 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Model Inversion through End-to-End Differentiation
Feb 11, 2026Despite emerging research on Language Models (LM), few approaches analyse the invertibility of LMs. That is, given a LM and a desirable target output sequence of tokens, determining what input prompts would yield the target output remains an open problem. We formulate this problem as a classical gradient-based optimisation. First, we propose a simple algorithm to achieve end-to-end differentiability of a given (frozen) LM and then find optimised prompts via gradient descent. Our central insight is to view LMs as functions operating on sequences of distributions over tokens (rather than the traditional view as functions on sequences of tokens). Our experiments and ablations demonstrate that our DLM-powered inversion can reliably and efficiently optimise prompts of lengths $10$ and $80$ for targets of length $20$, for several white-box LMs (out-of-the-box).
Discovering High Level Patterns from Simulation Traces
Feb 10, 2026Artificial intelligence (AI) agents embedded in environments with physics-based interaction face many challenges including reasoning, planning, summarization, and question answering. This problem is exacerbated when a human user wishes to either guide or interact with the agent in natural language. Although the use of Language Models (LMs) is the default choice, as an AI tool, they struggle with tasks involving physics. The LM's capability for physical reasoning is learned from observational data, rather than being grounded in simulation. A common approach is to include simulation traces as context, but this suffers from poor scalability as simulation traces contain larger volumes of fine-grained numerical and semantic data. In this paper, we propose a natural language guided method to discover coarse-grained patterns (e.g., 'rigid-body collision', 'stable support', etc.) from detailed simulation logs. Specifically, we synthesize programs that operate on simulation logs and map them to a series of high level activated patterns. We show, through two physics benchmarks, that this annotated representation of the simulation log is more amenable to natural language reasoning about physical systems. We demonstrate how this method enables LMs to generate effective reward programs from goals specified in natural language, which may be used within the context of planning or supervised learning.
PAOLI: Pose-free Articulated Object Learning from Sparse-view Images
Sep 04, 2025We present a novel self-supervised framework for learning articulated object representations from sparse-view, unposed images. Unlike prior methods that require dense multi-view observations and ground-truth camera poses, our approach operates with as few as four views per articulation and no camera supervision. To address the inherent challenges, we first reconstruct each articulation independently using recent advances in sparse-view 3D reconstruction, then learn a deformation field that establishes dense correspondences across poses. A progressive disentanglement strategy further separates static from moving parts, enabling robust separation of camera and object motion. Finally, we jointly optimize geometry, appearance, and kinematics with a self-supervised loss that enforces cross-view and cross-pose consistency. Experiments on the standard benchmark and real-world examples demonstrate that our method produces accurate and detailed articulated object representations under significantly weaker input assumptions than existing approaches.
CueTip: An Interactive and Explainable Physics-aware Pool Assistant
Jan 30, 2025We present an interactive and explainable automated coaching assistant called CueTip for a variant of pool/billiards. CueTip's novelty lies in its combination of three features: a natural-language interface, an ability to perform contextual, physics-aware reasoning, and that its explanations are rooted in a set of predetermined guidelines developed by domain experts. We instrument a physics simulator so that it generates event traces in natural language alongside traditional state traces. Event traces lend themselves to interpretation by language models, which serve as the interface to our assistant. We design and train a neural adaptor that decouples tactical choices made by CueTip from its interactivity and explainability allowing it to be reconfigured to mimic any pool playing agent. Our experiments show that CueTip enables contextual query-based assistance and explanations while maintaining the strength of the agent in terms of win rate (improving it in some situations). The explanations generated by CueTip are physically-aware and grounded in the expert rules and are therefore more reliable.
Articulate your NeRF: Unsupervised articulated object modeling via conditional view synthesis
Jun 24, 2024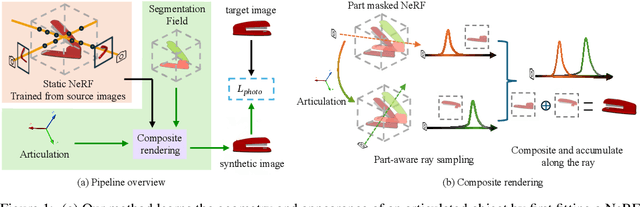
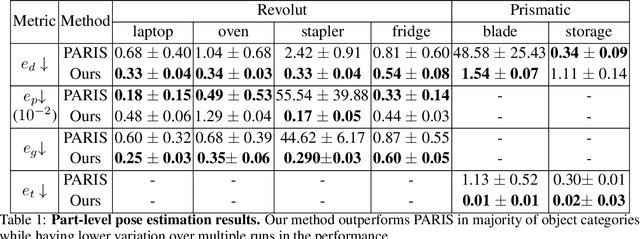
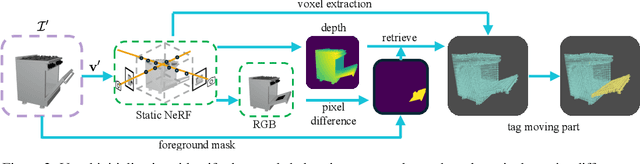
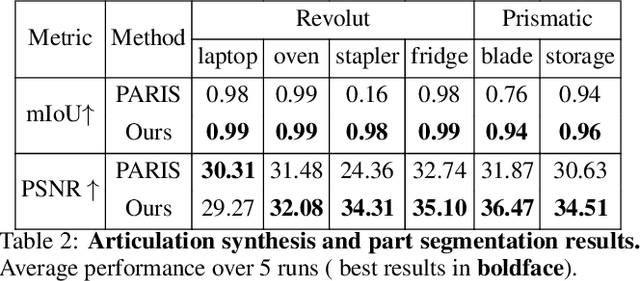
We propose a novel unsupervised method to learn the pose and part-segmentation of articulated objects with rigid parts. Given two observations of an object in different articulation states, our method learns the geometry and appearance of object parts by using an implicit model from the first observation, distils the part segmentation and articulation from the second observation while rendering the latter observation. Additionally, to tackle the complexities in the joint optimization of part segmentation and articulation, we propose a voxel grid-based initialization strategy and a decoupled optimization procedure. Compared to the prior unsupervised work, our model obtains significantly better performance, and generalizes to objects with multiple parts while it can be efficiently from few views for the latter observation.
SimLM: Can Language Models Infer Parameters of Physical Systems?
Dec 21, 2023Recent developments in large-scale machine learning models for general-purpose understanding, translation and generation of language are driving impact across a variety of sectors including medicine, robotics, and scientific discovery. The strength of such Large Language Models (LLMs) stems from the large corpora that they are trained with. While this imbues them with a breadth of capabilities, they have been found unsuitable for some specific types of problems such as advanced mathematics. In this paper, we highlight the inability of LLMs to reason about physics tasks. We demonstrate that their ability to infer parameters of physical systems can be improved, without retraining, by augmenting their context with feedback from physical simulation.
Generating Parametric BRDFs from Natural Language Descriptions
Jun 19, 2023Artistic authoring of 3D environments is a laborious enterprise that also requires skilled content creators. There have been impressive improvements in using machine learning to address different aspects of generating 3D content, such as generating meshes, arranging geometry, synthesizing textures, etc. In this paper we develop a model to generate Bidirectional Reflectance Distribution Functions (BRDFs) from descriptive textual prompts. BRDFs are four dimensional probability distributions that characterize the interaction of light with surface materials. They are either represented parametrically, or by tabulating the probability density associated with every pair of incident and outgoing angles. The former lends itself to artistic editing while the latter is used when measuring the appearance of real materials. Numerous works have focused on hypothesizing BRDF models from images of materials. We learn a mapping from textual descriptions of materials to parametric BRDFs. Our model is first trained using a semi-supervised approach before being tuned via an unsupervised scheme. Although our model is general, in this paper we specifically generate parameters for MDL materials, conditioned on natural language descriptions, within NVIDIA's Omniverse platform. This enables use cases such as real-time text prompts to change materials of objects in 3D environments such as "dull plastic" or "shiny iron". Since the output of our model is a parametric BRDF, rather than an image of the material, it may be used to render materials using any shape under arbitrarily specified viewing and lighting conditions.
Dist2Cycle: A Simplicial Neural Network for Homology Localization
Oct 28, 2021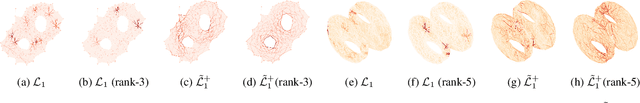
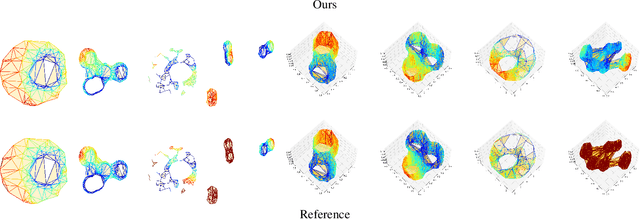
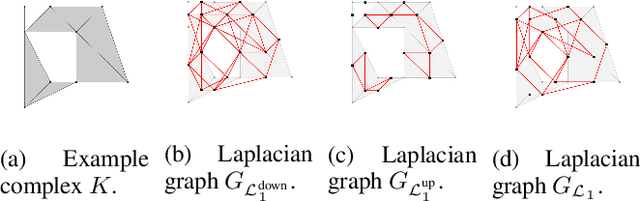
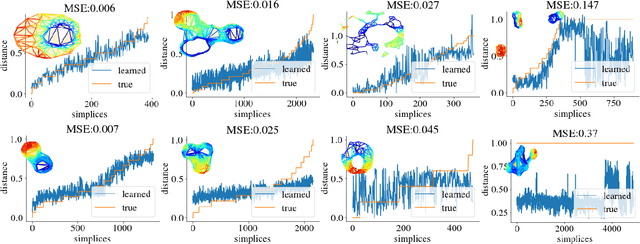
Simplicial complexes can be viewed as high dimensional generalizations of graphs that explicitly encode multi-way ordered relations between vertices at different resolutions, all at once. This concept is central towards detection of higher dimensional topological features of data, features to which graphs, encoding only pairwise relationships, remain oblivious. While attempts have been made to extend Graph Neural Networks (GNNs) to a simplicial complex setting, the methods do not inherently exploit, or reason about, the underlying topological structure of the network. We propose a graph convolutional model for learning functions parametrized by the $k$-homological features of simplicial complexes. By spectrally manipulating their combinatorial $k$-dimensional Hodge Laplacians, the proposed model enables learning topological features of the underlying simplicial complexes, specifically, the distance of each $k$-simplex from the nearest "optimal" $k$-th homology generator, effectively providing an alternative to homology localization.
PDBench: Evaluating Computational Methods for Protein Sequence Design
Sep 28, 2021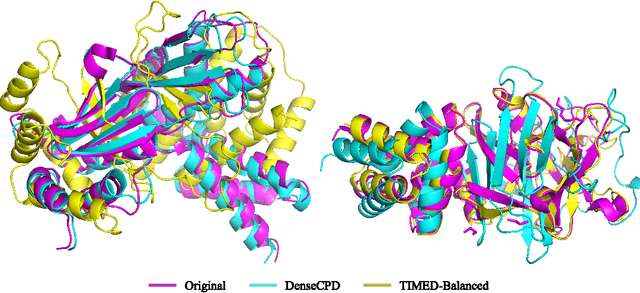
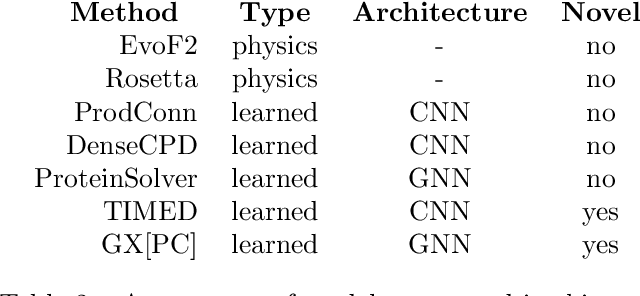
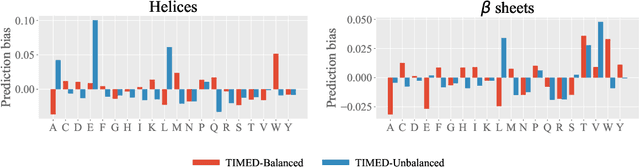

Proteins perform critical processes in all living systems: converting solar energy into chemical energy, replicating DNA, as the basis of highly performant materials, sensing and much more. While an incredible range of functionality has been sampled in nature, it accounts for a tiny fraction of the possible protein universe. If we could tap into this pool of unexplored protein structures, we could search for novel proteins with useful properties that we could apply to tackle the environmental and medical challenges facing humanity. This is the purpose of protein design. Sequence design is an important aspect of protein design, and many successful methods to do this have been developed. Recently, deep-learning methods that frame it as a classification problem have emerged as a powerful approach. Beyond their reported improvement in performance, their primary advantage over physics-based methods is that the computational burden is shifted from the user to the developers, thereby increasing accessibility to the design method. Despite this trend, the tools for assessment and comparison of such models remain quite generic. The goal of this paper is to both address the timely problem of evaluation and to shine a spotlight, within the Machine Learning community, on specific assessment criteria that will accelerate impact. We present a carefully curated benchmark set of proteins and propose a number of standard tests to assess the performance of deep learning based methods. Our robust benchmark provides biological insight into the behaviour of design methods, which is essential for evaluating their performance and utility. We compare five existing models with two novel models for sequence prediction. Finally, we test the designs produced by these models with AlphaFold2, a state-of-the-art structure-prediction algorithm, to determine if they are likely to fold into the intended 3D shapes.
IV-Posterior: Inverse Value Estimation for Interpretable Policy Certificates
Nov 30, 2020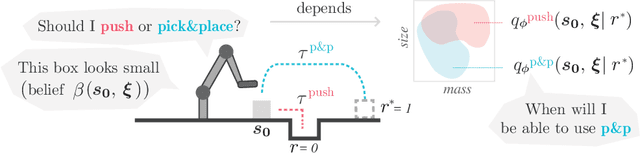
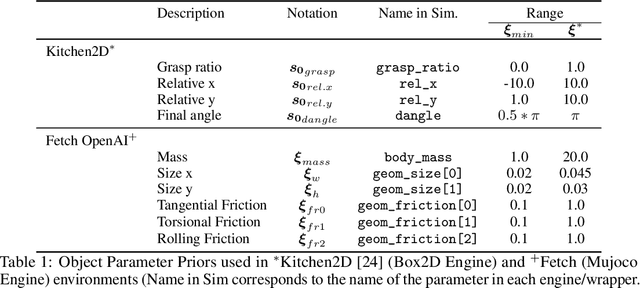
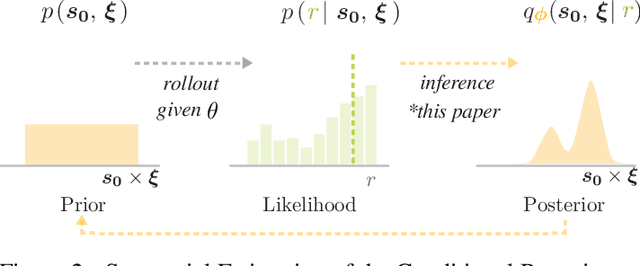
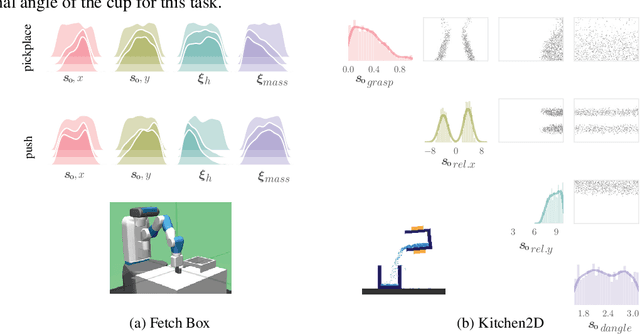
Model-free reinforcement learning (RL) is a powerful tool to learn a broad range of robot skills and policies. However, a lack of policy interpretability can inhibit their successful deployment in downstream applications, particularly when differences in environmental conditions may result in unpredictable behaviour or generalisation failures. As a result, there has been a growing emphasis in machine learning around the inclusion of stronger inductive biases in models to improve generalisation. This paper proposes an alternative strategy, inverse value estimation for interpretable policy certificates (IV-Posterior), which seeks to identify the inductive biases or idealised conditions of operation already held by pre-trained policies, and then use this information to guide their deployment. IV-Posterior uses MaskedAutoregressive Flows to fit distributions over the set of conditions or environmental parameters in which a policy is likely to be effective. This distribution can then be used as a policy certificate in downstream applications. We illustrate the use of IV-Posterior across a two environments, and show that substantial performance gains can be obtained when policy selection incorporates knowledge of the inductive biases that these policies hold.