 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
Visual-Haptic Model Mediated Teleoperation for Remote Ultrasound
Feb 11, 2025Tele-ultrasound has the potential greatly to improve health equity for countless remote communities. However, practical scenarios involve potentially large time delays which cause current implementations of telerobotic ultrasound (US) to fail. Using a local model of the remote environment to provide haptics to the expert operator can decrease teleoperation instability, but the delayed visual feedback remains problematic. This paper introduces a robotic tele-US system in which the local model is not only haptic, but also visual, by re-slicing and rendering a pre-acquired US sweep in real time to provide the operator a preview of what the delayed image will resemble. A prototype system is presented and tested with 15 volunteer operators. It is found that visual-haptic model-mediated teleoperation (MMT) compensates completely for time delays up to 1000 ms round trip in terms of operator effort and completion time while conventional MMT does not. Visual-haptic MMT also significantly outperforms MMT for longer time delays in terms of motion accuracy and force control. This proof-of-concept study suggests that visual-haptic MMT may facilitate remote robotic tele-US.
DISA: DIfferentiable Similarity Approximation for Universal Multimodal Registration
Jul 19, 2023



Multimodal image registration is a challenging but essential step for numerous image-guided procedures. Most registration algorithms rely on the computation of complex, frequently non-differentiable similarity metrics to deal with the appearance discrepancy of anatomical structures between imaging modalities. Recent Machine Learning based approaches are limited to specific anatomy-modality combinations and do not generalize to new settings. We propose a generic framework for creating expressive cross-modal descriptors that enable fast deformable global registration. We achieve this by approximating existing metrics with a dot-product in the feature space of a small convolutional neural network (CNN) which is inherently differentiable can be trained without registered data. Our method is several orders of magnitude faster than local patch-based metrics and can be directly applied in clinical settings by replacing the similarity measure with the proposed one. Experiments on three different datasets demonstrate that our approach generalizes well beyond the training data, yielding a broad capture range even on unseen anatomies and modality pairs, without the need for specialized retraining. We make our training code and data publicly available.
PRO-TIP: Phantom for RObust automatic ultrasound calibration by TIP detection
Jun 13, 2022
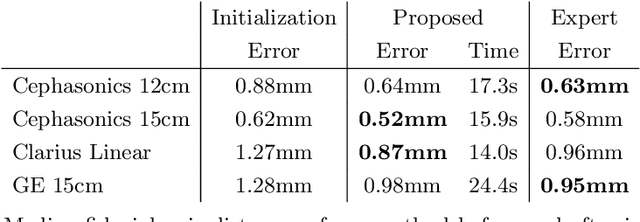
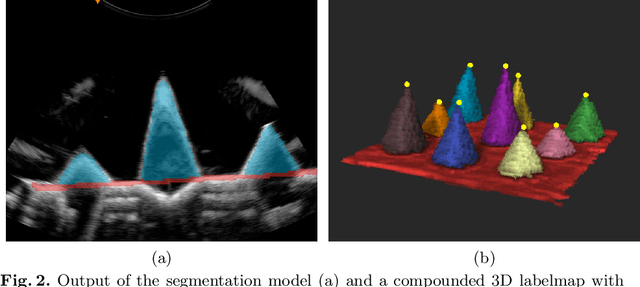

We propose a novel method to automatically calibrate tracked ultrasound probes. To this end we design a custom phantom consisting of nine cones with different heights. The tips are used as key points to be matched between multiple sweeps. We extract them using a convolutional neural network to segment the cones in every ultrasound frame and then track them across the sweep. The calibration is robustly estimated using RANSAC and later refined employing image based techniques. Our phantom can be 3D-printed and offers many advantages over state-of-the-art methods. The phantom design and algorithm code are freely available online. Since our phantom does not require a tracking target on itself, ease of use is improved over currently used techniques. The fully automatic method generalizes to new probes and different vendors, as shown in our experiments. Our approach produces results comparable to calibrations obtained by a domain expert.
Global Multi-modal 2D/3D Registration via Local Descriptors Learning
May 06, 2022
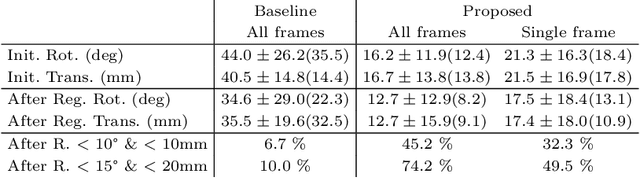
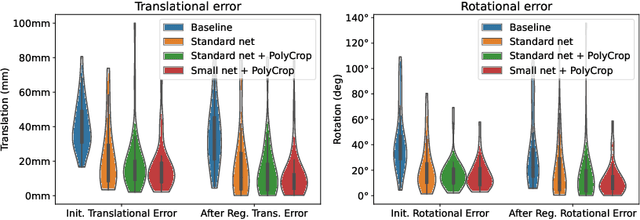
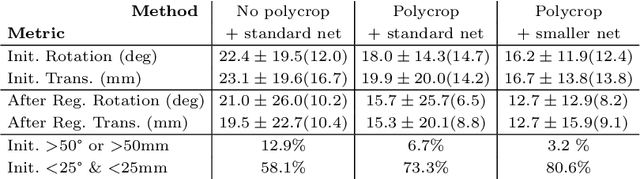
Multi-modal registration is a required step for many image-guided procedures, especially ultrasound-guided interventions that require anatomical context. While a number of such registration algorithms are already available, they all require a good initialization to succeed due to the challenging appearance of ultrasound images and the arbitrary coordinate system they are acquired in. In this paper, we present a novel approach to solve the problem of registration of an ultrasound sweep to a pre-operative image. We learn dense keypoint descriptors from which we then estimate the registration. We show that our method overcomes the challenges inherent to registration tasks with freehand ultrasound sweeps, namely, the multi-modality and multidimensionality of the data in addition to lack of precise ground truth and low amounts of training examples. We derive a registration method that is fast, generic, fully automatic, does not require any initialization and can naturally generate visualizations aiding interpretability and explainability. Our approach is evaluated on a clinical dataset of paired MR volumes and ultrasound sequences.
Adversarial Domain Feature Adaptation for Bronchoscopic Depth Estimation
Sep 24, 2021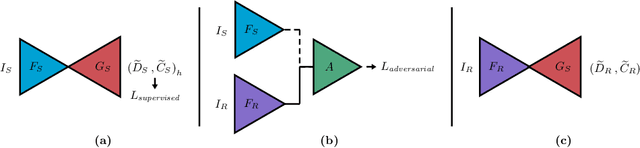
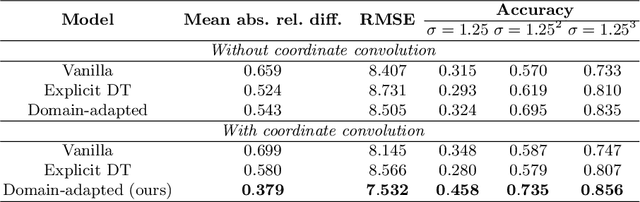
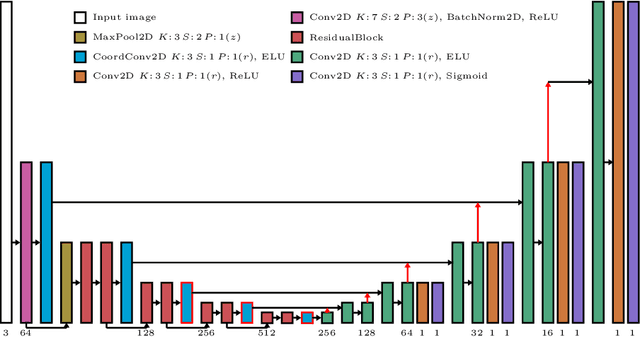
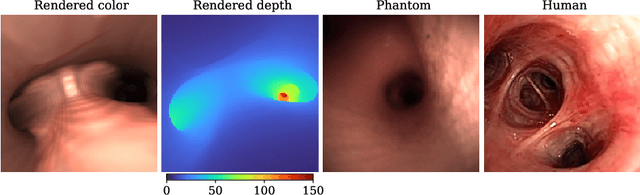
Depth estimation from monocular images is an important task in localization and 3D reconstruction pipelines for bronchoscopic navigation. Various supervised and self-supervised deep learning-based approaches have proven themselves on this task for natural images. However, the lack of labeled data and the bronchial tissue's feature-scarce texture make the utilization of these methods ineffective on bronchoscopic scenes. In this work, we propose an alternative domain-adaptive approach. Our novel two-step structure first trains a depth estimation network with labeled synthetic images in a supervised manner; then adopts an unsupervised adversarial domain feature adaptation scheme to improve the performance on real images. The results of our experiments show that the proposed method improves the network's performance on real images by a considerable margin and can be employed in 3D reconstruction pipelines.
Autonomous Robotic Screening of Tubular Structures based only on Real-Time Ultrasound Imaging Feedback
Oct 30, 2020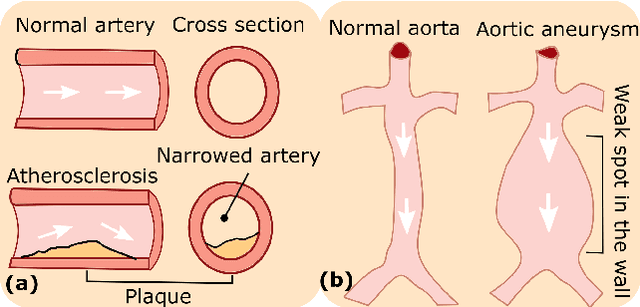

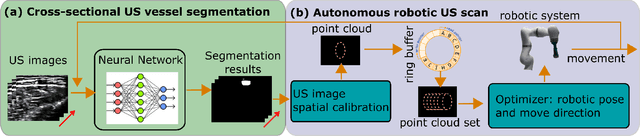
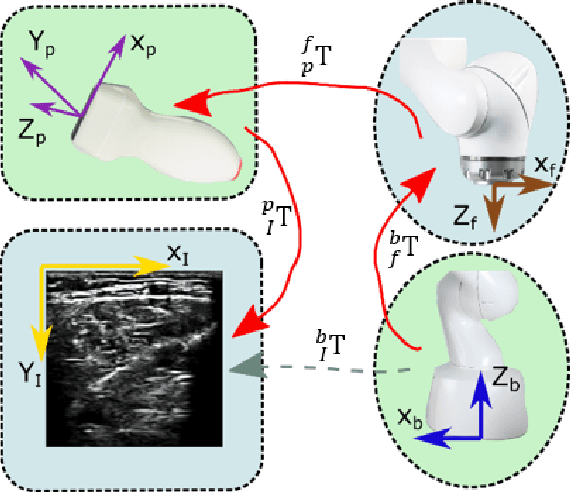
Ultrasound (US) imaging is widely employed for diagnosis and staging of peripheral vascular diseases (PVD), mainly due to its high availability and the fact it does not emit radiation. However, high inter-operator variability and a lack of repeatability of US image acquisition hinder the implementation of extensive screening programs. To address this challenge, we propose an end-to-end workflow for automatic robotic US screening of tubular structures using only the real-time US imaging feedback. We first train a U-Net for real-time segmentation of the vascular structure from cross-sectional US images. Then, we represent the detected vascular structure as a 3D point cloud and use it to estimate the longitudinal axis of the target tubular structure and its mean radius by solving a constrained non-linear optimization problem. Iterating the previous processes, the US probe is automatically aligned to the orientation normal to the target tubular tissue and adjusted online to center the tracked tissue based on the spatial calibration. The real-time segmentation result is evaluated both on a phantom and in-vivo on brachial arteries of volunteers. In addition, the whole process is validated both in simulation and physical phantoms. The mean absolute radius error and orientation error ($\pm$ SD) in the simulation are $1.16\pm0.1~mm$ and $2.7\pm3.3^{\circ}$, respectively. On a gel phantom, these errors are $1.95\pm2.02~mm$ and $3.3\pm2.4^{\circ}$. This shows that the method is able to automatically screen tubular tissues with an optimal probe orientation (i.e. normal to the vessel) and at the same to accurately estimate the mean radius, both in real-time.