 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGencho: Room Impulse Response Generation from Reverberant Speech and Text via Diffusion Transformers
Feb 09, 2026Blind room impulse response (RIR) estimation is a core task for capturing and transferring acoustic properties; yet existing methods often suffer from limited modeling capability and degraded performance under unseen conditions. Moreover, emerging generative audio applications call for more flexible impulse response generation methods. We propose Gencho, a diffusion-transformer-based model that predicts complex spectrogram RIRs from reverberant speech. A structure-aware encoder leverages isolation between early and late reflections to encode the input audio into a robust representation for conditioning, while the diffusion decoder generates diverse and perceptually realistic impulse responses from it. Gencho integrates modularly with standard speech processing pipelines for acoustic matching. Results show richer generated RIRs than non-generative baselines while maintaining strong performance in standard RIR metrics. We further demonstrate its application to text-conditioned RIR generation, highlighting Gencho's versatility for controllable acoustic simulation and generative audio tasks.
Deep Room Impulse Response Completion
Feb 01, 2024Rendering immersive spatial audio in virtual reality (VR) and video games demands a fast and accurate generation of room impulse responses (RIRs) to recreate auditory environments plausibly. However, the conventional methods for simulating or measuring long RIRs are either computationally intensive or challenged by low signal-to-noise ratios. This study is propelled by the insight that direct sound and early reflections encapsulate sufficient information about room geometry and absorption characteristics. Building upon this premise, we propose a novel task termed "RIR completion," aimed at synthesizing the late reverberation given only the early portion (50 ms) of the response. To this end, we introduce DECOR, Deep Exponential Completion Of Room impulse responses, a deep neural network structured as an autoencoder designed to predict multi-exponential decay envelopes of filtered noise sequences. The interpretability of DECOR's output facilitates its integration with diverse rendering techniques. The proposed method is compared against an adapted state-of-the-art network, and comparable performance shows promising results supporting the feasibility of the RIR completion task. The RIR completion can be widely adapted to enhance RIR generation tasks where fast late reverberation approximation is required.
Unsupervised Learning Facial Parameter Regressor for Action Unit Intensity Estimation via Differentiable Renderer
Aug 20, 2020
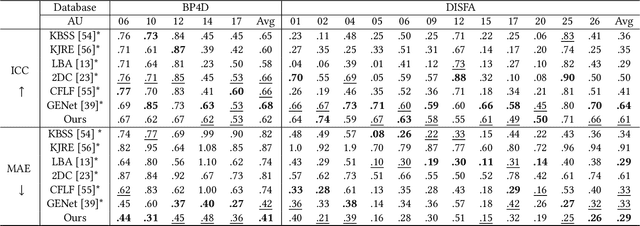
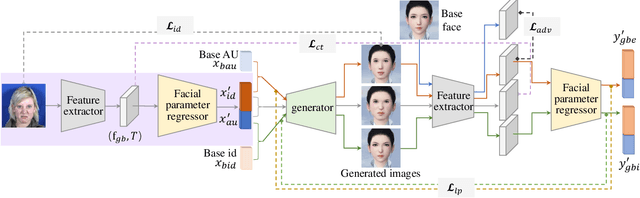

Facial action unit (AU) intensity is an index to describe all visually discernible facial movements. Most existing methods learn intensity estimator with limited AU data, while they lack generalization ability out of the dataset. In this paper, we present a framework to predict the facial parameters (including identity parameters and AU parameters) based on a bone-driven face model (BDFM) under different views. The proposed framework consists of a feature extractor, a generator, and a facial parameter regressor. The regressor can fit the physical meaning parameters of the BDFM from a single face image with the help of the generator, which maps the facial parameters to the game-face images as a differentiable renderer. Besides, identity loss, loopback loss, and adversarial loss can improve the regressive results. Quantitative evaluations are performed on two public databases BP4D and DISFA, which demonstrates that the proposed method can achieve comparable or better performance than the state-of-the-art methods. What's more, the qualitative results also demonstrate the validity of our method in the wild.