 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Why Things Go Where They Go: Interpretable Constructs of Human Organizational Preferences
Dec 31, 2025Robotic systems for household object rearrangement often rely on latent preference models inferred from human demonstrations. While effective at prediction, these models offer limited insight into the interpretable factors that guide human decisions. We introduce an explicit formulation of object arrangement preferences along four interpretable constructs: spatial practicality (putting items where they naturally fit best in the space), habitual convenience (making frequently used items easy to reach), semantic coherence (placing items together if they are used for the same task or are contextually related), and commonsense appropriateness (putting things where people would usually expect to find them). To capture these constructs, we designed and validated a self-report questionnaire through a 63-participant online study. Results confirm the psychological distinctiveness of these constructs and their explanatory power across two scenarios (kitchen and living room). We demonstrate the utility of these constructs by integrating them into a Monte Carlo Tree Search (MCTS) planner and show that when guided by participant-derived preferences, our planner can generate reasonable arrangements that closely align with those generated by participants. This work contributes a compact, interpretable formulation of object arrangement preferences and a demonstration of how it can be operationalized for robot planning.
Learning a Neural Association Network for Self-supervised Multi-Object Tracking
Nov 18, 2024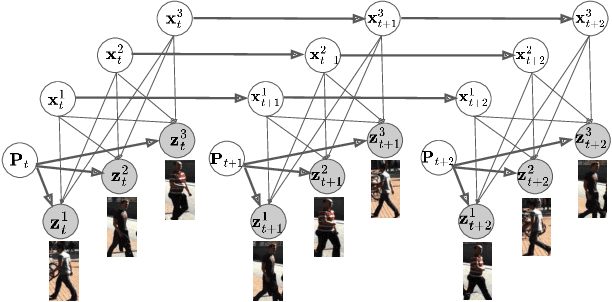
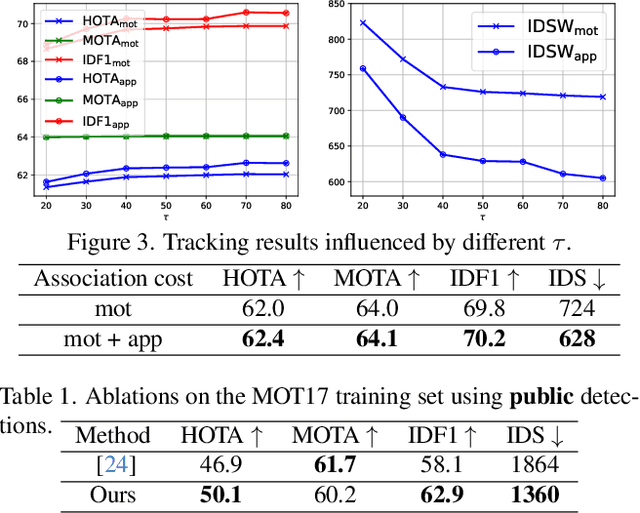
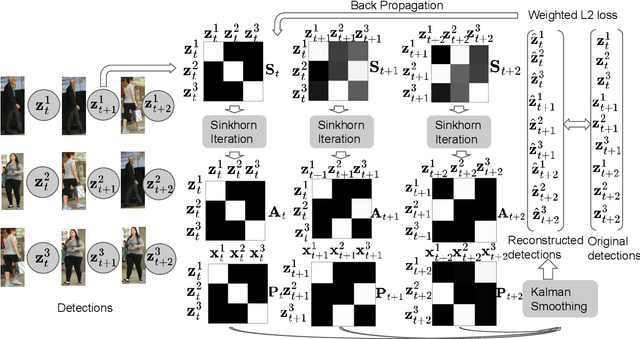
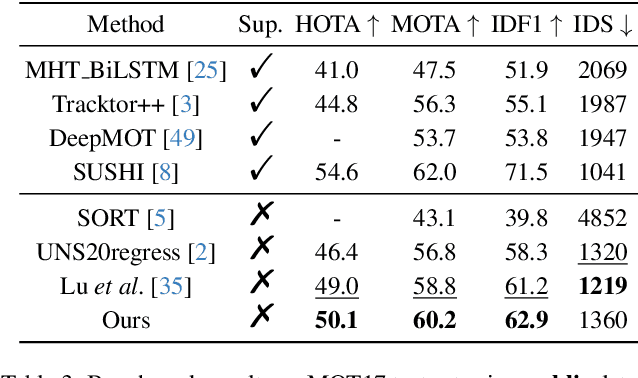
This paper introduces a novel framework to learn data association for multi-object tracking in a self-supervised manner. Fully-supervised learning methods are known to achieve excellent tracking performances, but acquiring identity-level annotations is tedious and time-consuming. Motivated by the fact that in real-world scenarios object motion can be usually represented by a Markov process, we present a novel expectation maximization (EM) algorithm that trains a neural network to associate detections for tracking, without requiring prior knowledge of their temporal correspondences. At the core of our method lies a neural Kalman filter, with an observation model conditioned on associations of detections parameterized by a neural network. Given a batch of frames as input, data associations between detections from adjacent frames are predicted by a neural network followed by a Sinkhorn normalization that determines the assignment probabilities of detections to states. Kalman smoothing is then used to obtain the marginal probability of observations given the inferred states, producing a training objective to maximize this marginal probability using gradient descent. The proposed framework is fully differentiable, allowing the underlying neural model to be trained end-to-end. We evaluate our approach on the challenging MOT17 and MOT20 datasets and achieve state-of-the-art results in comparison to self-supervised trackers using public detections. We furthermore demonstrate the capability of the learned model to generalize across datasets.
A Probabilistic Model for Skill Acquisition with Switching Latent Feedback Controllers
Oct 18, 2024Manipulation tasks often consist of subtasks, each representing a distinct skill. Mastering these skills is essential for robots, as it enhances their autonomy, efficiency, adaptability, and ability to work in their environment. Learning from demonstrations allows robots to rapidly acquire new skills without starting from scratch, with demonstrations typically sequencing skills to achieve tasks. Behaviour cloning approaches to learning from demonstration commonly rely on mixture density network output heads to predict robot actions. In this work, we first reinterpret the mixture density network as a library of feedback controllers (or skills) conditioned on latent states. This arises from the observation that a one-layer linear network is functionally equivalent to a classical feedback controller, with network weights corresponding to controller gains. We use this insight to derive a probabilistic graphical model that combines these elements, describing the skill acquisition process as segmentation in a latent space, where each skill policy functions as a feedback control law in this latent space. Our approach significantly improves not only task success rate, but also robustness to observation noise when trained with human demonstrations. Our physical robot experiments further show that the induced robustness improves model deployment on robots.
Efficiently Scanning and Resampling Spatio-Temporal Tasks with Irregular Observations
Oct 11, 2024Various works have aimed at combining the inference efficiency of recurrent models and training parallelism of multi-head attention for sequence modeling. However, most of these works focus on tasks with fixed-dimension observation spaces, such as individual tokens in language modeling or pixels in image completion. To handle an observation space of varying size, we propose a novel algorithm that alternates between cross-attention between a 2D latent state and observation, and a discounted cumulative sum over the sequence dimension to efficiently accumulate historical information. We find this resampling cycle is critical for performance. To evaluate efficient sequence modeling in this domain, we introduce two multi-agent intention tasks: simulated agents chasing bouncing particles and micromanagement analysis in professional StarCraft II games. Our algorithm achieves comparable accuracy with a lower parameter count, faster training and inference compared to existing methods.
Carefully Structured Compression: Efficiently Managing StarCraft II Data
Oct 11, 2024Creation and storage of datasets are often overlooked input costs in machine learning, as many datasets are simple image label pairs or plain text. However, datasets with more complex structures, such as those from the real time strategy game StarCraft II, require more deliberate thought and strategy to reduce cost of ownership. We introduce a serialization framework for StarCraft II that reduces the cost of dataset creation and storage, as well as improving usage ergonomics. We benchmark against the most comparable existing dataset from \textit{AlphaStar-Unplugged} and highlight the benefit of our framework in terms of both the cost of creation and storage. We use our dataset to train deep learning models that exceed the performance of comparable models trained on other datasets. The dataset conversion and usage framework introduced is open source and can be used as a framework for datasets with similar characteristics such as digital twin simulations. Pre-converted StarCraft II tournament data is also available online.
Rendering stable features improves sampling-based localisation with Neural radiance fields
Sep 21, 2023



Neural radiance fields (NeRFs) are a powerful tool for implicit scene representations, allowing for differentiable rendering and the ability to make predictions about previously unseen viewpoints. From a robotics perspective, there has been growing interest in object and scene-based localisation using NeRFs, with a number of recent works relying on sampling-based or Monte-Carlo localisation schemes. Unfortunately, these can be extremely computationally expensive, requiring multiple network forward passes to infer camera or object pose. To alleviate this, a variety of sampling strategies have been applied, many relying on keypoint recognition techniques from classical computer vision. This work conducts a systematic empirical comparison of these approaches and shows that in contrast to conventional feature matching approaches for geometry-based localisation, sampling-based localisation using NeRFs benefits significantly from stable features. Results show that rendering stable features can result in a tenfold reduction in the number of forward passes required, a significant speed improvement.
Generating robotic elliptical excisions with human-like tool-tissue interactions
Sep 21, 2023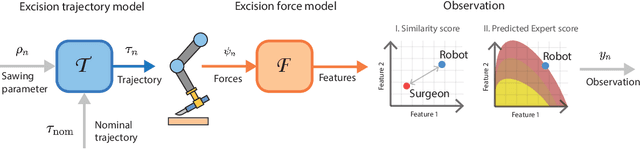
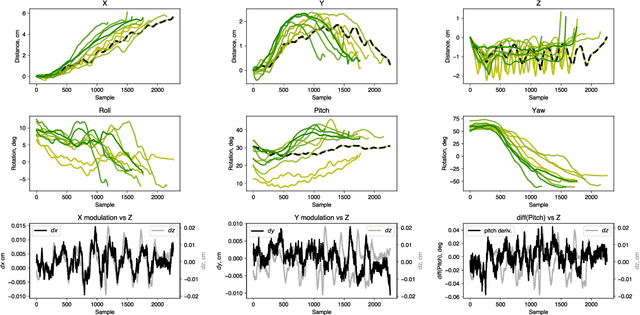
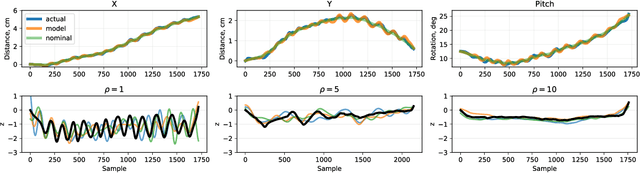

In surgery, the application of appropriate force levels is critical for the success and safety of a given procedure. While many studies are focused on measuring in situ forces, little attention has been devoted to relating these observed forces to surgical techniques. Answering questions like "Can certain changes to a surgical technique result in lower forces and increased safety margins?" could lead to improved surgical practice, and importantly, patient outcomes. However, such studies would require a large number of trials and professional surgeons, which is generally impractical to arrange. Instead, we show how robots can learn several variations of a surgical technique from a smaller number of surgical demonstrations and interpolate learnt behaviour via a parameterised skill model. This enables a large number of trials to be performed by a robotic system and the analysis of surgical techniques and their downstream effects on tissue. Here, we introduce a parameterised model of the elliptical excision skill and apply a Bayesian optimisation scheme to optimise the excision behaviour with respect to expert ratings, as well as individual characteristics of excision forces. Results show that the proposed framework can successfully align the generated robot behaviour with subjects across varying levels of proficiency in terms of excision forces.
Intelligent Robotic Sonographer: Mutual Information-based Disentangled Reward Learning from Few Demonstrations
Jul 07, 2023



Ultrasound (US) imaging is widely used for biometric measurement and diagnosis of internal organs due to the advantages of being real-time and radiation-free. However, due to high inter-operator variability, resulting images highly depend on operators' experience. In this work, an intelligent robotic sonographer is proposed to autonomously "explore" target anatomies and navigate a US probe to a relevant 2D plane by learning from expert. The underlying high-level physiological knowledge from experts is inferred by a neural reward function, using a ranked pairwise image comparisons approach in a self-supervised fashion. This process can be referred to as understanding the "language of sonography". Considering the generalization capability to overcome inter-patient variations, mutual information is estimated by a network to explicitly extract the task-related and domain features in latent space. Besides, a Gaussian distribution-based filter is developed to automatically evaluate and take the quality of the expert's demonstrations into account. The robotic localization is carried out in coarse-to-fine mode based on the predicted reward associated to B-mode images. To demonstrate the performance of the proposed approach, representative experiments for the "line" target and "point" target are performed on vascular phantom and two ex-vivo animal organ phantoms (chicken heart and lamb kidney), respectively. The results demonstrated that the proposed advanced framework can robustly work on different kinds of known and unseen phantoms.
Motion Perceiver: Real-Time Occupancy Forecasting for Embedded Systems
Jun 15, 2023This work introduces a flexible architecture for real-time occupancy forecasting. In contrast to existing, more computationally expensive architectures, the proposed model exploits recursive latent state estimation, using learned transformer-based prediction and update modules. This allows for highly efficient real-time inference on an embedded system (profiled on an Nvidia Xavier AGX), and the inclusion of a broad set of information from a diverse set of sensors. The architecture is able to process sparse and occluded observations of agent positions and scene context as this is made available, and does not require motion tracklet inputs. \networkName{} accomplishes this by encoding the scene into a latent state that evolves in time with self-attention and is updated with contextual information such as traffic signals, road topology or agent detections using cross-attention. Occupancy predictions are made by sparsely querying positions of interest as opposed to generating a fixed size raster image, which allows for variable resolution occupancy prediction or local querying by downstream trajectory optimisation algorithms, saving computational effort.
Social Cue Analysis using Transfer Entropy
Mar 06, 2023



Robots that work close to humans need to understand and use social cues to act in a socially acceptable manner. Social cues are a form of communication (i.e., information flow) between people. In this paper, a framework is introduced to detect and analyse social cues and information transfer directionality using an information-theoretic measure, namely, transfer entropy. We demonstrate the framework in three settings involving social interactions between humans: object-handover, group-joining and person-following. Results show that transfer entropy can identify information flows between agents, when and where they occur, and their relative strength. For instance, in a person-following scenario, we find that head orientation of a predictor is particularly informative, and the different times and locations that this is used to convey information to a leader influences their behaviour. Potential applications of the framework include information flow or social cue analysis for interactive robot design, or socially-aware robot planning.