 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapsule Enhanced Variational AutoEncoder for Underwater Image Reconstruction
Paper and Code
Jun 03, 2024

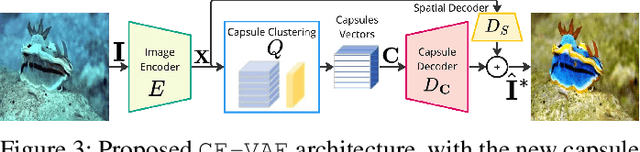
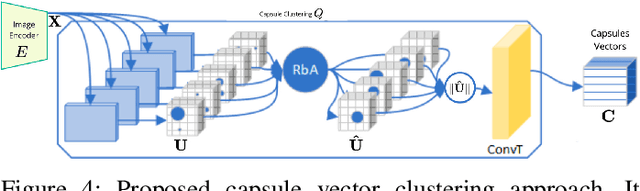
Underwater image analysis is crucial for marine monitoring. However, it presents two major challenges (i) the visual quality of the images is often degraded due to wavelength-dependent light attenuation, scattering, and water types; (ii) capturing and storing high-resolution images is limited by hardware, which hinders long-term environmental analyses. Recently, deep neural networks have been introduced for underwater enhancement yet neglecting the challenge posed by the limitations of autonomous underwater image acquisition systems. We introduce a novel architecture that jointly tackles both issues by drawing inspiration from the discrete features quantization approach of Vector Quantized Variational Autoencoder (\myVQVAE). Our model combines an encoding network, that compresses the input into a latent representation, with two independent decoding networks, that enhance/reconstruct images using only the latent representation. One decoder focuses on the spatial information while the other captures information about the entities in the image by leveraging the concept of capsules. With the usage of capsule layers, we also overcome the differentiabilty issues of \myVQVAE making our solution trainable in an end-to-end fashion without the need for particular optimization tricks. Capsules perform feature quantization in a fully differentiable manner. We conducted thorough quantitative and qualitative evaluations on 6 benchmark datasets to assess the effectiveness of our contributions. Results demonstrate that we perform better than existing methods (eg, about $+1.4dB$ gain on the challenging LSUI Test-L400 dataset), while significantly reducing the amount of space needed for data storage (ie, $3\times$ more efficient).