 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIV-Posterior: Inverse Value Estimation for Interpretable Policy Certificates
Paper and Code
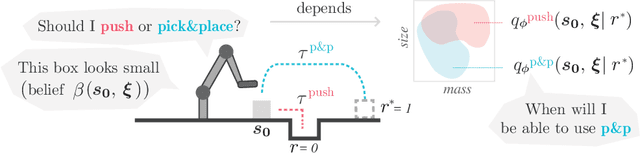
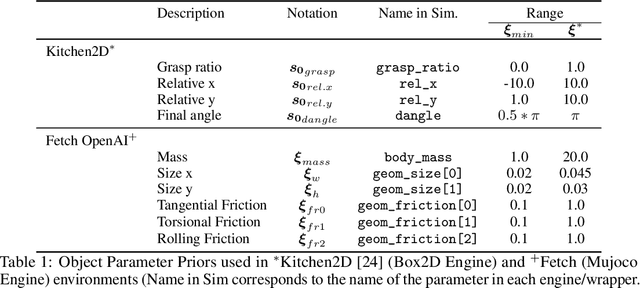
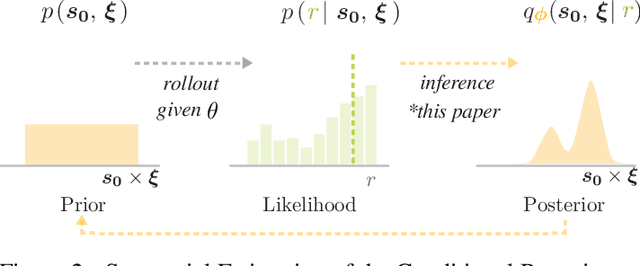
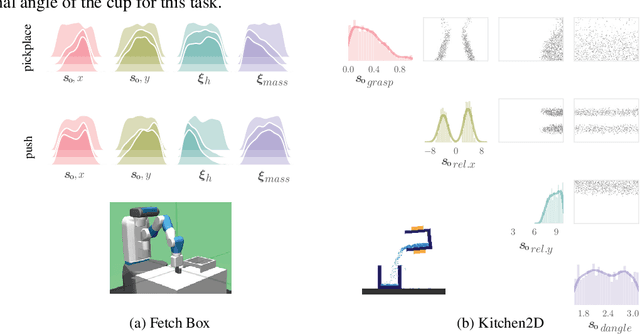
Model-free reinforcement learning (RL) is a powerful tool to learn a broad range of robot skills and policies. However, a lack of policy interpretability can inhibit their successful deployment in downstream applications, particularly when differences in environmental conditions may result in unpredictable behaviour or generalisation failures. As a result, there has been a growing emphasis in machine learning around the inclusion of stronger inductive biases in models to improve generalisation. This paper proposes an alternative strategy, inverse value estimation for interpretable policy certificates (IV-Posterior), which seeks to identify the inductive biases or idealised conditions of operation already held by pre-trained policies, and then use this information to guide their deployment. IV-Posterior uses MaskedAutoregressive Flows to fit distributions over the set of conditions or environmental parameters in which a policy is likely to be effective. This distribution can then be used as a policy certificate in downstream applications. We illustrate the use of IV-Posterior across a two environments, and show that substantial performance gains can be obtained when policy selection incorporates knowledge of the inductive biases that these policies hold.