 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to track environment state via predictive autoencoding
Dec 14, 2021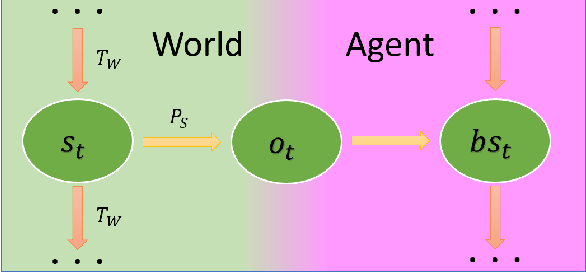
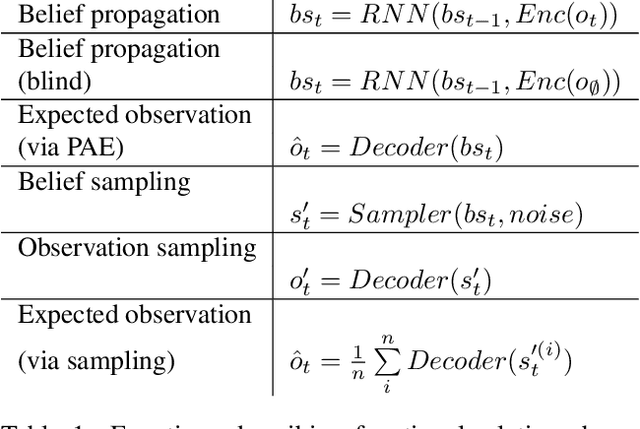
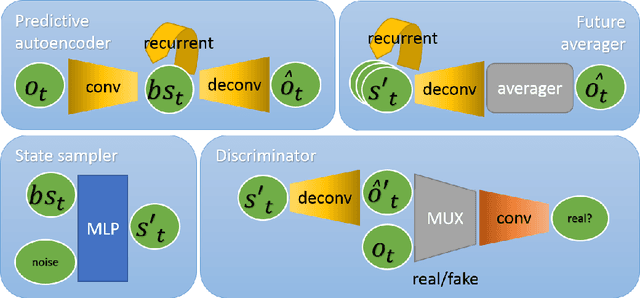

This work introduces a neural architecture for learning forward models of stochastic environments. The task is achieved solely through learning from temporal unstructured observations in the form of images. Once trained, the model allows for tracking of the environment state in the presence of noise or with new percepts arriving intermittently. Additionally, the state estimate can be propagated in observation-blind mode, thus allowing for long-term predictions. The network can output both expectation over future observations and samples from belief distribution. The resulting functionalities are similar to those of a Particle Filter (PF). The architecture is evaluated in an environment where we simulate objects moving. As the forward and sensor models are available, we implement a PF to gauge the quality of the models learnt from the data.
IV-Posterior: Inverse Value Estimation for Interpretable Policy Certificates
Nov 30, 2020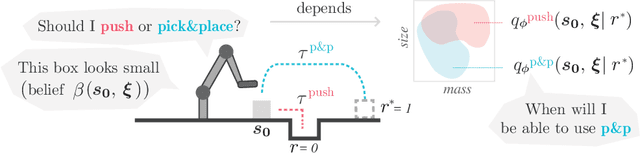
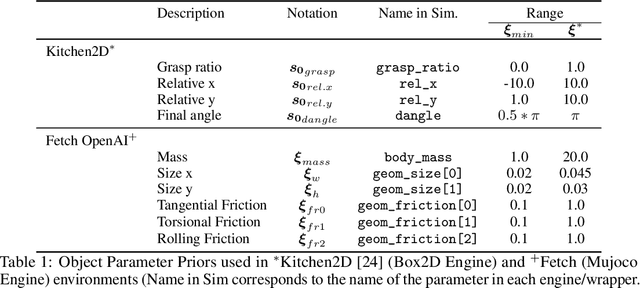
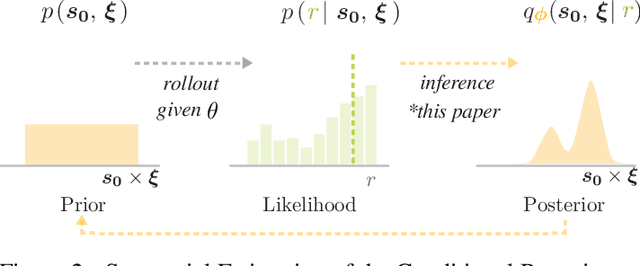
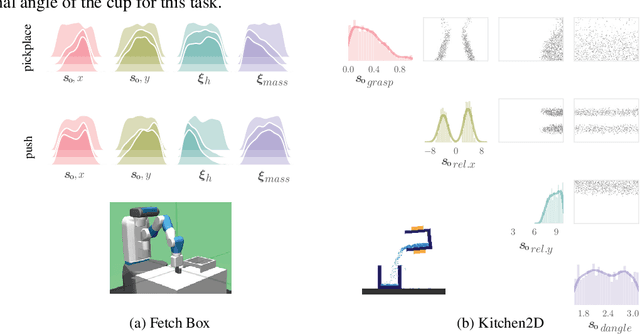
Model-free reinforcement learning (RL) is a powerful tool to learn a broad range of robot skills and policies. However, a lack of policy interpretability can inhibit their successful deployment in downstream applications, particularly when differences in environmental conditions may result in unpredictable behaviour or generalisation failures. As a result, there has been a growing emphasis in machine learning around the inclusion of stronger inductive biases in models to improve generalisation. This paper proposes an alternative strategy, inverse value estimation for interpretable policy certificates (IV-Posterior), which seeks to identify the inductive biases or idealised conditions of operation already held by pre-trained policies, and then use this information to guide their deployment. IV-Posterior uses MaskedAutoregressive Flows to fit distributions over the set of conditions or environmental parameters in which a policy is likely to be effective. This distribution can then be used as a policy certificate in downstream applications. We illustrate the use of IV-Posterior across a two environments, and show that substantial performance gains can be obtained when policy selection incorporates knowledge of the inductive biases that these policies hold.