 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Perception-Distortion Trade-off with Spatial-Semantic Guided Super-Resolution
Mar 14, 2026Image super-resolution (SR) aims to reconstruct high resolution images with both high perceptual quality and low distortion, but is fundamentally limited by the perception-distortion trade-off. GAN-based SR methods reduce distortion but still struggle with realistic fine-grained textures, whereas diffusion-based approaches synthesize rich details but often deviate from the input, hallucinating structures and degrading fidelity. This tension raises a key challenge: how to exploit the powerful generative priors of diffusion models without sacrificing fidelity. To address this, we propose SpaSemSR, a spatial-semantic guided diffusion framework with two complementary guidances. First, spatial-grounded textual guidance integrates object-level spatial cues with semantic prompts, aligning textual and visual structures to reduce distortion. Second, semantic-enhanced visual guidance with a multi-encoder design and semantic degradation constraints unifies multimodal semantic priors, improving perceptual realism under severe degradations. These complementary guidances are adaptively fused into the diffusion process via spatial-semantic attention, suppressing distortion and hallucination while retaining the strengths of diffusion models. Extensive experiments on multiple benchmarks show that SpaSemSR achieves a superior perception-distortion balance, producing both realistic and faithful restorations.
Generalizable Neural Radiance Fields for Novel View Synthesis with Transformer
Jun 10, 2022

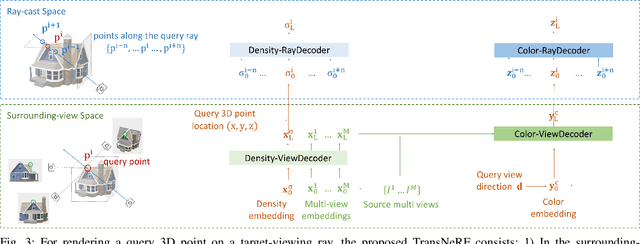

We propose a Transformer-based NeRF (TransNeRF) to learn a generic neural radiance field conditioned on observed-view images for the novel view synthesis task. By contrast, existing MLP-based NeRFs are not able to directly receive observed views with an arbitrary number and require an auxiliary pooling-based operation to fuse source-view information, resulting in the missing of complicated relationships between source views and the target rendering view. Furthermore, current approaches process each 3D point individually and ignore the local consistency of a radiance field scene representation. These limitations potentially can reduce their performance in challenging real-world applications where large differences between source views and a novel rendering view may exist. To address these challenges, our TransNeRF utilizes the attention mechanism to naturally decode deep associations of an arbitrary number of source views into a coordinate-based scene representation. Local consistency of shape and appearance are considered in the ray-cast space and the surrounding-view space within a unified Transformer network. Experiments demonstrate that our TransNeRF, trained on a wide variety of scenes, can achieve better performance in comparison to state-of-the-art image-based neural rendering methods in both scene-agnostic and per-scene finetuning scenarios especially when there is a considerable gap between source views and a rendering view.
Multi-view 3D Reconstruction with Transformer
Mar 24, 2021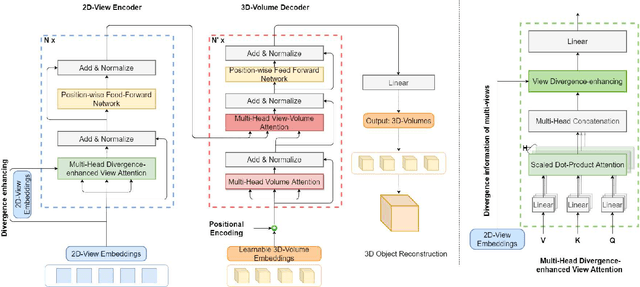



Deep CNN-based methods have so far achieved the state of the art results in multi-view 3D object reconstruction. Despite the considerable progress, the two core modules of these methods - multi-view feature extraction and fusion, are usually investigated separately, and the object relations in different views are rarely explored. In this paper, inspired by the recent great success in self-attention-based Transformer models, we reformulate the multi-view 3D reconstruction as a sequence-to-sequence prediction problem and propose a new framework named 3D Volume Transformer (VolT) for such a task. Unlike previous CNN-based methods using a separate design, we unify the feature extraction and view fusion in a single Transformer network. A natural advantage of our design lies in the exploration of view-to-view relationships using self-attention among multiple unordered inputs. On ShapeNet - a large-scale 3D reconstruction benchmark dataset, our method achieves a new state-of-the-art accuracy in multi-view reconstruction with fewer parameters ($70\%$ less) than other CNN-based methods. Experimental results also suggest the strong scaling capability of our method. Our code will be made publicly available.
CHAIN: Concept-harmonized Hierarchical Inference Interpretation of Deep Convolutional Neural Networks
Feb 05, 2020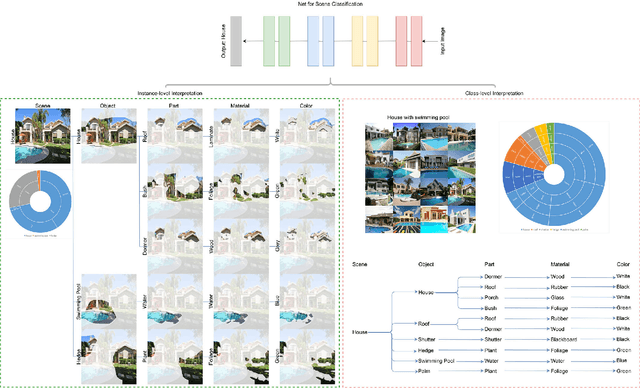
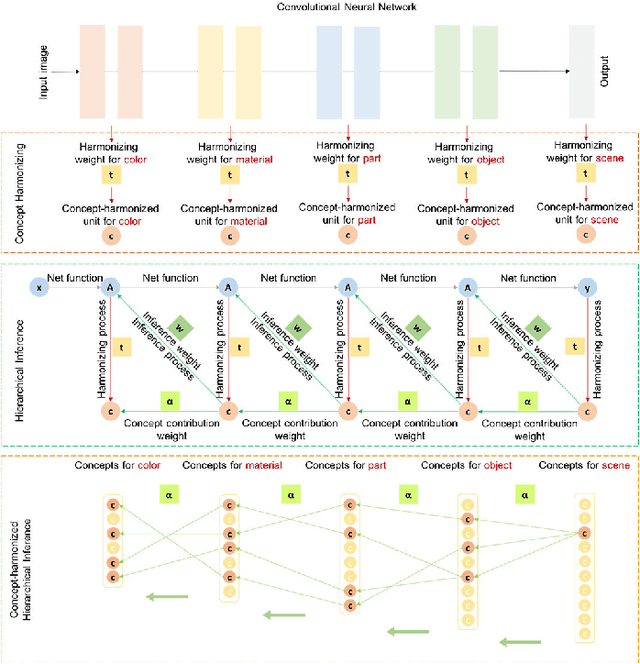


With the great success of networks, it witnesses the increasing demand for the interpretation of the internal network mechanism, especially for the net decision-making logic. To tackle the challenge, the Concept-harmonized HierArchical INference (CHAIN) is proposed to interpret the net decision-making process. For net-decisions being interpreted, the proposed method presents the CHAIN interpretation in which the net decision can be hierarchically deduced into visual concepts from high to low semantic levels. To achieve it, we propose three models sequentially, i.e., the concept harmonizing model, the hierarchical inference model, and the concept-harmonized hierarchical inference model. Firstly, in the concept harmonizing model, visual concepts from high to low semantic-levels are aligned with net-units from deep to shallow layers. Secondly, in the hierarchical inference model, the concept in a deep layer is disassembled into units in shallow layers. Finally, in the concept-harmonized hierarchical inference model, a deep-layer concept is inferred from its shallow-layer concepts. After several rounds, the concept-harmonized hierarchical inference is conducted backward from the highest semantic level to the lowest semantic level. Finally, net decision-making is explained as a form of concept-harmonized hierarchical inference, which is comparable to human decision-making. Meanwhile, the net layer structure for feature learning can be explained based on the hierarchical visual concepts. In quantitative and qualitative experiments, we demonstrate the effectiveness of CHAIN at the instance and class levels.
CHIP: Channel-wise Disentangled Interpretation of Deep Convolutional Neural Networks
Feb 07, 2019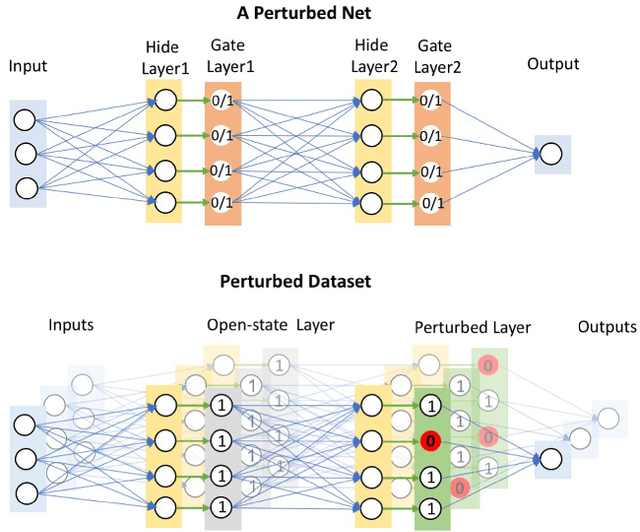

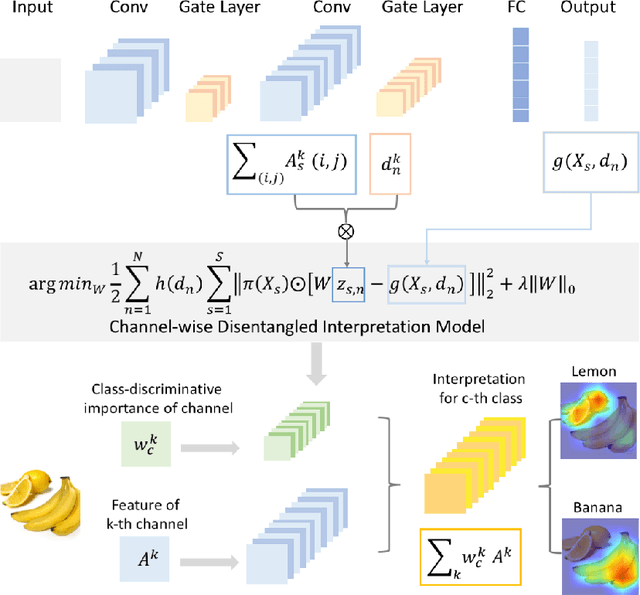

With the widespread applications of deep convolutional neural networks (DCNNs), it becomes increasingly important for DCNNs not only to make accurate predictions but also to explain how they make their decisions. In this work, we propose a CHannel-wise disentangled InterPretation (CHIP) model to give the visual interpretation to the predictions of DCNNs. The proposed model distills the class-discriminative importance of channels in networks by utilizing the sparse regularization. Here, we first introduce the network perturbation technique to learn the model. The proposed model is capable to not only distill the global perspective knowledge from networks but also present the class-discriminative visual interpretation for specific predictions of networks. It is noteworthy that the proposed model is able to interpret different layers of networks without re-training. By combining the distilled interpretation knowledge in different layers, we further propose the Refined CHIP visual interpretation that is both high-resolution and class-discriminative. Experimental results on the standard dataset demonstrate that the proposed model provides promising visual interpretation for the predictions of networks in image classification task compared with existing visual interpretation methods. Besides, the proposed method outperforms related approaches in the application of ILSVRC 2015 weakly-supervised localization task.