 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning Facial Parameter Regressor for Action Unit Intensity Estimation via Differentiable Renderer
Aug 20, 2020
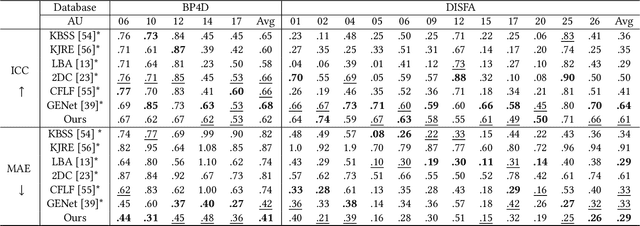
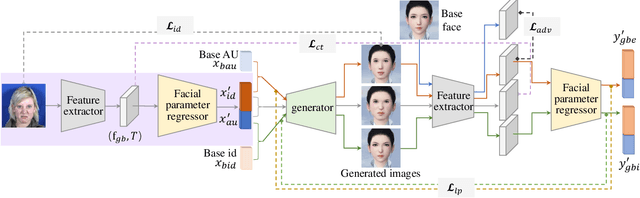

Facial action unit (AU) intensity is an index to describe all visually discernible facial movements. Most existing methods learn intensity estimator with limited AU data, while they lack generalization ability out of the dataset. In this paper, we present a framework to predict the facial parameters (including identity parameters and AU parameters) based on a bone-driven face model (BDFM) under different views. The proposed framework consists of a feature extractor, a generator, and a facial parameter regressor. The regressor can fit the physical meaning parameters of the BDFM from a single face image with the help of the generator, which maps the facial parameters to the game-face images as a differentiable renderer. Besides, identity loss, loopback loss, and adversarial loss can improve the regressive results. Quantitative evaluations are performed on two public databases BP4D and DISFA, which demonstrates that the proposed method can achieve comparable or better performance than the state-of-the-art methods. What's more, the qualitative results also demonstrate the validity of our method in the wild.
Neutral Face Game Character Auto-Creation via PokerFace-GAN
Aug 17, 2020



Game character customization is one of the core features of many recent Role-Playing Games (RPGs), where players can edit the appearance of their in-game characters with their preferences. This paper studies the problem of automatically creating in-game characters with a single photo. In recent literature on this topic, neural networks are introduced to make game engine differentiable and the self-supervised learning is used to predict facial customization parameters. However, in previous methods, the expression parameters and facial identity parameters are highly coupled with each other, making it difficult to model the intrinsic facial features of the character. Besides, the neural network based renderer used in previous methods is also difficult to be extended to multi-view rendering cases. In this paper, considering the above problems, we propose a novel method named "PokerFace-GAN" for neutral face game character auto-creation. We first build a differentiable character renderer which is more flexible than the previous methods in multi-view rendering cases. We then take advantage of the adversarial training to effectively disentangle the expression parameters from the identity parameters and thus generate player-preferred neutral face (expression-less) characters. Since all components of our method are differentiable, our method can be easily trained under a multi-task self-supervised learning paradigm. Experiment results show that our method can generate vivid neutral face game characters that are highly similar to the input photos. The effectiveness of our method is verified by comparison results and ablation studies.
Unsupervised Facial Action Unit Intensity Estimation via Differentiable Optimization
Apr 13, 2020

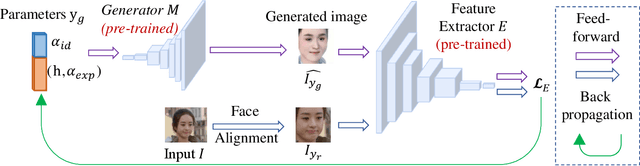
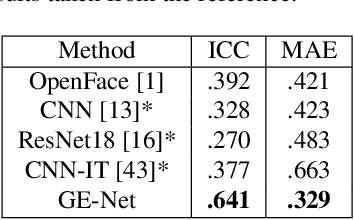
The automatic intensity estimation of facial action units (AUs) from a single image plays a vital role in facial analysis systems. One big challenge for data-driven AU intensity estimation is the lack of sufficient AU label data. Due to the fact that AU annotation requires strong domain expertise, it is expensive to construct an extensive database to learn deep models. The limited number of labeled AUs as well as identity differences and pose variations further increases the estimation difficulties. Considering all these difficulties, we propose an unsupervised framework GE-Net for facial AU intensity estimation from a single image, without requiring any annotated AU data. Our framework performs differentiable optimization, which iteratively updates the facial parameters (i.e., head pose, AU parameters and identity parameters) to match the input image. GE-Net consists of two modules: a generator and a feature extractor. The generator learns to "render" a face image from a set of facial parameters in a differentiable way, and the feature extractor extracts deep features for measuring the similarity of the rendered image and input real image. After the two modules are trained and fixed, the framework searches optimal facial parameters by minimizing the differences of the extracted features between the rendered image and the input image. Experimental results demonstrate that our method can achieve state-of-the-art results compared with existing methods.