 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdAgent: Multi-Agent Managed Multi-Source Annotation System
Sep 17, 2025High-quality annotated data is a cornerstone of modern Natural Language Processing (NLP). While recent methods begin to leverage diverse annotation sources-including Large Language Models (LLMs), Small Language Models (SLMs), and human experts-they often focus narrowly on the labeling step itself. A critical gap remains in the holistic process control required to manage these sources dynamically, addressing complex scheduling and quality-cost trade-offs in a unified manner. Inspired by real-world crowdsourcing companies, we introduce CrowdAgent, a multi-agent system that provides end-to-end process control by integrating task assignment, data annotation, and quality/cost management. It implements a novel methodology that rationally assigns tasks, enabling LLMs, SLMs, and human experts to advance synergistically in a collaborative annotation workflow. We demonstrate the effectiveness of CrowdAgent through extensive experiments on six diverse multimodal classification tasks. The source code and video demo are available at https://github.com/QMMMS/CrowdAgent.
Empowering Economic Simulation for Massively Multiplayer Online Games through Generative Agent-Based Modeling
Jun 05, 2025Within the domain of Massively Multiplayer Online (MMO) economy research, Agent-Based Modeling (ABM) has emerged as a robust tool for analyzing game economics, evolving from rule-based agents to decision-making agents enhanced by reinforcement learning. Nevertheless, existing works encounter significant challenges when attempting to emulate human-like economic activities among agents, particularly regarding agent reliability, sociability, and interpretability. In this study, we take a preliminary step in introducing a novel approach using Large Language Models (LLMs) in MMO economy simulation. Leveraging LLMs' role-playing proficiency, generative capacity, and reasoning aptitude, we design LLM-driven agents with human-like decision-making and adaptability. These agents are equipped with the abilities of role-playing, perception, memory, and reasoning, addressing the aforementioned challenges effectively. Simulation experiments focusing on in-game economic activities demonstrate that LLM-empowered agents can promote emergent phenomena like role specialization and price fluctuations in line with market rules.
Fast-DataShapley: Neural Modeling for Training Data Valuation
Jun 05, 2025The value and copyright of training data are crucial in the artificial intelligence industry. Service platforms should protect data providers' legitimate rights and fairly reward them for their contributions. Shapley value, a potent tool for evaluating contributions, outperforms other methods in theory, but its computational overhead escalates exponentially with the number of data providers. Recent works based on Shapley values attempt to mitigate computation complexity by approximation algorithms. However, they need to retrain for each test sample, leading to intolerable costs. We propose Fast-DataShapley, a one-pass training method that leverages the weighted least squares characterization of the Shapley value to train a reusable explainer model with real-time reasoning speed. Given new test samples, no retraining is required to calculate the Shapley values of the training data. Additionally, we propose three methods with theoretical guarantees to reduce training overhead from two aspects: the approximate calculation of the utility function and the group calculation of the training data. We analyze time complexity to show the efficiency of our methods. The experimental evaluations on various image datasets demonstrate superior performance and efficiency compared to baselines. Specifically, the performance is improved to more than 2.5 times, and the explainer's training speed can be increased by two orders of magnitude.
MVP-Shapley: Feature-based Modeling for Evaluating the Most Valuable Player in Basketball
Jun 05, 2025The burgeoning growth of the esports and multiplayer online gaming community has highlighted the critical importance of evaluating the Most Valuable Player (MVP). The establishment of an explainable and practical MVP evaluation method is very challenging. In our study, we specifically focus on play-by-play data, which records related events during the game, such as assists and points. We aim to address the challenges by introducing a new MVP evaluation framework, denoted as \oursys, which leverages Shapley values. This approach encompasses feature processing, win-loss model training, Shapley value allocation, and MVP ranking determination based on players' contributions. Additionally, we optimize our algorithm to align with expert voting results from the perspective of causality. Finally, we substantiated the efficacy of our method through validation using the NBA dataset and the Dunk City Dynasty dataset and implemented online deployment in the industry.
Digital Player: Evaluating Large Language Models based Human-like Agent in Games
Feb 28, 2025With the rapid advancement of Large Language Models (LLMs), LLM-based autonomous agents have shown the potential to function as digital employees, such as digital analysts, teachers, and programmers. In this paper, we develop an application-level testbed based on the open-source strategy game "Unciv", which has millions of active players, to enable researchers to build a "data flywheel" for studying human-like agents in the "digital players" task. This "Civilization"-like game features expansive decision-making spaces along with rich linguistic interactions such as diplomatic negotiations and acts of deception, posing significant challenges for LLM-based agents in terms of numerical reasoning and long-term planning. Another challenge for "digital players" is to generate human-like responses for social interaction, collaboration, and negotiation with human players. The open-source project can be found at https:/github.com/fuxiAIlab/CivAgent.
Rank Aggregation in Crowdsourcing for Listwise Annotations
Oct 10, 2024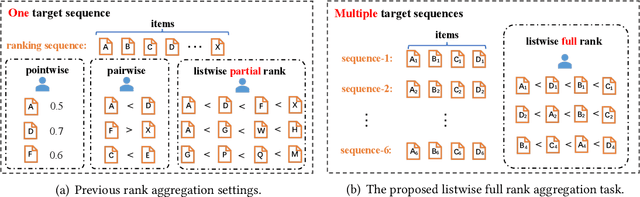



Rank aggregation through crowdsourcing has recently gained significant attention, particularly in the context of listwise ranking annotations. However, existing methods primarily focus on a single problem and partial ranks, while the aggregation of listwise full ranks across numerous problems remains largely unexplored. This scenario finds relevance in various applications, such as model quality assessment and reinforcement learning with human feedback. In light of practical needs, we propose LAC, a Listwise rank Aggregation method in Crowdsourcing, where the global position information is carefully measured and included. In our design, an especially proposed annotation quality indicator is employed to measure the discrepancy between the annotated rank and the true rank. We also take the difficulty of the ranking problem itself into consideration, as it directly impacts the performance of annotators and consequently influences the final results. To our knowledge, LAC is the first work to directly deal with the full rank aggregation problem in listwise crowdsourcing, and simultaneously infer the difficulty of problems, the ability of annotators, and the ground-truth ranks in an unsupervised way. To evaluate our method, we collect a real-world business-oriented dataset for paragraph ranking. Experimental results on both synthetic and real-world benchmark datasets demonstrate the effectiveness of our proposed LAC method.
Storynizor: Consistent Story Generation via Inter-Frame Synchronized and Shuffled ID Injection
Sep 29, 2024

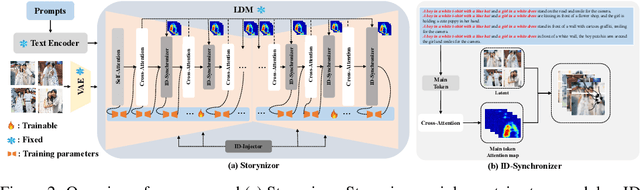
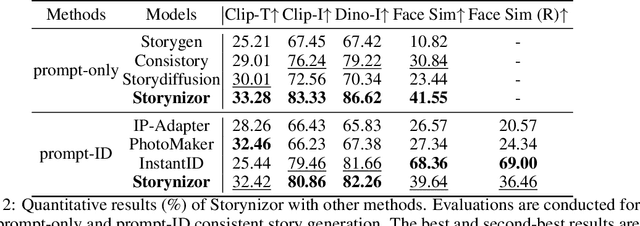
Recent advances in text-to-image diffusion models have spurred significant interest in continuous story image generation. In this paper, we introduce Storynizor, a model capable of generating coherent stories with strong inter-frame character consistency, effective foreground-background separation, and diverse pose variation. The core innovation of Storynizor lies in its key modules: ID-Synchronizer and ID-Injector. The ID-Synchronizer employs an auto-mask self-attention module and a mask perceptual loss across inter-frame images to improve the consistency of character generation, vividly representing their postures and backgrounds. The ID-Injector utilize a Shuffling Reference Strategy (SRS) to integrate ID features into specific locations, enhancing ID-based consistent character generation. Additionally, to facilitate the training of Storynizor, we have curated a novel dataset called StoryDB comprising 100, 000 images. This dataset contains single and multiple-character sets in diverse environments, layouts, and gestures with detailed descriptions. Experimental results indicate that Storynizor demonstrates superior coherent story generation with high-fidelity character consistency, flexible postures, and vivid backgrounds compared to other character-specific methods.
StyleTalk++: A Unified Framework for Controlling the Speaking Styles of Talking Heads
Sep 14, 2024



Individuals have unique facial expression and head pose styles that reflect their personalized speaking styles. Existing one-shot talking head methods cannot capture such personalized characteristics and therefore fail to produce diverse speaking styles in the final videos. To address this challenge, we propose a one-shot style-controllable talking face generation method that can obtain speaking styles from reference speaking videos and drive the one-shot portrait to speak with the reference speaking styles and another piece of audio. Our method aims to synthesize the style-controllable coefficients of a 3D Morphable Model (3DMM), including facial expressions and head movements, in a unified framework. Specifically, the proposed framework first leverages a style encoder to extract the desired speaking styles from the reference videos and transform them into style codes. Then, the framework uses a style-aware decoder to synthesize the coefficients of 3DMM from the audio input and style codes. During decoding, our framework adopts a two-branch architecture, which generates the stylized facial expression coefficients and stylized head movement coefficients, respectively. After obtaining the coefficients of 3DMM, an image renderer renders the expression coefficients into a specific person's talking-head video. Extensive experiments demonstrate that our method generates visually authentic talking head videos with diverse speaking styles from only one portrait image and an audio clip.
EA-RAS: Towards Efficient and Accurate End-to-End Reconstruction of Anatomical Skeleton
Sep 03, 2024



Efficient, accurate and low-cost estimation of human skeletal information is crucial for a range of applications such as biology education and human-computer interaction. However, current simple skeleton models, which are typically based on 2D-3D joint points, fall short in terms of anatomical fidelity, restricting their utility in fields. On the other hand, more complex models while anatomically precise, are hindered by sophisticate multi-stage processing and the need for extra data like skin meshes, making them unsuitable for real-time applications. To this end, we propose the EA-RAS (Towards Efficient and Accurate End-to-End Reconstruction of Anatomical Skeleton), a single-stage, lightweight, and plug-and-play anatomical skeleton estimator that can provide real-time, accurate anatomically realistic skeletons with arbitrary pose using only a single RGB image input. Additionally, EA-RAS estimates the conventional human-mesh model explicitly, which not only enhances the functionality but also leverages the outside skin information by integrating features into the inside skeleton modeling process. In this work, we also develop a progressive training strategy and integrated it with an enhanced optimization process, enabling the network to obtain initial weights using only a small skin dataset and achieve self-supervision in skeleton reconstruction. Besides, we also provide an optional lightweight post-processing optimization strategy to further improve accuracy for scenarios that prioritize precision over real-time processing. The experiments demonstrated that our regression method is over 800 times faster than existing methods, meeting real-time requirements. Additionally, the post-processing optimization strategy provided can enhance reconstruction accuracy by over 50% and achieve a speed increase of more than 7 times.
LLM4GEN: Leveraging Semantic Representation of LLMs for Text-to-Image Generation
Jun 30, 2024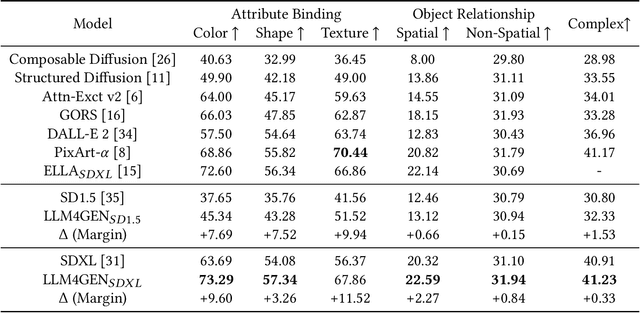
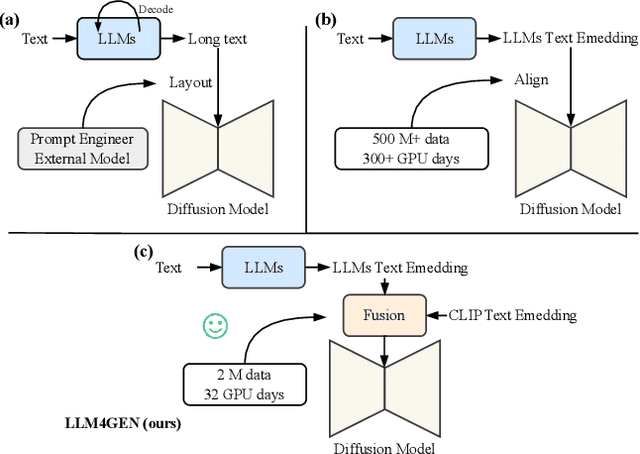


Diffusion Models have exhibited substantial success in text-to-image generation. However, they often encounter challenges when dealing with complex and dense prompts that involve multiple objects, attribute binding, and long descriptions. This paper proposes a framework called \textbf{LLM4GEN}, which enhances the semantic understanding ability of text-to-image diffusion models by leveraging the semantic representation of Large Language Models (LLMs). Through a specially designed Cross-Adapter Module (CAM) that combines the original text features of text-to-image models with LLM features, LLM4GEN can be easily incorporated into various diffusion models as a plug-and-play component and enhances text-to-image generation. Additionally, to facilitate the complex and dense prompts semantic understanding, we develop a LAION-refined dataset, consisting of 1 million (M) text-image pairs with improved image descriptions. We also introduce DensePrompts which contains 7,000 dense prompts to provide a comprehensive evaluation for the text-to-image generation task. With just 10\% of the training data required by recent ELLA, LLM4GEN significantly improves the semantic alignment of SD1.5 and SDXL, demonstrating increases of 7.69\% and 9.60\% in color on T2I-CompBench, respectively. The extensive experiments on DensePrompts also demonstrate that LLM4GEN surpasses existing state-of-the-art models in terms of sample quality, image-text alignment, and human evaluation. The project website is at: \textcolor{magenta}{\url{https://xiaobul.github.io/LLM4GEN/}}