 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Clustering Capability of Inpainting Model Embeddings for Pattern-based Individual Identification
May 06, 2026In this paper, we explore deep learning techniques for individual identification of animals based on their skin patterns. Individual identification is crucial in biodiversity monitoring, since it enables analysis of decline or growth of populations, or intra-species interactions within populations. Models trained for the task of individual identification often do not focus on the skin pattern of animals, but on background details or body shape details. These characteristics are not individually specific, or can change drastically through time. We focus on techniques that will make machine learning models more responsive to skin pattern structure when extracting individual visual embeddings from images. For this, we explore image inpainting of task-specific masks as an auxiliary task to enhance ML-based individual identification from animal skin patterns. We propose a comparative analysis among four models as an encoder backbone for the individual identification task. We focus on the case study of zebrafish, which is a widely recognized biological model organism, and which exhibits individually identifying skin patterns. To evaluate encoder backbone performance, we present standard metrics for classification accuracy, embedding clustering metrics, and GradCAM visualizations.
Colour Extraction Pipeline for Odonates using Computer Vision
Apr 20, 2026The correlation between insect morphological traits and climate has been documented in physiological studies, but such studies remain limited by the time-consuming nature of the data analysis. In particular, the open source datasets often lack annotations of species' morphological traits, making dedicated annotations campaigns necessary; these efforts are typically local in scale and costly. In this paper, we propose a pipeline to identify and segment body parts of Odonates (dragonflies and damselflies) using deep neural networks, with the ultimate goal of extracting body parts' colouration. The pipeline is trained on a limited annotated dataset and refined with pseudo supervised data. We show that, by using open source images from citizen science platforms, our approach can segment each visible subject (Odonates) into head, thorax, abdomen, and wings and then extract a colour palette for each body part. This will enable large-scale statistical analysis of ecological correlations (e.g., between colouration and climate change, habitat loss, or geolocation) which are crucial for quantifying and assessing ecosystem biodiversity status.
Physics Informed Capsule Enhanced Variational AutoEncoder for Underwater Image Enhancement
Jun 05, 2025We present a novel dual-stream architecture that achieves state-of-the-art underwater image enhancement by explicitly integrating the Jaffe-McGlamery physical model with capsule clustering-based feature representation learning. Our method simultaneously estimates transmission maps and spatially-varying background light through a dedicated physics estimator while extracting entity-level features via capsule clustering in a parallel stream. This physics-guided approach enables parameter-free enhancement that respects underwater formation constraints while preserving semantic structures and fine-grained details. Our approach also features a novel optimization objective ensuring both physical adherence and perceptual quality across multiple spatial frequencies. To validate our approach, we conducted extensive experiments across six challenging benchmarks. Results demonstrate consistent improvements of $+0.5$dB PSNR over the best existing methods while requiring only one-third of their computational complexity (FLOPs), or alternatively, more than $+1$dB PSNR improvement when compared to methods with similar computational budgets. Code and data \textit{will} be available at https://github.com/iN1k1/.
Capsule Enhanced Variational AutoEncoder for Underwater Image Reconstruction
Jun 03, 2024

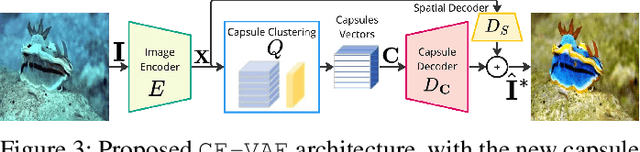
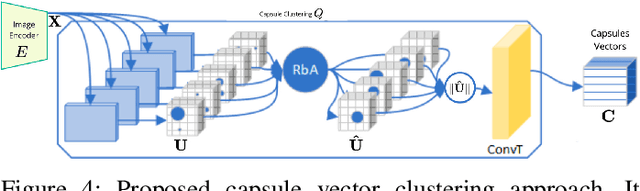
Underwater image analysis is crucial for marine monitoring. However, it presents two major challenges (i) the visual quality of the images is often degraded due to wavelength-dependent light attenuation, scattering, and water types; (ii) capturing and storing high-resolution images is limited by hardware, which hinders long-term environmental analyses. Recently, deep neural networks have been introduced for underwater enhancement yet neglecting the challenge posed by the limitations of autonomous underwater image acquisition systems. We introduce a novel architecture that jointly tackles both issues by drawing inspiration from the discrete features quantization approach of Vector Quantized Variational Autoencoder (\myVQVAE). Our model combines an encoding network, that compresses the input into a latent representation, with two independent decoding networks, that enhance/reconstruct images using only the latent representation. One decoder focuses on the spatial information while the other captures information about the entities in the image by leveraging the concept of capsules. With the usage of capsule layers, we also overcome the differentiabilty issues of \myVQVAE making our solution trainable in an end-to-end fashion without the need for particular optimization tricks. Capsules perform feature quantization in a fully differentiable manner. We conducted thorough quantitative and qualitative evaluations on 6 benchmark datasets to assess the effectiveness of our contributions. Results demonstrate that we perform better than existing methods (eg, about $+1.4dB$ gain on the challenging LSUI Test-L400 dataset), while significantly reducing the amount of space needed for data storage (ie, $3\times$ more efficient).
Performance of computer vision algorithms for fine-grained classification using crowdsourced insect images
Apr 04, 2024
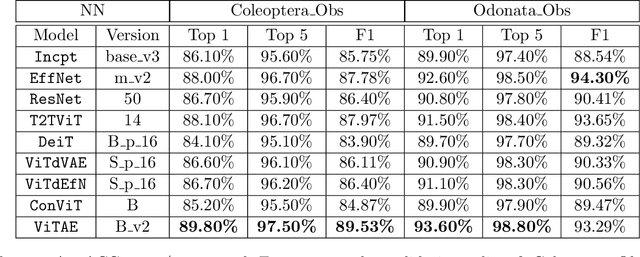

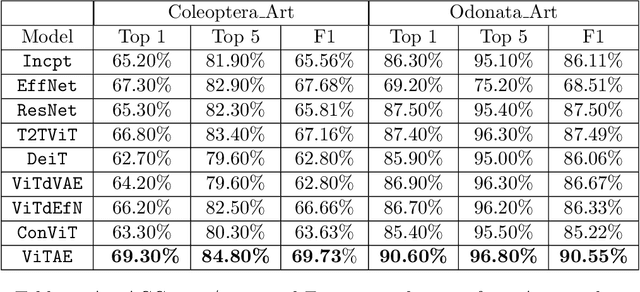
With fine-grained classification, we identify unique characteristics to distinguish among classes of the same super-class. We are focusing on species recognition in Insecta, as they are critical for biodiversity monitoring and at the base of many ecosystems. With citizen science campaigns, billions of images are collected in the wild. Once these are labelled, experts can use them to create distribution maps. However, the labelling process is time-consuming, which is where computer vision comes in. The field of computer vision offers a wide range of algorithms, each with its strengths and weaknesses; how do we identify the algorithm that is in line with our application? To answer this question, we provide a full and detailed evaluation of nine algorithms among deep convolutional networks (CNN), vision transformers (ViT), and locality-based vision transformers (LBVT) on 4 different aspects: classification performance, embedding quality, computational cost, and gradient activity. We offer insights that we haven't yet had in this domain proving to which extent these algorithms solve the fine-grained tasks in Insecta. We found that the ViT performs the best on inference speed and computational cost while the LBVT outperforms the others on performance and embedding quality; the CNN provide a trade-off among the metrics.
Comparison between transformers and convolutional models for fine-grained classification of insects
Jul 20, 2023Fine-grained classification is challenging due to the difficulty of finding discriminatory features. This problem is exacerbated when applied to identifying species within the same taxonomical class. This is because species are often sharing morphological characteristics that make them difficult to differentiate. We consider the taxonomical class of Insecta. The identification of insects is essential in biodiversity monitoring as they are one of the inhabitants at the base of many ecosystems. Citizen science is doing brilliant work of collecting images of insects in the wild giving the possibility to experts to create improved distribution maps in all countries. We have billions of images that need to be automatically classified and deep neural network algorithms are one of the main techniques explored for fine-grained tasks. At the SOTA, the field of deep learning algorithms is extremely fruitful, so how to identify the algorithm to use? We focus on Odonata and Coleoptera orders, and we propose an initial comparative study to analyse the two best-known layer structures for computer vision: transformer and convolutional layers. We compare the performance of T2TViT, a fully transformer-base, EfficientNet, a fully convolutional-base, and ViTAE, a hybrid. We analyse the performance of the three models in identical conditions evaluating the performance per species, per morph together with sex, the inference time, and the overall performance with unbalanced datasets of images from smartphones. Although we observe high performances with all three families of models, our analysis shows that the hybrid model outperforms the fully convolutional-base and fully transformer-base models on accuracy performance and the fully transformer-base model outperforms the others on inference speed and, these prove the transformer to be robust to the shortage of samples and to be faster at inference time.
UW-ProCCaps: UnderWater Progressive Colourisation with Capsules
Jul 03, 2023

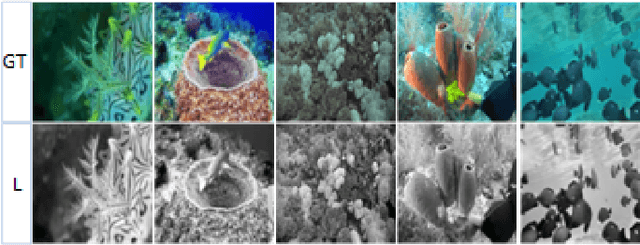

Underwater images are fundamental for studying and understanding the status of marine life. We focus on reducing the memory space required for image storage while the memory space consumption in the collecting phase limits the time lasting of this phase leading to the need for more image collection campaigns. We present a novel machine-learning model that reconstructs the colours of underwater images from their luminescence channel, thus saving 2/3 of the available storage space. Our model specialises in underwater colour reconstruction and consists of an encoder-decoder architecture. The encoder is composed of a convolutional encoder and a parallel specialised classifier trained with webly-supervised data. The encoder and the decoder use layers of capsules to capture the features of the entities in the image. The colour reconstruction process recalls the progressive and the generative adversarial training procedures. The progressive training gives the ground for a generative adversarial routine focused on the refining of colours giving the image bright and saturated colours which bring the image back to life. We validate the model both qualitatively and quantitatively on four benchmark datasets. This is the first attempt at colour reconstruction in greyscale underwater images. Extensive results on four benchmark datasets demonstrate that our solution outperforms state-of-the-art (SOTA) solutions. We also demonstrate that the generated colourisation enhances the quality of images compared to enhancement models at the SOTA.
UW-CVGAN: UnderWater Image Enhancement with Capsules Vectors Quantization
Feb 02, 2023



The degradation in the underwater images is due to wavelength-dependent light attenuation, scattering, and to the diversity of the water types in which they are captured. Deep neural networks take a step in this field, providing autonomous models able to achieve the enhancement of underwater images. We introduce Underwater Capsules Vectors GAN UWCVGAN based on the discrete features quantization paradigm from VQGAN for this task. The proposed UWCVGAN combines an encoding network, which compresses the image into its latent representation, with a decoding network, able to reconstruct the enhancement of the image from the only latent representation. In contrast with VQGAN, UWCVGAN achieves feature quantization by exploiting the clusterization ability of capsule layer, making the model completely trainable and easier to manage. The model obtains enhanced underwater images with high quality and fine details. Moreover, the trained encoder is independent of the decoder giving the possibility to be embedded onto the collector as compressing algorithm to reduce the memory space required for the images, of factor $3\times$. \myUWCVGAN{ }is validated with quantitative and qualitative analysis on benchmark datasets, and we present metrics results compared with the state of the art.
TUCaN: Progressively Teaching Colourisation to Capsules
Jun 29, 2021

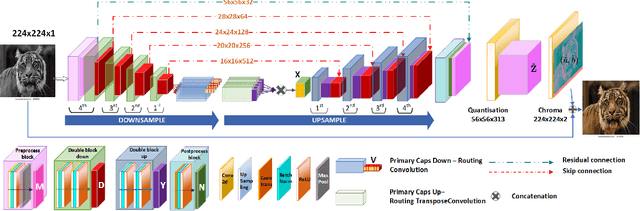

Automatic image colourisation is the computer vision research path that studies how to colourise greyscale images (for restoration). Deep learning techniques improved image colourisation yielding astonishing results. These differ by various factors, such as structural differences, input types, user assistance, etc. Most of them, base the architectural structure on convolutional layers with no emphasis on layers specialised in object features extraction. We introduce a novel downsampling upsampling architecture named TUCaN (Tiny UCapsNet) that exploits the collaboration of convolutional layers and capsule layers to obtain a neat colourisation of entities present in every single image. This is obtained by enforcing collaboration among such layers by skip and residual connections. We pose the problem as a per pixel colour classification task that identifies colours as a bin in a quantized space. To train the network, in contrast with the standard end to end learning method, we propose the progressive learning scheme to extract the context of objects by only manipulating the learning process without changing the model. In this scheme, the upsampling starts from the reconstruction of low resolution images and progressively grows to high resolution images throughout the training phase. Experimental results on three benchmark datasets show that our approach with ImageNet10k dataset outperforms existing methods on standard quality metrics and achieves state of the art performances on image colourisation. We performed a user study to quantify the perceptual realism of the colourisation results demonstrating: that progressive learning let the TUCaN achieve better colours than the end to end scheme; and pointing out the limitations of the existing evaluation metrics.
Collaboration among Image and Object Level Features for Image Colourisation
Jan 19, 2021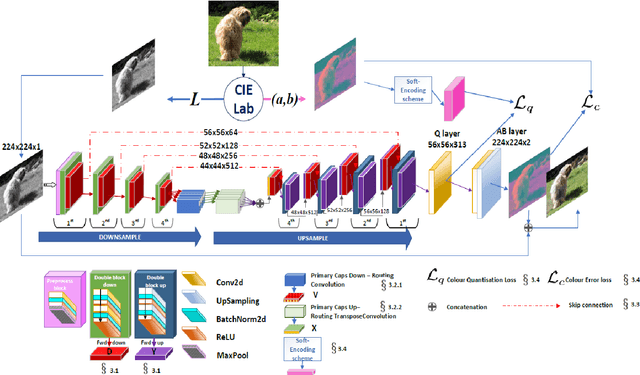
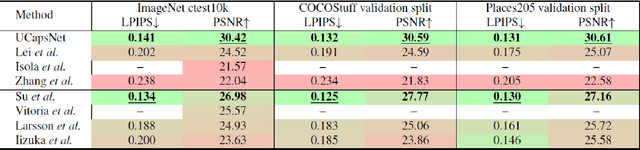

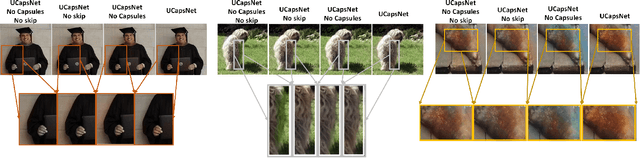
Image colourisation is an ill-posed problem, with multiple correct solutions which depend on the context and object instances present in the input datum. Previous approaches attacked the problem either by requiring intense user interactions or by exploiting the ability of convolutional neural networks (CNNs) in learning image level (context) features. However, obtaining human hints is not always feasible and CNNs alone are not able to learn object-level semantics unless multiple models pretrained with supervision are considered. In this work, we propose a single network, named UCapsNet, that separate image-level features obtained through convolutions and object-level features captured by means of capsules. Then, by skip connections over different layers, we enforce collaboration between such disentangling factors to produce high quality and plausible image colourisation. We pose the problem as a classification task that can be addressed by a fully self-supervised approach, thus requires no human effort. Experimental results on three benchmark datasets show that our approach outperforms existing methods on standard quality metrics and achieves a state of the art performances on image colourisation. A large scale user study shows that our method is preferred over existing solutions.