 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Facial Action Unit Intensity Estimation via Differentiable Optimization
Paper and Code


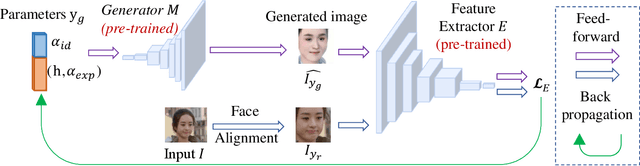
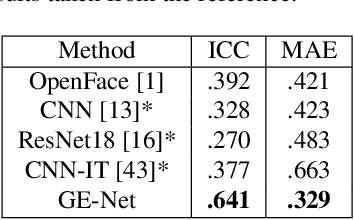
The automatic intensity estimation of facial action units (AUs) from a single image plays a vital role in facial analysis systems. One big challenge for data-driven AU intensity estimation is the lack of sufficient AU label data. Due to the fact that AU annotation requires strong domain expertise, it is expensive to construct an extensive database to learn deep models. The limited number of labeled AUs as well as identity differences and pose variations further increases the estimation difficulties. Considering all these difficulties, we propose an unsupervised framework GE-Net for facial AU intensity estimation from a single image, without requiring any annotated AU data. Our framework performs differentiable optimization, which iteratively updates the facial parameters (i.e., head pose, AU parameters and identity parameters) to match the input image. GE-Net consists of two modules: a generator and a feature extractor. The generator learns to "render" a face image from a set of facial parameters in a differentiable way, and the feature extractor extracts deep features for measuring the similarity of the rendered image and input real image. After the two modules are trained and fixed, the framework searches optimal facial parameters by minimizing the differences of the extracted features between the rendered image and the input image. Experimental results demonstrate that our method can achieve state-of-the-art results compared with existing methods.