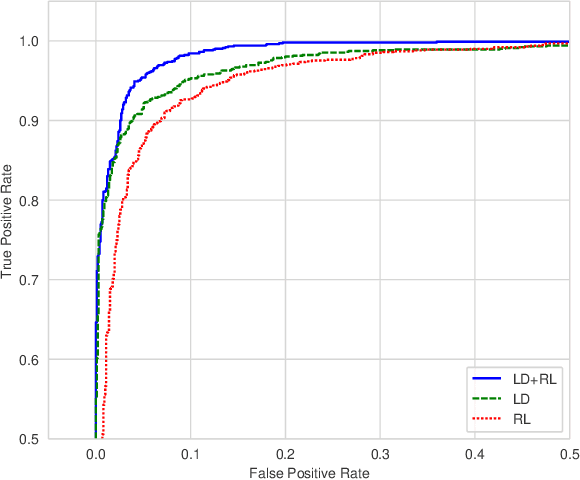
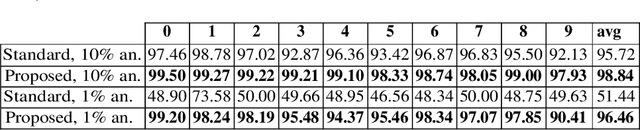
Image anomaly detection consists in finding images with anomalous, unusual patterns with respect to a set of normal data. Anomaly detection can be applied to several fields and has numerous practical applications, e.g. in industrial inspection, medical imaging, security enforcement, etc.. However, anomaly detection techniques often still rely on traditional approaches such as one-class Support Vector Machines, while the topic has not been fully developed yet in the context of modern deep learning approaches. In this paper, we propose an image anomaly detection system based on capsule networks under the assumption that anomalous data are available for training but their amount is scarce.
* Published in conference ICIAP 2019
The UMCD Dataset
Apr 05, 2017



In recent years, the technological improvements of low-cost small-scale Unmanned Aerial Vehicles (UAVs) are promoting an ever-increasing use of them in different tasks. In particular, the use of small-scale UAVs is useful in all these low-altitude tasks in which common UAVs cannot be adopted, such as recurrent comprehensive view of wide environments, frequent monitoring of military areas, real-time classification of static and moving entities (e.g., people, cars, etc.). These tasks can be supported by mosaicking and change detection algorithms achieved at low-altitude. Currently, public datasets for testing these algorithms are not available. This paper presents the UMCD dataset, the first collection of geo-referenced video sequences acquired at low-altitude for mosaicking and change detection purposes. Five reference scenarios are also reported.