 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic versus Human Teleoperation for Remote Ultrasound
Nov 10, 2025Diagnostic medical ultrasound is widely used, safe, and relatively low cost but requires a high degree of expertise to acquire and interpret the images. Personnel with this expertise are often not available outside of larger cities, leading to difficult, costly travel and long wait times for rural populations. To address this issue, tele-ultrasound techniques are being developed, including robotic teleoperation and recently human teleoperation, in which a novice user is remotely guided in a hand-over-hand manner through mixed reality to perform an ultrasound exam. These methods have not been compared, and their relative strengths are unknown. Human teleoperation may be more practical than robotics for small communities due to its lower cost and complexity, but this is only relevant if the performance is comparable. This paper therefore evaluates the differences between human and robotic teleoperation, examining practical aspects such as setup time and flexibility and experimentally comparing performance metrics such as completion time, position tracking, and force consistency. It is found that human teleoperation does not lead to statistically significant differences in completion time or position accuracy, with mean differences of 1.8% and 0.5%, respectively, and provides more consistent force application despite being substantially more practical and accessible.
Linearity, Time Invariance, and Passivity of a Novice Person in Human Teleoperation
Apr 15, 2025Low-cost teleguidance of medical procedures is becoming essential to provide healthcare to remote and underserved communities. Human teleoperation is a promising new method for guiding a novice person with relatively high precision and efficiency through a mixed reality (MR) interface. Prior work has shown that the novice, or "follower", can reliably track the MR input with performance not unlike a telerobotic system. As a consequence, it is of interest to understand and control the follower's dynamics to optimize the system performance and permit stable and transparent bilateral teleoperation. To this end, linearity, time-invariance, inter-axis coupling, and passivity are important in teleoperation and controller design. This paper therefore explores these effects with regard to the follower person in human teleoperation. It is demonstrated through modeling and experiments that the follower can indeed be treated as approximately linear and time invariant, with little coupling and a large excess of passivity at practical frequencies. Furthermore, a stochastic model of the follower dynamics is derived. These results will permit controller design and analysis to improve the performance of human teleoperation.
Visual-Haptic Model Mediated Teleoperation for Remote Ultrasound
Feb 11, 2025Tele-ultrasound has the potential greatly to improve health equity for countless remote communities. However, practical scenarios involve potentially large time delays which cause current implementations of telerobotic ultrasound (US) to fail. Using a local model of the remote environment to provide haptics to the expert operator can decrease teleoperation instability, but the delayed visual feedback remains problematic. This paper introduces a robotic tele-US system in which the local model is not only haptic, but also visual, by re-slicing and rendering a pre-acquired US sweep in real time to provide the operator a preview of what the delayed image will resemble. A prototype system is presented and tested with 15 volunteer operators. It is found that visual-haptic model-mediated teleoperation (MMT) compensates completely for time delays up to 1000 ms round trip in terms of operator effort and completion time while conventional MMT does not. Visual-haptic MMT also significantly outperforms MMT for longer time delays in terms of motion accuracy and force control. This proof-of-concept study suggests that visual-haptic MMT may facilitate remote robotic tele-US.
Stability and Transparency in Mixed Reality Bilateral Human Teleoperation
Oct 13, 2024Recent work introduced the concept of human teleoperation (HT), where the remote robot typically considered in conventional bilateral teleoperation is replaced by a novice person wearing a mixed reality head mounted display and tracking the motion of a virtual tool controlled by an expert. HT has advantages in cost, complexity, and patient acceptance for telemedicine in low-resource communities or remote locations. However, the stability, transparency, and performance of bilateral HT are unexplored. In this paper, we therefore develop a mathematical model and simulation of the HT system using test data. We then analyze various control architectures with this model and implement them with the HT system to find the achievable performance, investigate stability, and determine the most promising teleoperation scheme in the presence of time delays. We show that instability in HT, while not destructive or dangerous, makes the system impossible to use. However, stable and transparent teleoperation are possible with small time delays (<200 ms) through 3-channel teleoperation, or with large time delays through model-mediated teleoperation with local pose and force feedback for the novice.
Towards Machine Learning-based Quantitative Hyperspectral Image Guidance for Brain Tumor Resection
Nov 24, 2023Complete resection of malignant gliomas is hampered by the difficulty in distinguishing tumor cells at the infiltration zone. Fluorescence guidance with 5-ALA assists in reaching this goal. Using hyperspectral imaging, previous work characterized five fluorophores' emission spectra in most human brain tumors. In this paper, the effectiveness of these five spectra was explored for different tumor and tissue classification tasks in 184 patients (891 hyperspectral measurements) harboring low- (n=30) and high-grade gliomas (n=115), non-glial primary brain tumors (n=19), radiation necrosis (n=2), miscellaneous (n=10) and metastases (n=8). Four machine learning models were trained to classify tumor type, grade, glioma margins and IDH mutation. Using random forests and multi-layer perceptrons, the classifiers achieved average test accuracies of 84-87%, 96%, 86%, and 93% respectively. All five fluorophore abundances varied between tumor margin types and tumor grades (p < 0.01). For tissue type, at least four of the five fluorophore abundances were found to be significantly different (p < 0.01) between all classes. These results demonstrate the fluorophores' differing abundances in different tissue classes, as well as the value of the five fluorophores as potential optical biomarkers, opening new opportunities for intraoperative classification systems in fluorescence-guided neurosurgery.
Multi-Scale Relational Graph Convolutional Network for Multiple Instance Learning in Histopathology Images
Dec 17, 2022



Graph convolutional neural networks have shown significant potential in natural and histopathology images. However, their use has only been studied in a single magnification or multi-magnification with late fusion. In order to leverage the multi-magnification information and early fusion with graph convolutional networks, we handle different embedding spaces at each magnification by introducing the Multi-Scale Relational Graph Convolutional Network (MS-RGCN) as a multiple instance learning method. We model histopathology image patches and their relation with neighboring patches and patches at other scales (i.e., magnifications) as a graph. To pass the information between different magnification embedding spaces, we define separate message-passing neural networks based on the node and edge type. We experiment on prostate cancer histopathology images to predict the grade groups based on the extracted features from patches. We also compare our MS-RGCN with multiple state-of-the-art methods with evaluations on both source and held-out datasets. Our method outperforms the state-of-the-art on both datasets and especially on the classification of grade groups 2 and 3, which are significant for clinical decisions for patient management. Through an ablation study, we test and show the value of the pertinent design features of the MS-RGCN.
ResNet Structure Simplification with the Convolutional Kernel Redundancy Measure
Dec 01, 2022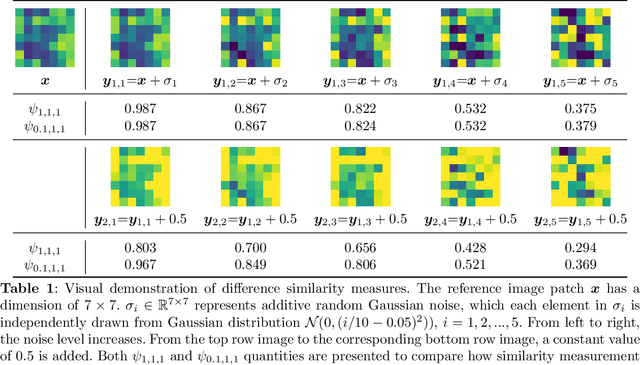
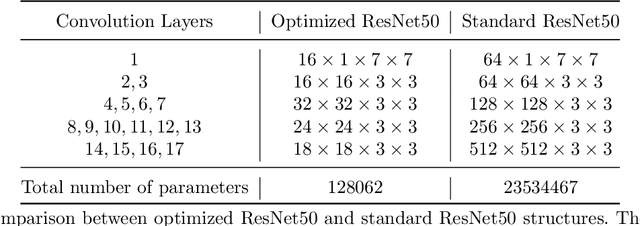
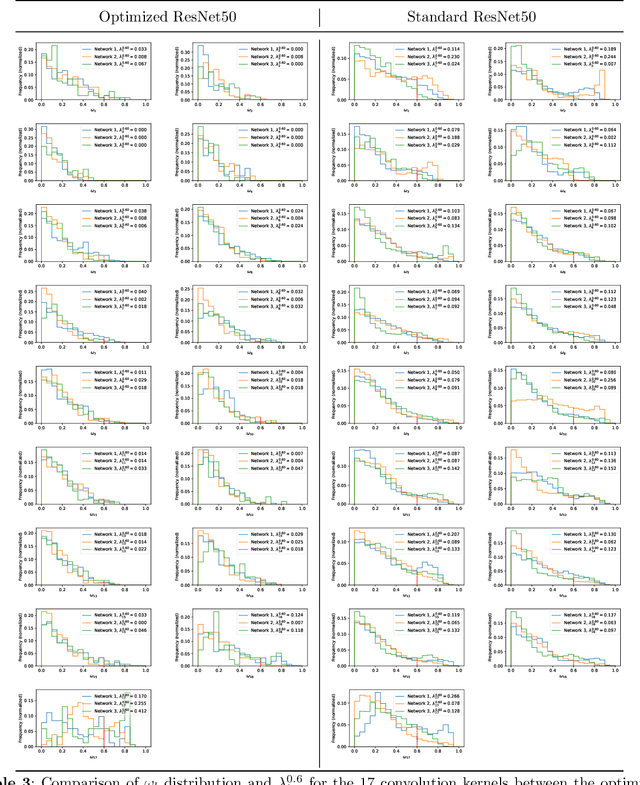
Deep learning, especially convolutional neural networks, has triggered accelerated advancements in computer vision, bringing changes into our daily practice. Furthermore, the standardized deep learning modules (also known as backbone networks), i.e., ResNet and EfficientNet, have enabled efficient and rapid development of new computer vision solutions. Yet, deep learning methods still suffer from several drawbacks. One of the most concerning problems is the high memory and computational cost, such that dedicated computing units, typically GPUs, have to be used for training and development. Therefore, in this paper, we propose a quantifiable evaluation method, the convolutional kernel redundancy measure, which is based on perceived image differences, for guiding the network structure simplification. When applying our method to the chest X-ray image classification problem with ResNet, our method can maintain the performance of the network and reduce the number of parameters from over $23$ million to approximately $128$ thousand (reducing $99.46\%$ of the parameters).
Generalizable Neural Radiance Fields for Novel View Synthesis with Transformer
Jun 10, 2022

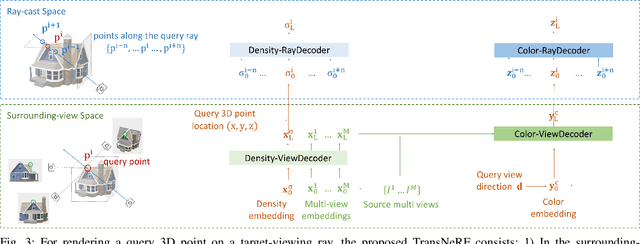

We propose a Transformer-based NeRF (TransNeRF) to learn a generic neural radiance field conditioned on observed-view images for the novel view synthesis task. By contrast, existing MLP-based NeRFs are not able to directly receive observed views with an arbitrary number and require an auxiliary pooling-based operation to fuse source-view information, resulting in the missing of complicated relationships between source views and the target rendering view. Furthermore, current approaches process each 3D point individually and ignore the local consistency of a radiance field scene representation. These limitations potentially can reduce their performance in challenging real-world applications where large differences between source views and a novel rendering view may exist. To address these challenges, our TransNeRF utilizes the attention mechanism to naturally decode deep associations of an arbitrary number of source views into a coordinate-based scene representation. Local consistency of shape and appearance are considered in the ray-cast space and the surrounding-view space within a unified Transformer network. Experiments demonstrate that our TransNeRF, trained on a wide variety of scenes, can achieve better performance in comparison to state-of-the-art image-based neural rendering methods in both scene-agnostic and per-scene finetuning scenarios especially when there is a considerable gap between source views and a rendering view.
Multi-task UNet: Jointly Boosting Saliency Prediction and Disease Classification on Chest X-ray Images
Feb 15, 2022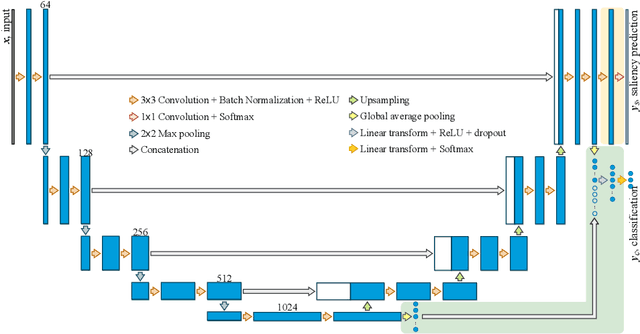
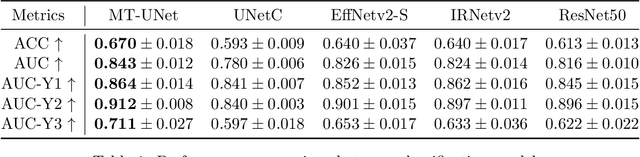


Human visual attention has recently shown its distinct capability in boosting machine learning models. However, studies that aim to facilitate medical tasks with human visual attention are still scarce. To support the use of visual attention, this paper describes a novel deep learning model for visual saliency prediction on chest X-ray (CXR) images. To cope with data deficiency, we exploit the multi-task learning method and tackles disease classification on CXR simultaneously. For a more robust training process, we propose a further optimized multi-task learning scheme to better handle model overfitting. Experiments show our proposed deep learning model with our new learning scheme can outperform existing methods dedicated either for saliency prediction or image classification. The code used in this paper is available at https://github.com/hz-zhu/MT-UNet.
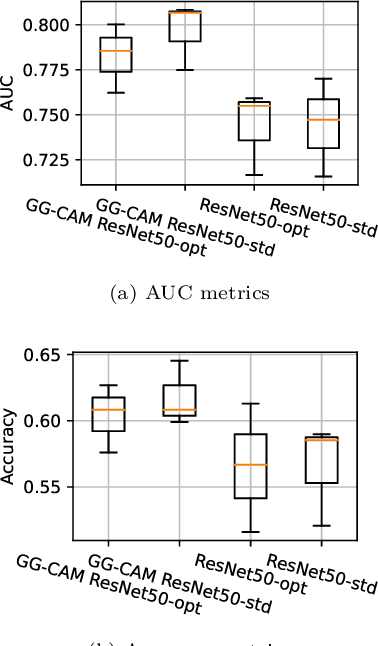
Gaze-Guided Class Activation Mapping: Leveraging Human Attention for Network Attention in Chest X-rays Classification
Feb 15, 2022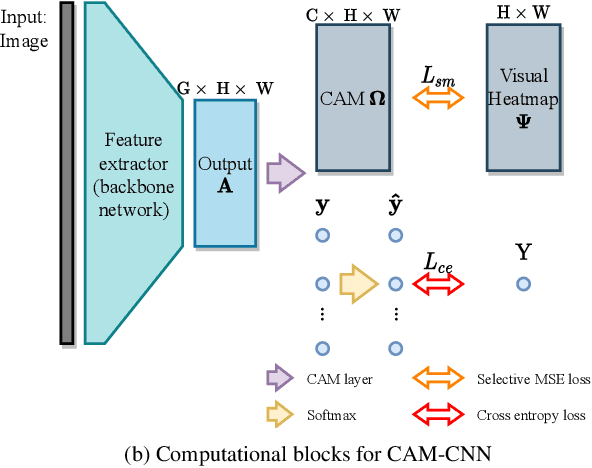
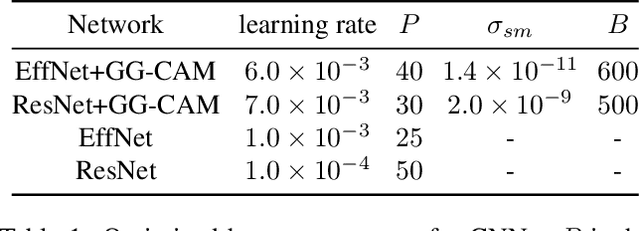
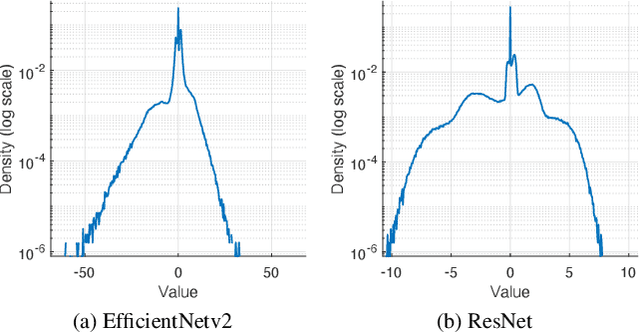
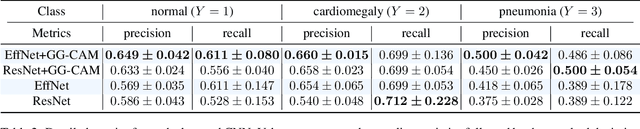
The increased availability and accuracy of eye-gaze tracking technology has sparked attention-related research in psychology, neuroscience, and, more recently, computer vision and artificial intelligence. The attention mechanism in artificial neural networks is known to improve learning tasks. However, no previous research has combined the network attention and human attention. This paper describes a gaze-guided class activation mapping (GG-CAM) method to directly regulate the formation of network attention based on expert radiologists' visual attention for the chest X-ray pathology classification problem, which remains challenging due to the complex and often nuanced differences among images. GG-CAM is a lightweight ($3$ additional trainable parameters for regulating the learning process) and generic extension that can be easily applied to most classification convolutional neural networks (CNN). GG-CAM-modified CNNs do not require human attention as an input when fully trained. Comparative experiments suggest that two standard CNNs with the GG-CAM extension achieve significantly greater classification performance. The median area under the curve (AUC) metrics for ResNet50 increases from $0.721$ to $0.776$. For EfficientNetv2 (s), the median AUC increases from $0.723$ to $0.801$. The GG-CAM also brings better interpretability of the network that facilitates the weakly-supervised pathology localization and analysis.