 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMAR-DS: Recalibrated Feature Learning for Metal Artifact Reduction and CT Domain Transformation
Jun 24, 2025Artifacts in kilo-Voltage CT (kVCT) imaging degrade image quality, impacting clinical decisions. We propose a deep learning framework for metal artifact reduction (MAR) and domain transformation from kVCT to Mega-Voltage CT (MVCT). The proposed framework, ReMAR-DS, utilizes an encoder-decoder architecture with enhanced feature recalibration, effectively reducing artifacts while preserving anatomical structures. This ensures that only relevant information is utilized in the reconstruction process. By infusing recalibrated features from the encoder block, the model focuses on relevant spatial regions (e.g., areas with artifacts) and highlights key features across channels (e.g., anatomical structures), leading to improved reconstruction of artifact-corrupted regions. Unlike traditional MAR methods, our approach bridges the gap between high-resolution kVCT and artifact-resistant MVCT, enhancing radiotherapy planning. It produces high-quality MVCT-like reconstructions, validated through qualitative and quantitative evaluations. Clinically, this enables oncologists to rely on kVCT alone, reducing repeated high-dose MVCT scans and lowering radiation exposure for cancer patients.
Physics Informed Capsule Enhanced Variational AutoEncoder for Underwater Image Enhancement
Jun 05, 2025We present a novel dual-stream architecture that achieves state-of-the-art underwater image enhancement by explicitly integrating the Jaffe-McGlamery physical model with capsule clustering-based feature representation learning. Our method simultaneously estimates transmission maps and spatially-varying background light through a dedicated physics estimator while extracting entity-level features via capsule clustering in a parallel stream. This physics-guided approach enables parameter-free enhancement that respects underwater formation constraints while preserving semantic structures and fine-grained details. Our approach also features a novel optimization objective ensuring both physical adherence and perceptual quality across multiple spatial frequencies. To validate our approach, we conducted extensive experiments across six challenging benchmarks. Results demonstrate consistent improvements of $+0.5$dB PSNR over the best existing methods while requiring only one-third of their computational complexity (FLOPs), or alternatively, more than $+1$dB PSNR improvement when compared to methods with similar computational budgets. Code and data \textit{will} be available at https://github.com/iN1k1/.
Pyramid-based Mamba Multi-class Unsupervised Anomaly Detection
Apr 04, 2025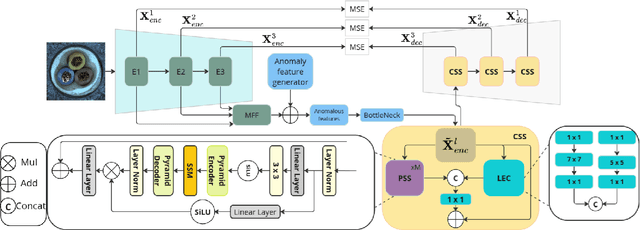
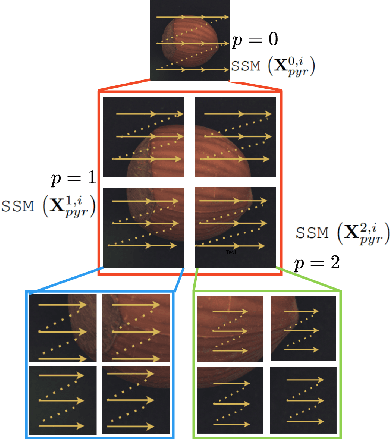
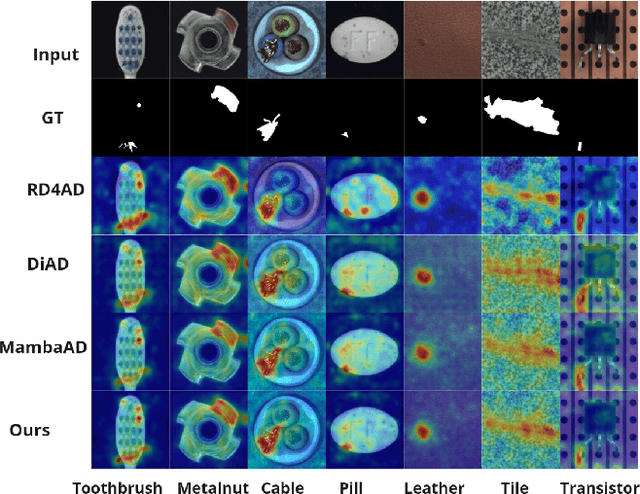
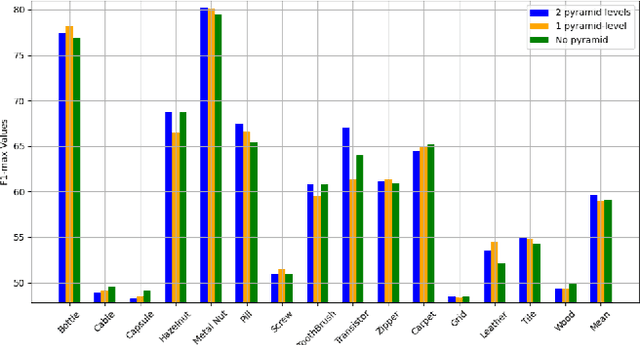
Recent advances in convolutional neural networks (CNNs) and transformer-based methods have improved anomaly detection and localization, but challenges persist in precisely localizing small anomalies. While CNNs face limitations in capturing long-range dependencies, transformer architectures often suffer from substantial computational overheads. We introduce a state space model (SSM)-based Pyramidal Scanning Strategy (PSS) for multi-class anomaly detection and localization--a novel approach designed to address the challenge of small anomaly localization. Our method captures fine-grained details at multiple scales by integrating the PSS with a pre-trained encoder for multi-scale feature extraction and a feature-level synthetic anomaly generator. An improvement of $+1\%$ AP for multi-class anomaly localization and a +$1\%$ increase in AU-PRO on MVTec benchmark demonstrate our method's superiority in precise anomaly localization across diverse industrial scenarios. The code is available at https://github.com/iqbalmlpuniud/Pyramid Mamba.
SkelMamba: A State Space Model for Efficient Skeleton Action Recognition of Neurological Disorders
Nov 29, 2024



We introduce a novel state-space model (SSM)-based framework for skeleton-based human action recognition, with an anatomically-guided architecture that improves state-of-the-art performance in both clinical diagnostics and general action recognition tasks. Our approach decomposes skeletal motion analysis into spatial, temporal, and spatio-temporal streams, using channel partitioning to capture distinct movement characteristics efficiently. By implementing a structured, multi-directional scanning strategy within SSMs, our model captures local joint interactions and global motion patterns across multiple anatomical body parts. This anatomically-aware decomposition enhances the ability to identify subtle motion patterns critical in medical diagnosis, such as gait anomalies associated with neurological conditions. On public action recognition benchmarks, i.e., NTU RGB+D, NTU RGB+D 120, and NW-UCLA, our model outperforms current state-of-the-art methods, achieving accuracy improvements up to $3.2\%$ with lower computational complexity than previous leading transformer-based models. We also introduce a novel medical dataset for motion-based patient neurological disorder analysis to validate our method's potential in automated disease diagnosis.
Capsule Enhanced Variational AutoEncoder for Underwater Image Reconstruction
Jun 03, 2024

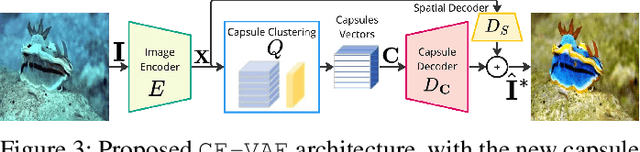
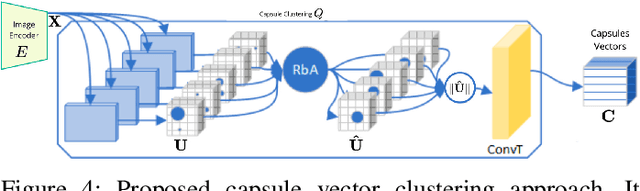
Underwater image analysis is crucial for marine monitoring. However, it presents two major challenges (i) the visual quality of the images is often degraded due to wavelength-dependent light attenuation, scattering, and water types; (ii) capturing and storing high-resolution images is limited by hardware, which hinders long-term environmental analyses. Recently, deep neural networks have been introduced for underwater enhancement yet neglecting the challenge posed by the limitations of autonomous underwater image acquisition systems. We introduce a novel architecture that jointly tackles both issues by drawing inspiration from the discrete features quantization approach of Vector Quantized Variational Autoencoder (\myVQVAE). Our model combines an encoding network, that compresses the input into a latent representation, with two independent decoding networks, that enhance/reconstruct images using only the latent representation. One decoder focuses on the spatial information while the other captures information about the entities in the image by leveraging the concept of capsules. With the usage of capsule layers, we also overcome the differentiabilty issues of \myVQVAE making our solution trainable in an end-to-end fashion without the need for particular optimization tricks. Capsules perform feature quantization in a fully differentiable manner. We conducted thorough quantitative and qualitative evaluations on 6 benchmark datasets to assess the effectiveness of our contributions. Results demonstrate that we perform better than existing methods (eg, about $+1.4dB$ gain on the challenging LSUI Test-L400 dataset), while significantly reducing the amount of space needed for data storage (ie, $3\times$ more efficient).
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024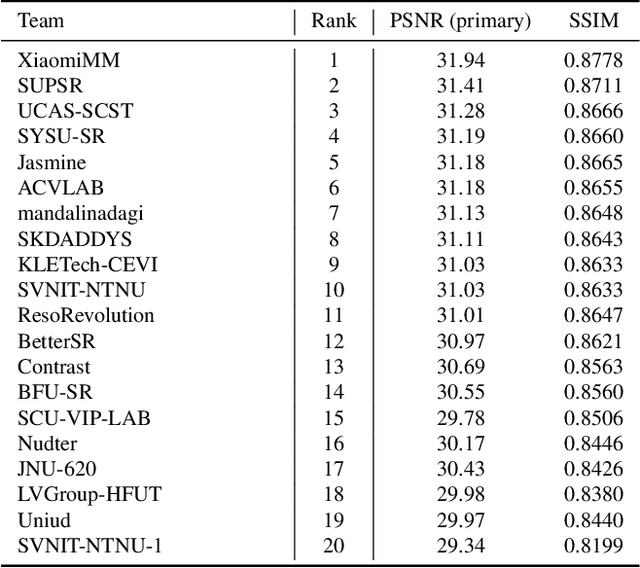
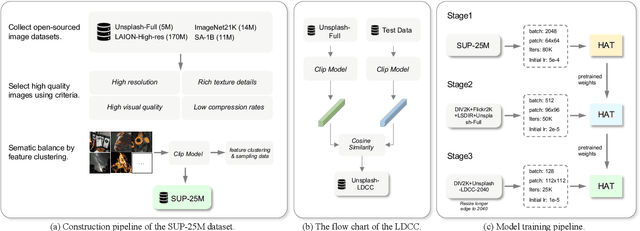
This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
Tracking Skiers from the Top to the Bottom
Dec 15, 2023



Skiing is a popular winter sport discipline with a long history of competitive events. In this domain, computer vision has the potential to enhance the understanding of athletes' performance, but its application lags behind other sports due to limited studies and datasets. This paper makes a step forward in filling such gaps. A thorough investigation is performed on the task of skier tracking in a video capturing his/her complete performance. Obtaining continuous and accurate skier localization is preemptive for further higher-level performance analyses. To enable the study, the largest and most annotated dataset for computer vision in skiing, SkiTB, is introduced. Several visual object tracking algorithms, including both established methodologies and a newly introduced skier-optimized baseline algorithm, are tested using the dataset. The results provide valuable insights into the applicability of different tracking methods for vision-based skiing analysis. SkiTB, code, and results are available at https://machinelearning.uniud.it/datasets/skitb.
UW-CVGAN: UnderWater Image Enhancement with Capsules Vectors Quantization
Feb 02, 2023



The degradation in the underwater images is due to wavelength-dependent light attenuation, scattering, and to the diversity of the water types in which they are captured. Deep neural networks take a step in this field, providing autonomous models able to achieve the enhancement of underwater images. We introduce Underwater Capsules Vectors GAN UWCVGAN based on the discrete features quantization paradigm from VQGAN for this task. The proposed UWCVGAN combines an encoding network, which compresses the image into its latent representation, with a decoding network, able to reconstruct the enhancement of the image from the only latent representation. In contrast with VQGAN, UWCVGAN achieves feature quantization by exploiting the clusterization ability of capsule layer, making the model completely trainable and easier to manage. The model obtains enhanced underwater images with high quality and fine details. Moreover, the trained encoder is independent of the decoder giving the possibility to be embedded onto the collector as compressing algorithm to reduce the memory space required for the images, of factor $3\times$. \myUWCVGAN{ }is validated with quantitative and qualitative analysis on benchmark datasets, and we present metrics results compared with the state of the art.
TUCaN: Progressively Teaching Colourisation to Capsules
Jun 29, 2021

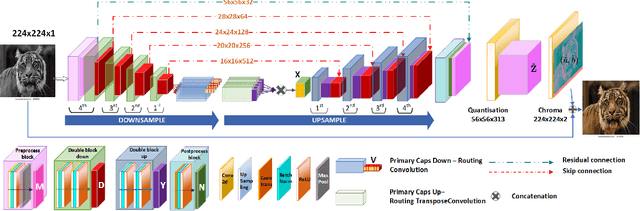

Automatic image colourisation is the computer vision research path that studies how to colourise greyscale images (for restoration). Deep learning techniques improved image colourisation yielding astonishing results. These differ by various factors, such as structural differences, input types, user assistance, etc. Most of them, base the architectural structure on convolutional layers with no emphasis on layers specialised in object features extraction. We introduce a novel downsampling upsampling architecture named TUCaN (Tiny UCapsNet) that exploits the collaboration of convolutional layers and capsule layers to obtain a neat colourisation of entities present in every single image. This is obtained by enforcing collaboration among such layers by skip and residual connections. We pose the problem as a per pixel colour classification task that identifies colours as a bin in a quantized space. To train the network, in contrast with the standard end to end learning method, we propose the progressive learning scheme to extract the context of objects by only manipulating the learning process without changing the model. In this scheme, the upsampling starts from the reconstruction of low resolution images and progressively grows to high resolution images throughout the training phase. Experimental results on three benchmark datasets show that our approach with ImageNet10k dataset outperforms existing methods on standard quality metrics and achieves state of the art performances on image colourisation. We performed a user study to quantify the perceptual realism of the colourisation results demonstrating: that progressive learning let the TUCaN achieve better colours than the end to end scheme; and pointing out the limitations of the existing evaluation metrics.
Weakly-Supervised Domain Adaptation of Deep Regression Trackers via Reinforced Knowledge Distillation
Mar 26, 2021



Deep regression trackers are among the fastest tracking algorithms available, and therefore suitable for real-time robotic applications. However, their accuracy is inadequate in many domains due to distribution shift and overfitting. In this paper we overcome such limitations by presenting the first methodology for domain adaption of such a class of trackers. To reduce the labeling effort we propose a weakly-supervised adaptation strategy, in which reinforcement learning is used to express weak supervision as a scalar application-dependent and temporally-delayed feedback. At the same time, knowledge distillation is employed to guarantee learning stability and to compress and transfer knowledge from more powerful but slower trackers. Extensive experiments on five different robotic vision domains demonstrate the relevance of our methodology. Real-time speed is achieved on embedded devices and on machines without GPUs, while accuracy reaches significant results.