 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization Guided by Large-Scale Pre-Trained Priors
Jun 09, 2024Domain generalization (DG) aims to train a model from limited source domains, allowing it to generalize to unknown target domains. Typically, DG models only employ large-scale pre-trained models during the initialization of fine-tuning. However, large-scale pre-trained models already possess the ability to resist domain shift. If we reference pre-trained models continuously during fine-tuning to maintain this ability, it could further enhance the generalization ability of the DG model. For this purpose, we introduce a new method called Fine-Tune with Large-scale pre-trained Priors (FT-LP), which incorporates the pre-trained model as a prior into the DG fine-tuning process, ensuring that the model refers to its pre-trained model at each optimization step. FT-LP comprises a theoretical framework and a simple implementation strategy. In theory, we verify the rationality of FT-LP by introducing a generalization error bound with the pre-trained priors for DG. In implementation, we utilize an encoder to simulate the model distribution, enabling the use of FT-LP when only pre-trained weights are available. In summary, we offer a new fine-tuning method for DG algorithms to utilize pre-trained models throughout the fine-tuning process. Through experiments on various datasets and DG models, our proposed method exhibits significant improvements, indicating its effectiveness.
Bayesian Domain Invariant Learning via Posterior Generalization of Parameter Distributions
Oct 25, 2023Domain invariant learning aims to learn models that extract invariant features over various training domains, resulting in better generalization to unseen target domains. Recently, Bayesian Neural Networks have achieved promising results in domain invariant learning, but most works concentrate on aligning features distributions rather than parameter distributions. Inspired by the principle of Bayesian Neural Network, we attempt to directly learn the domain invariant posterior distribution of network parameters. We first propose a theorem to show that the invariant posterior of parameters can be implicitly inferred by aggregating posteriors on different training domains. Our assumption is more relaxed and allows us to extract more domain invariant information. We also propose a simple yet effective method, named PosTerior Generalization (PTG), that can be used to estimate the invariant parameter distribution. PTG fully exploits variational inference to approximate parameter distributions, including the invariant posterior and the posteriors on training domains. Furthermore, we develop a lite version of PTG for widespread applications. PTG shows competitive performance on various domain generalization benchmarks on DomainBed. Additionally, PTG can use any existing domain generalization methods as its prior, and combined with previous state-of-the-art method the performance can be further improved. Code will be made public.
Be Bayesian by Attachments to Catch More Uncertainty
Oct 19, 2023Bayesian Neural Networks (BNNs) have become one of the promising approaches for uncertainty estimation due to the solid theorical foundations. However, the performance of BNNs is affected by the ability of catching uncertainty. Instead of only seeking the distribution of neural network weights by in-distribution (ID) data, in this paper, we propose a new Bayesian Neural Network with an Attached structure (ABNN) to catch more uncertainty from out-of-distribution (OOD) data. We first construct a mathematical description for the uncertainty of OOD data according to the prior distribution, and then develop an attached Bayesian structure to integrate the uncertainty of OOD data into the backbone network. ABNN is composed of an expectation module and several distribution modules. The expectation module is a backbone deep network which focuses on the original task, and the distribution modules are mini Bayesian structures which serve as attachments of the backbone. In particular, the distribution modules aim at extracting the uncertainty from both ID and OOD data. We further provide theoretical analysis for the convergence of ABNN, and experimentally validate its superiority by comparing with some state-of-the-art uncertainty estimation methods Code will be made available.
ASM: Adaptive Skinning Model for High-Quality 3D Face Modeling
Apr 19, 2023The research fields of parametric face models and 3D face reconstruction have been extensively studied. However, a critical question remains unanswered: how to tailor the face model for specific reconstruction settings. We argue that reconstruction with multi-view uncalibrated images demands a new model with stronger capacity. Our study shifts attention from data-dependent 3D Morphable Models (3DMM) to an understudied human-designed skinning model. We propose Adaptive Skinning Model (ASM), which redefines the skinning model with more compact and fully tunable parameters. With extensive experiments, we demonstrate that ASM achieves significantly improved capacity than 3DMM, with the additional advantage of model size and easy implementation for new topology. We achieve state-of-the-art performance with ASM for multi-view reconstruction on the Florence MICC Coop benchmark. Our quantitative analysis demonstrates the importance of a high-capacity model for fully exploiting abundant information from multi-view input in reconstruction. Furthermore, our model with physical-semantic parameters can be directly utilized for real-world applications, such as in-game avatar creation. As a result, our work opens up new research directions for the parametric face models and facilitates future research on multi-view reconstruction.
Multi-view 3D Reconstruction with Transformer
Mar 24, 2021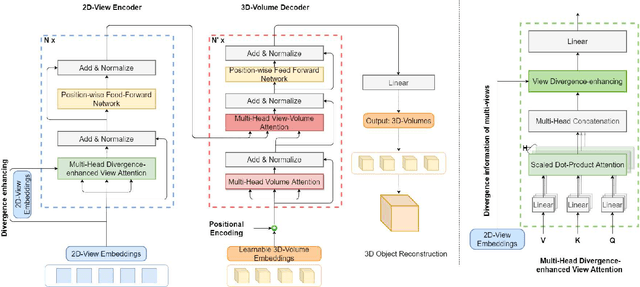



Deep CNN-based methods have so far achieved the state of the art results in multi-view 3D object reconstruction. Despite the considerable progress, the two core modules of these methods - multi-view feature extraction and fusion, are usually investigated separately, and the object relations in different views are rarely explored. In this paper, inspired by the recent great success in self-attention-based Transformer models, we reformulate the multi-view 3D reconstruction as a sequence-to-sequence prediction problem and propose a new framework named 3D Volume Transformer (VolT) for such a task. Unlike previous CNN-based methods using a separate design, we unify the feature extraction and view fusion in a single Transformer network. A natural advantage of our design lies in the exploration of view-to-view relationships using self-attention among multiple unordered inputs. On ShapeNet - a large-scale 3D reconstruction benchmark dataset, our method achieves a new state-of-the-art accuracy in multi-view reconstruction with fewer parameters ($70\%$ less) than other CNN-based methods. Experimental results also suggest the strong scaling capability of our method. Our code will be made publicly available.
Single-Shot Motion Completion with Transformer
Mar 01, 2021
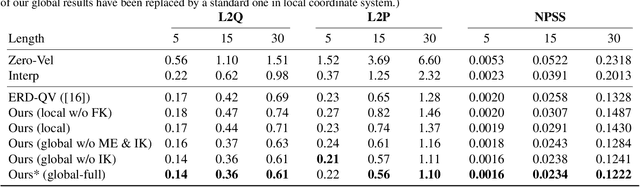
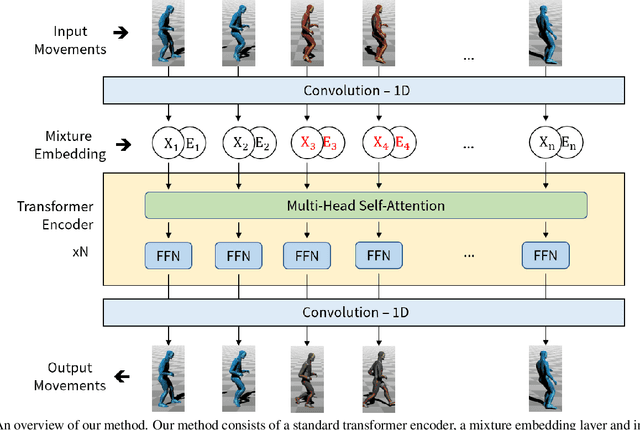
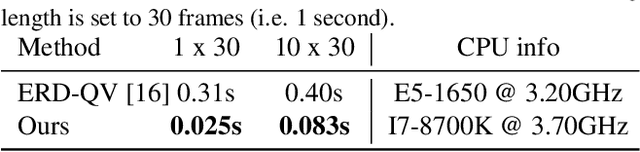
Motion completion is a challenging and long-discussed problem, which is of great significance in film and game applications. For different motion completion scenarios (in-betweening, in-filling, and blending), most previous methods deal with the completion problems with case-by-case designs. In this work, we propose a simple but effective method to solve multiple motion completion problems under a unified framework and achieves a new state of the art accuracy under multiple evaluation settings. Inspired by the recent great success of attention-based models, we consider the completion as a sequence to sequence prediction problem. Our method consists of two modules - a standard transformer encoder with self-attention that learns long-range dependencies of input motions, and a trainable mixture embedding module that models temporal information and discriminates key-frames. Our method can run in a non-autoregressive manner and predict multiple missing frames within a single forward propagation in real time. We finally show the effectiveness of our method in music-dance applications.
NeuralMagicEye: Learning to See and Understand the Scene Behind an Autostereogram
Dec 31, 2020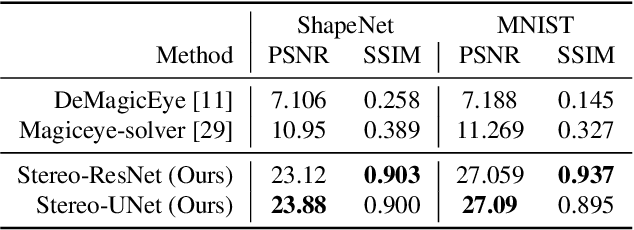
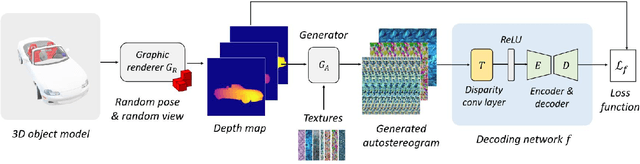
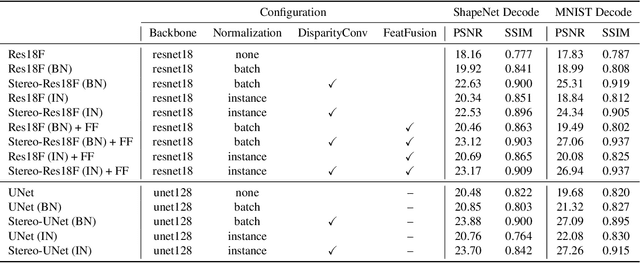
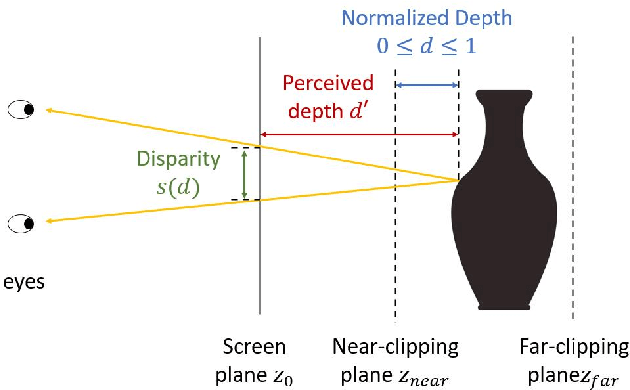
An autostereogram, a.k.a. magic eye image, is a single-image stereogram that can create visual illusions of 3D scenes from 2D textures. This paper studies an interesting question that whether a deep CNN can be trained to recover the depth behind an autostereogram and understand its content. The key to the autostereogram magic lies in the stereopsis - to solve such a problem, a model has to learn to discover and estimate disparity from the quasi-periodic textures. We show that deep CNNs embedded with disparity convolution, a novel convolutional layer proposed in this paper that simulates stereopsis and encodes disparity, can nicely solve such a problem after being sufficiently trained on a large 3D object dataset in a self-supervised fashion. We refer to our method as ``NeuralMagicEye''. Experiments show that our method can accurately recover the depth behind autostereograms with rich details and gradient smoothness. Experiments also show the completely different working mechanisms for autostereogram perception between neural networks and human eyes. We hope this research can help people with visual impairments and those who have trouble viewing autostereograms. Our code is available at \url{https://jiupinjia.github.io/neuralmagiceye/}.
Stylized Neural Painting
Nov 16, 2020
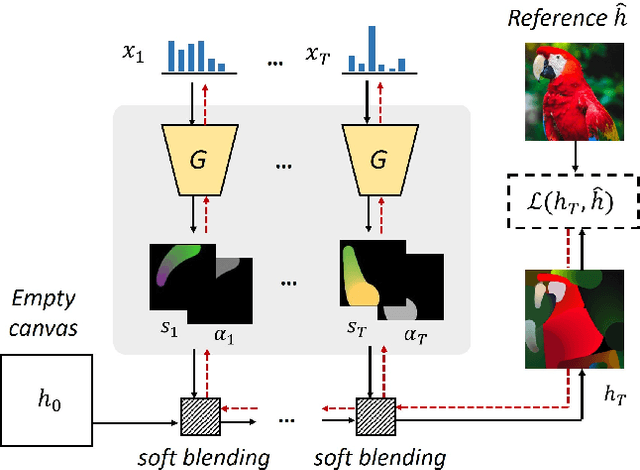
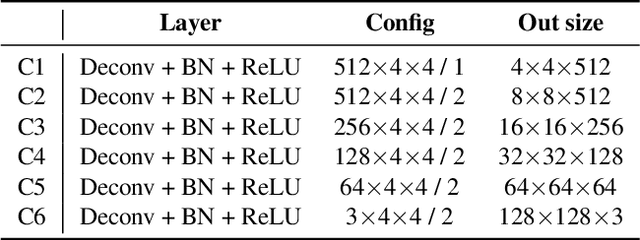
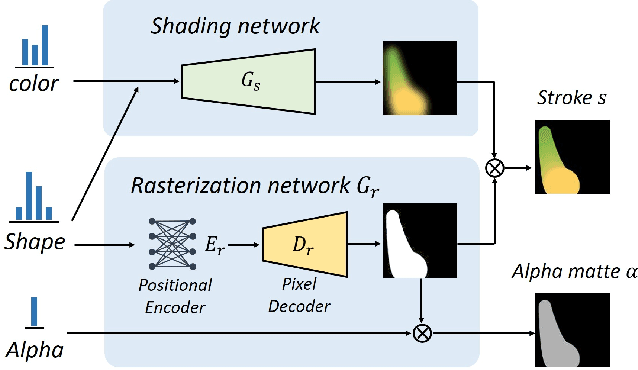
This paper proposes an image-to-painting translation method that generates vivid and realistic painting artworks with controllable styles. Different from previous image-to-image translation methods that formulate the translation as pixel-wise prediction, we deal with such an artistic creation process in a vectorized environment and produce a sequence of physically meaningful stroke parameters that can be further used for rendering. Since a typical vector render is not differentiable, we design a novel neural renderer which imitates the behavior of the vector renderer and then frame the stroke prediction as a parameter searching process that maximizes the similarity between the input and the rendering output. We explored the zero-gradient problem on parameter searching and propose to solve this problem from an optimal transportation perspective. We also show that previous neural renderers have a parameter coupling problem and we re-design the rendering network with a rasterization network and a shading network that better handles the disentanglement of shape and color. Experiments show that the paintings generated by our method have a high degree of fidelity in both global appearance and local textures. Our method can be also jointly optimized with neural style transfer that further transfers visual style from other images. Our code and animated results are available at \url{https://jiupinjia.github.io/neuralpainter/}.
Semi-Supervised Learning for In-Game Expert-Level Music-to-Dance Translation
Sep 27, 2020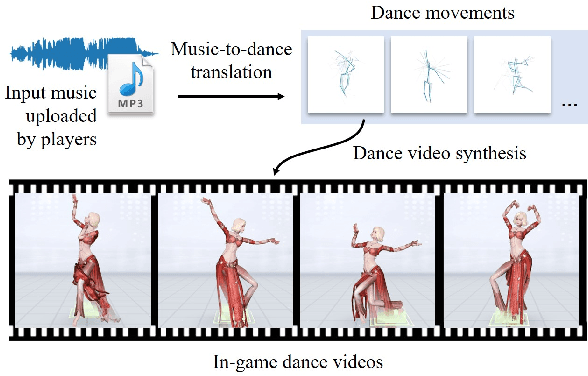

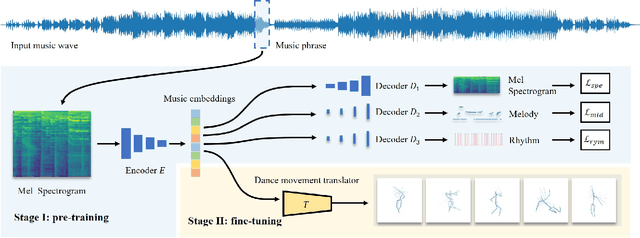

Music-to-dance translation is a brand-new and powerful feature in recent role-playing games. Players can now let their characters dance along with specified music clips and even generate fan-made dance videos. Previous works of this topic consider music-to-dance as a supervised motion generation problem based on time-series data. However, these methods suffer from limited training data pairs and the degradation of movements. This paper provides a new perspective for this task where we re-formulate the translation problem as a piece-wise dance phrase retrieval problem based on the choreography theory. With such a design, players are allowed to further edit the dance movements on top of our generation while other regression based methods ignore such user interactivity. Considering that the dance motion capture is an expensive and time-consuming procedure which requires the assistance of professional dancers, we train our method under a semi-supervised learning framework with a large unlabeled dataset (20x than labeled data) collected. A co-ascent mechanism is introduced to improve the robustness of our network. Using this unlabeled dataset, we also introduce self-supervised pre-training so that the translator can understand the melody, rhythm, and other components of music phrases. We show that the pre-training significantly improves the translation accuracy than that of training from scratch. Experimental results suggest that our method not only generalizes well over various styles of music but also succeeds in expert-level choreography for game players.
Unsupervised Learning Facial Parameter Regressor for Action Unit Intensity Estimation via Differentiable Renderer
Aug 20, 2020
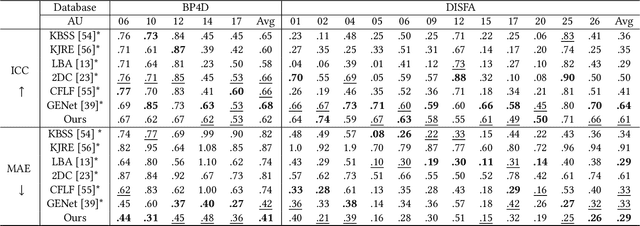
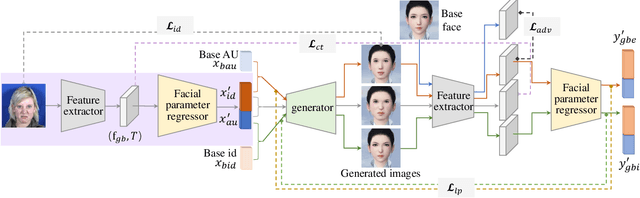

Facial action unit (AU) intensity is an index to describe all visually discernible facial movements. Most existing methods learn intensity estimator with limited AU data, while they lack generalization ability out of the dataset. In this paper, we present a framework to predict the facial parameters (including identity parameters and AU parameters) based on a bone-driven face model (BDFM) under different views. The proposed framework consists of a feature extractor, a generator, and a facial parameter regressor. The regressor can fit the physical meaning parameters of the BDFM from a single face image with the help of the generator, which maps the facial parameters to the game-face images as a differentiable renderer. Besides, identity loss, loopback loss, and adversarial loss can improve the regressive results. Quantitative evaluations are performed on two public databases BP4D and DISFA, which demonstrates that the proposed method can achieve comparable or better performance than the state-of-the-art methods. What's more, the qualitative results also demonstrate the validity of our method in the wild.