 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoRing: Imitation Learning--based Autonomous Intraocular Foreign Body Removal Manipulation with Eye Surgical Robot
Aug 27, 2025Intraocular foreign body removal demands millimeter-level precision in confined intraocular spaces, yet existing robotic systems predominantly rely on manual teleoperation with steep learning curves. To address the challenges of autonomous manipulation (particularly kinematic uncertainties from variable motion scaling and variation of the Remote Center of Motion (RCM) point), we propose AutoRing, an imitation learning framework for autonomous intraocular foreign body ring manipulation. Our approach integrates dynamic RCM calibration to resolve coordinate-system inconsistencies caused by intraocular instrument variation and introduces the RCM-ACT architecture, which combines action-chunking transformers with real-time kinematic realignment. Trained solely on stereo visual data and instrument kinematics from expert demonstrations in a biomimetic eye model, AutoRing successfully completes ring grasping and positioning tasks without explicit depth sensing. Experimental validation demonstrates end-to-end autonomy under uncalibrated microscopy conditions. The results provide a viable framework for developing intelligent eye-surgical systems capable of complex intraocular procedures.
Robot-Assisted Deep Venous Thrombosis Ultrasound Examination using Virtual Fixture
Jan 04, 2024Deep Venous Thrombosis (DVT) is a common vascular disease with blood clots inside deep veins, which may block blood flow or even cause a life-threatening pulmonary embolism. A typical exam for DVT using ultrasound (US) imaging is by pressing the target vein until its lumen is fully compressed. However, the compression exam is highly operator-dependent. To alleviate intra- and inter-variations, we present a robotic US system with a novel hybrid force motion control scheme ensuring position and force tracking accuracy, and soft landing of the probe onto the target surface. In addition, a path-based virtual fixture is proposed to realize easy human-robot interaction for repeat compression operation at the lesion location. To ensure the biometric measurements obtained in different examinations are comparable, the 6D scanning path is determined in a coarse-to-fine manner using both an external RGBD camera and US images. The RGBD camera is first used to extract a rough scanning path on the object. Then, the segmented vascular lumen from US images are used to optimize the scanning path to ensure the visibility of the target object. To generate a continuous scan path for developing virtual fixtures, an arc-length based path fitting model considering both position and orientation is proposed. Finally, the whole system is evaluated on a human-like arm phantom with an uneven surface.
Intelligent Robotic Sonographer: Mutual Information-based Disentangled Reward Learning from Few Demonstrations
Jul 07, 2023



Ultrasound (US) imaging is widely used for biometric measurement and diagnosis of internal organs due to the advantages of being real-time and radiation-free. However, due to high inter-operator variability, resulting images highly depend on operators' experience. In this work, an intelligent robotic sonographer is proposed to autonomously "explore" target anatomies and navigate a US probe to a relevant 2D plane by learning from expert. The underlying high-level physiological knowledge from experts is inferred by a neural reward function, using a ranked pairwise image comparisons approach in a self-supervised fashion. This process can be referred to as understanding the "language of sonography". Considering the generalization capability to overcome inter-patient variations, mutual information is estimated by a network to explicitly extract the task-related and domain features in latent space. Besides, a Gaussian distribution-based filter is developed to automatically evaluate and take the quality of the expert's demonstrations into account. The robotic localization is carried out in coarse-to-fine mode based on the predicted reward associated to B-mode images. To demonstrate the performance of the proposed approach, representative experiments for the "line" target and "point" target are performed on vascular phantom and two ex-vivo animal organ phantoms (chicken heart and lamb kidney), respectively. The results demonstrated that the proposed advanced framework can robustly work on different kinds of known and unseen phantoms.
Precise Repositioning of Robotic Ultrasound: Improving Registration-based Motion Compensation using Ultrasound Confidence Optimization
Aug 10, 2022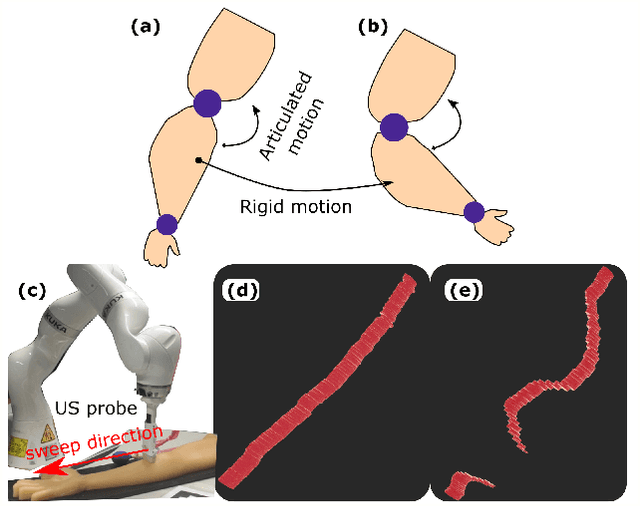
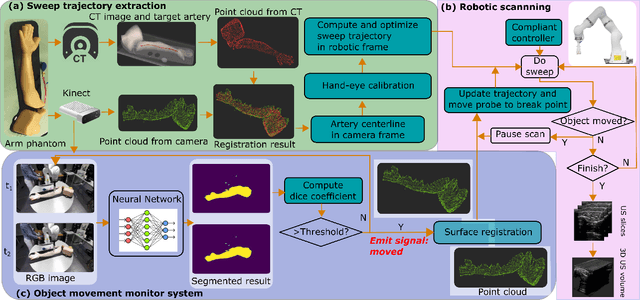
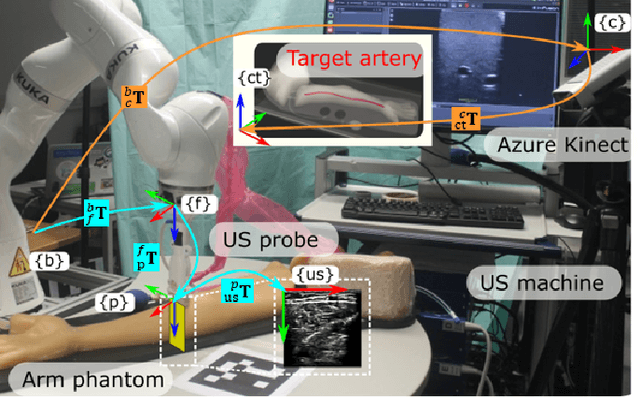

Robotic ultrasound (US) imaging has been seen as a promising solution to overcome the limitations of free-hand US examinations, i.e., inter-operator variability. \revision{However, the fact that robotic US systems cannot react to subject movements during scans limits their clinical acceptance.} Regarding human sonographers, they often react to patient movements by repositioning the probe or even restarting the acquisition, in particular for the scans of anatomies with long structures like limb arteries. To realize this characteristic, we proposed a vision-based system to monitor the subject's movement and automatically update the scan trajectory thus seamlessly obtaining a complete 3D image of the target anatomy. The motion monitoring module is developed using the segmented object masks from RGB images. Once the subject is moved, the robot will stop and recompute a suitable trajectory by registering the surface point clouds of the object obtained before and after the movement using the iterative closest point algorithm. Afterward, to ensure optimal contact conditions after repositioning US probe, a confidence-based fine-tuning process is used to avoid potential gaps between the probe and contact surface. Finally, the whole system is validated on a human-like arm phantom with an uneven surface, while the object segmentation network is also validated on volunteers. The results demonstrate that the presented system can react to object movements and reliably provide accurate 3D images.
Joint Prediction of Monocular Depth and Structure using Planar and Parallax Geometry
Jul 13, 2022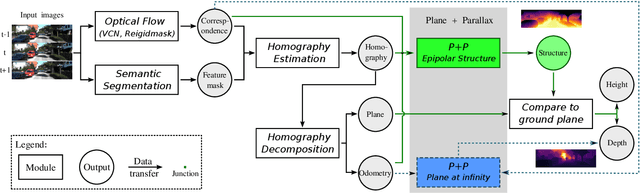
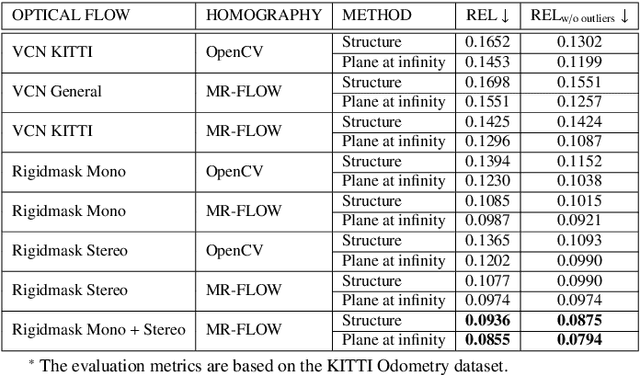
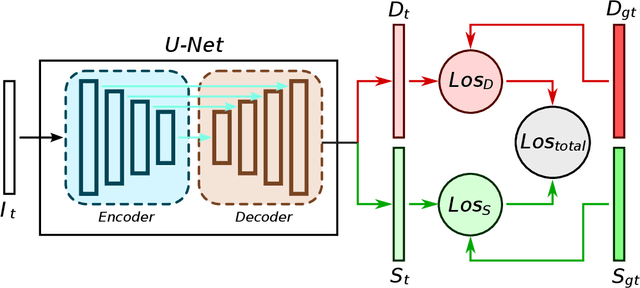
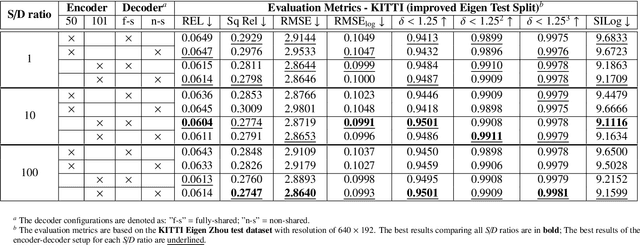
Supervised learning depth estimation methods can achieve good performance when trained on high-quality ground-truth, like LiDAR data. However, LiDAR can only generate sparse 3D maps which causes losing information. Obtaining high-quality ground-truth depth data per pixel is difficult to acquire. In order to overcome this limitation, we propose a novel approach combining structure information from a promising Plane and Parallax geometry pipeline with depth information into a U-Net supervised learning network, which results in quantitative and qualitative improvement compared to existing popular learning-based methods. In particular, the model is evaluated on two large-scale and challenging datasets: KITTI Vision Benchmark and Cityscapes dataset and achieve the best performance in terms of relative error. Compared with pure depth supervision models, our model has impressive performance on depth prediction of thin objects and edges, and compared to structure prediction baseline, our model performs more robustly.
PlantStereo: A Stereo Matching Benchmark for Plant Surface Dense Reconstruction
Nov 30, 2021


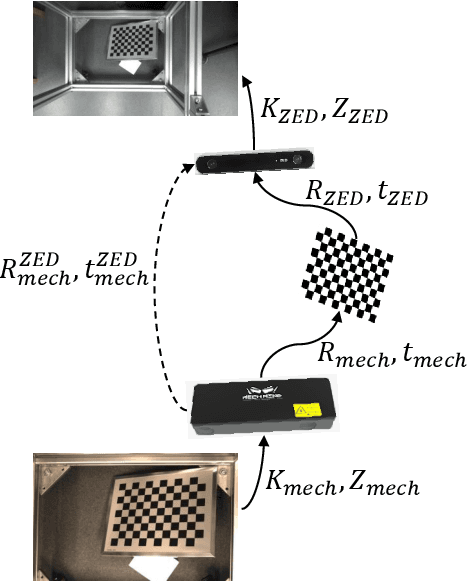
Stereo matching is an important task in computer vision which has drawn tremendous research attention for decades. While in terms of disparity accuracy, density and data size, public stereo datasets are difficult to meet the requirements of models. In this paper, we aim to address the issue between datasets and models and propose a large scale stereo dataset with high accuracy disparity ground truth named PlantStereo. We used a semi-automatic way to construct the dataset: after camera calibration and image registration, high accuracy disparity images can be obtained from the depth images. In total, PlantStereo contains 812 image pairs covering a diverse set of plants: spinach, tomato, pepper and pumpkin. We firstly evaluated our PlantStereo dataset on four different stereo matching methods. Extensive experiments on different models and plants show that compared with ground truth in integer accuracy, high accuracy disparity images provided by PlantStereo can remarkably improve the training effect of deep learning models. This paper provided a feasible and reliable method to realize plant surface dense reconstruction. The PlantStereo dataset and relative code are available at: https://www.github.com/wangqingyu985/PlantStereo
Robust Event Detection based on Spatio-Temporal Latent Action Unit using Skeletal Information
Oct 01, 2021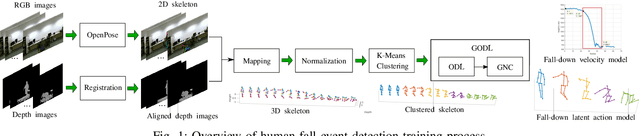
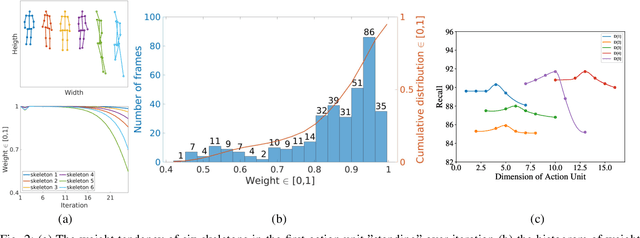
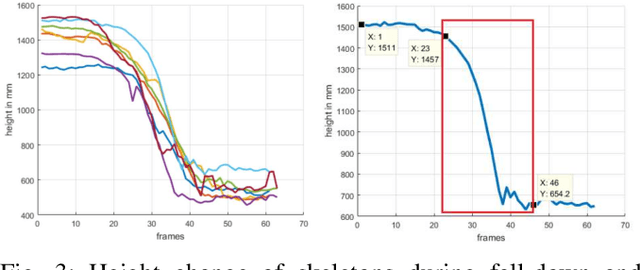
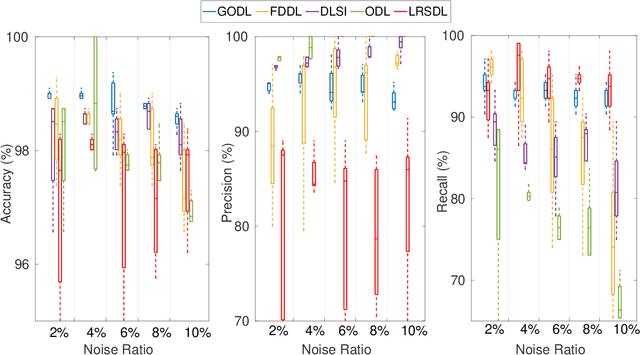
This paper propose a novel dictionary learning approach to detect event action using skeletal information extracted from RGBD video. The event action is represented as several latent atoms and composed of latent spatial and temporal attributes. We perform the method at the example of fall event detection. The skeleton frames are clustered by an initial K-means method. Each skeleton frame is assigned with a varying weight parameter and fed into our Gradual Online Dictionary Learning (GODL) algorithm. During the training process, outlier frames will be gradually filtered by reducing the weight that is inversely proportional to a cost. In order to strictly distinguish the event action from similar actions and robustly acquire its action unit, we build a latent unit temporal structure for each sub-action. We evaluate the proposed method on parts of the NTURGB+D dataset, which includes 209 fall videos, 405 ground-lift videos, 420 sit-down videos, and 280 videos of 46 otheractions. We present the experimental validation of the achieved accuracy, recall and precision. Our approach achieves the bestperformance on precision and accuracy of human fall event detection, compared with other existing dictionary learning methods. With increasing noise ratio, our method remains the highest accuracy and the lowest variance.
Deformation-Aware Robotic 3D Ultrasound
Jul 18, 2021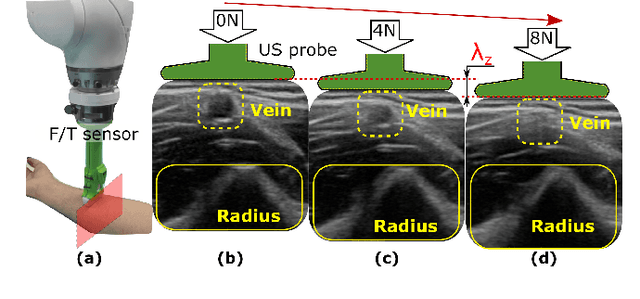
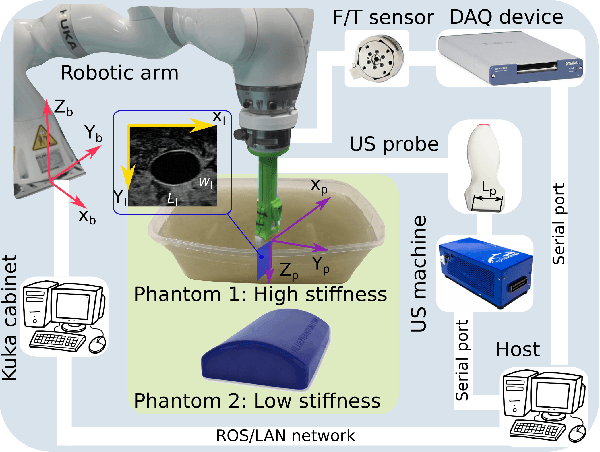
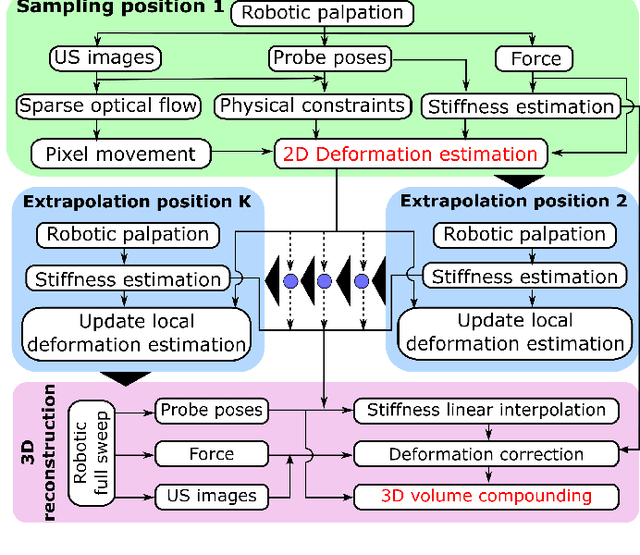
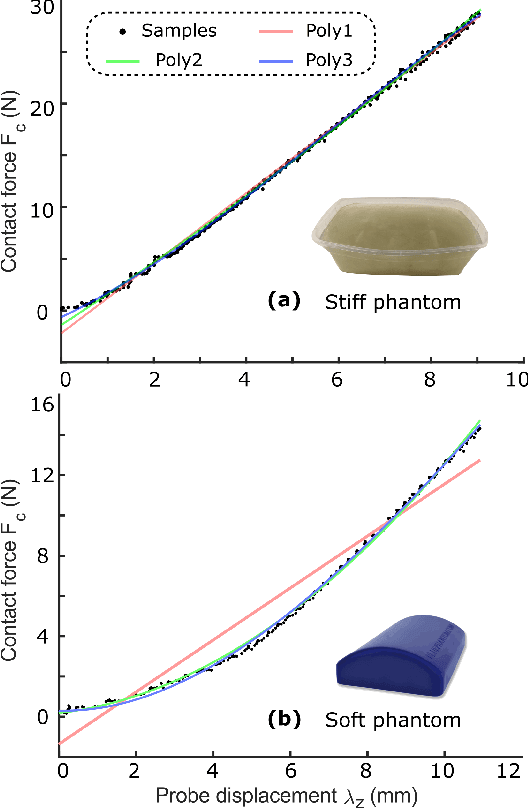
Tissue deformation in ultrasound (US) imaging leads to geometrical errors when measuring tissues due to the pressure exerted by probes. Such deformation has an even larger effect on 3D US volumes as the correct compounding is limited by the inconsistent location and geometry. This work proposes a patient-specified stiffness-based method to correct the tissue deformations in robotic 3D US acquisitions. To obtain the patient-specified model, robotic palpation is performed at sampling positions on the tissue. The contact force, US images and the probe poses of the palpation procedure are recorded. The contact force and the probe poses are used to estimate the nonlinear tissue stiffness. The images are fed to an optical flow algorithm to compute the pixel displacement. Then the pixel-wise tissue deformation under different forces is characterized by a coupled quadratic regression. To correct the deformation at unseen positions on the trajectory for building 3D volumes, an interpolation is performed based on the stiffness values computed at the sampling positions. With the stiffness and recorded force, the tissue displacement could be corrected. The method was validated on two blood vessel phantoms with different stiffness. The results demonstrate that the method can effectively correct the force-induced deformation and finally generate 3D tissue geometries
Motion-Aware Robotic 3D Ultrasound
Jul 13, 2021
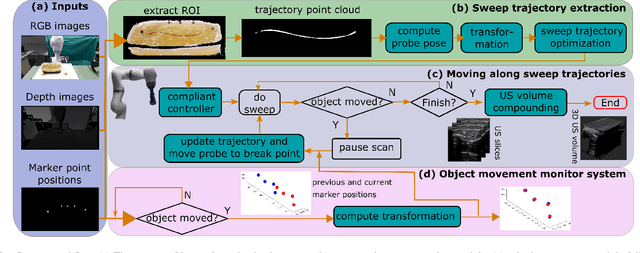
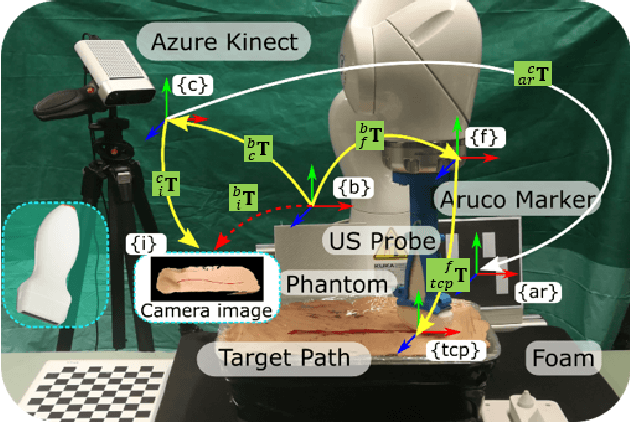
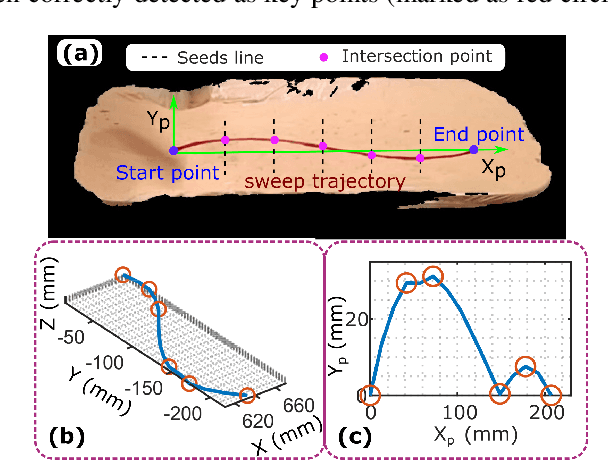
Robotic three-dimensional (3D) ultrasound (US) imaging has been employed to overcome the drawbacks of traditional US examinations, such as high inter-operator variability and lack of repeatability. However, object movement remains a challenge as unexpected motion decreases the quality of the 3D compounding. Furthermore, attempted adjustment of objects, e.g., adjusting limbs to display the entire limb artery tree, is not allowed for conventional robotic US systems. To address this challenge, we propose a vision-based robotic US system that can monitor the object's motion and automatically update the sweep trajectory to provide 3D compounded images of the target anatomy seamlessly. To achieve these functions, a depth camera is employed to extract the manually planned sweep trajectory after which the normal direction of the object is estimated using the extracted 3D trajectory. Subsequently, to monitor the movement and further compensate for this motion to accurately follow the trajectory, the position of firmly attached passive markers is tracked in real-time. Finally, a step-wise compounding was performed. The experiments on a gel phantom demonstrate that the system can resume a sweep when the object is not stationary during scanning.
Spotlight-based 3D Instrument Guidance for Retinal Surgery
Dec 11, 2020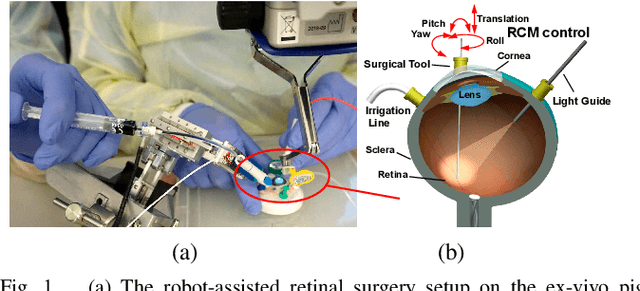
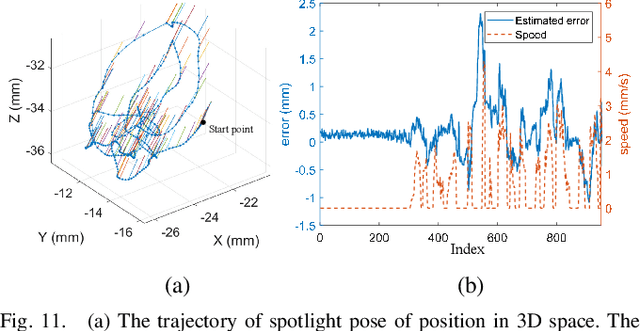
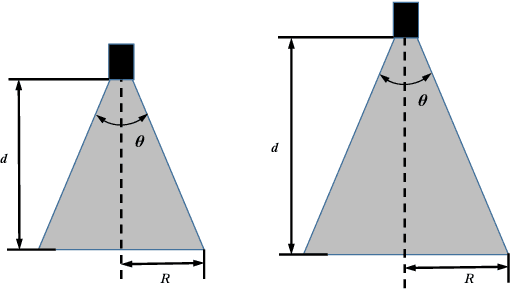
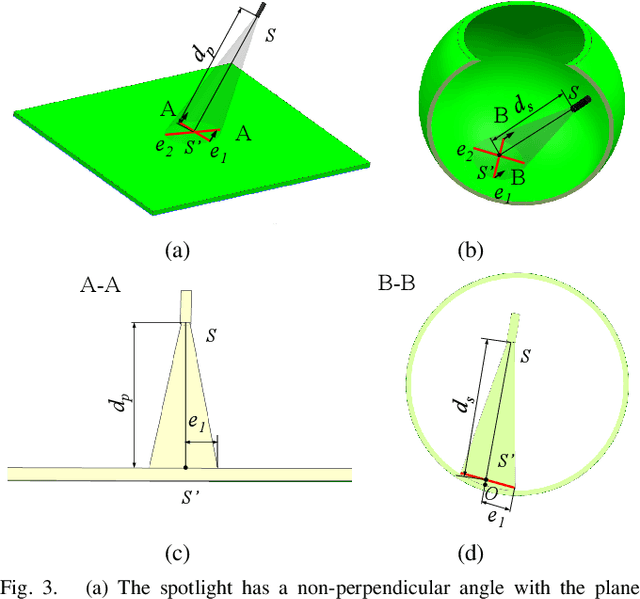
Retinal surgery is a complex activity that can be challenging for a surgeon to perform effectively and safely. Image guided robot-assisted surgery is one of the promising solutions that bring significant surgical enhancement in treatment outcome and reduce the physical limitations of human surgeons. In this paper, we demonstrate a novel method for 3D guidance of the instrument based on the projection of spotlight in the single microscope images. The spotlight projection mechanism is firstly analyzed and modeled with a projection on both a plane and a sphere surface. To test the feasibility of the proposed method, a light fiber is integrated into the instrument which is driven by the Steady-Hand Eye Robot (SHER). The spot of light is segmented and tracked on a phantom retina using the proposed algorithm. The static calibration and dynamic test results both show that the proposed method can easily archive 0.5 mm of tip-to-surface distance which is within the clinically acceptable accuracy for intraocular visual guidance.