 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTB-HSU: Hierarchical 3D Scene Understanding with Contextual Affordances
Dec 07, 2024The concept of function and affordance is a critical aspect of 3D scene understanding and supports task-oriented objectives. In this work, we develop a model that learns to structure and vary functional affordance across a 3D hierarchical scene graph representing the spatial organization of a scene. The varying functional affordance is designed to integrate with the varying spatial context of the graph. More specifically, we develop an algorithm that learns to construct a 3D hierarchical scene graph (3DHSG) that captures the spatial organization of the scene. Starting from segmented object point clouds and object semantic labels, we develop a 3DHSG with a top node that identifies the room label, child nodes that define local spatial regions inside the room with region-specific affordances, and grand-child nodes indicating object locations and object-specific affordances. To support this work, we create a custom 3DHSG dataset that provides ground truth data for local spatial regions with region-specific affordances and also object-specific affordances for each object. We employ a transformer-based model to learn the 3DHSG. We use a multi-task learning framework that learns both room classification and learns to define spatial regions within the room with region-specific affordances. Our work improves on the performance of state-of-the-art baseline models and shows one approach for applying transformer models to 3D scene understanding and the generation of 3DHSGs that capture the spatial organization of a room. The code and dataset are publicly available.
Storynizor: Consistent Story Generation via Inter-Frame Synchronized and Shuffled ID Injection
Sep 29, 2024

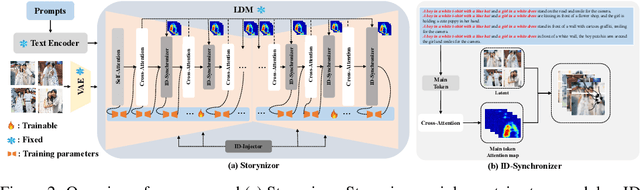
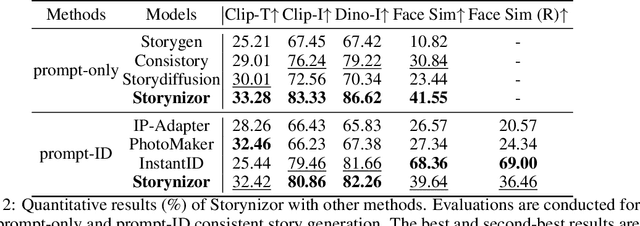
Recent advances in text-to-image diffusion models have spurred significant interest in continuous story image generation. In this paper, we introduce Storynizor, a model capable of generating coherent stories with strong inter-frame character consistency, effective foreground-background separation, and diverse pose variation. The core innovation of Storynizor lies in its key modules: ID-Synchronizer and ID-Injector. The ID-Synchronizer employs an auto-mask self-attention module and a mask perceptual loss across inter-frame images to improve the consistency of character generation, vividly representing their postures and backgrounds. The ID-Injector utilize a Shuffling Reference Strategy (SRS) to integrate ID features into specific locations, enhancing ID-based consistent character generation. Additionally, to facilitate the training of Storynizor, we have curated a novel dataset called StoryDB comprising 100, 000 images. This dataset contains single and multiple-character sets in diverse environments, layouts, and gestures with detailed descriptions. Experimental results indicate that Storynizor demonstrates superior coherent story generation with high-fidelity character consistency, flexible postures, and vivid backgrounds compared to other character-specific methods.
Character-Adapter: Prompt-Guided Region Control for High-Fidelity Character Customization
Jun 24, 2024



Customized image generation, which seeks to synthesize images with consistent characters, holds significant relevance for applications such as storytelling, portrait generation, and character design. However, previous approaches have encountered challenges in preserving characters with high-fidelity consistency due to inadequate feature extraction and concept confusion of reference characters. Therefore, we propose Character-Adapter, a plug-and-play framework designed to generate images that preserve the details of reference characters, ensuring high-fidelity consistency. Character-Adapter employs prompt-guided segmentation to ensure fine-grained regional features of reference characters and dynamic region-level adapters to mitigate concept confusion. Extensive experiments are conducted to validate the effectiveness of Character-Adapter. Both quantitative and qualitative results demonstrate that Character-Adapter achieves the state-of-the-art performance of consistent character generation, with an improvement of 24.8% compared with other methods
MvCo-DoT:Multi-View Contrastive Domain Transfer Network for Medical Report Generation
Apr 15, 2023In clinical scenarios, multiple medical images with different views are usually generated at the same time, and they have high semantic consistency. However, the existing medical report generation methods cannot exploit the rich multi-view mutual information of medical images. Therefore, in this work, we propose the first multi-view medical report generation model, called MvCo-DoT. Specifically, MvCo-DoT first propose a multi-view contrastive learning (MvCo) strategy to help the deep reinforcement learning based model utilize the consistency of multi-view inputs for better model learning. Then, to close the performance gaps of using multi-view and single-view inputs, a domain transfer network is further proposed to ensure MvCo-DoT achieve almost the same performance as multi-view inputs using only single-view inputs.Extensive experiments on the IU X-Ray public dataset show that MvCo-DoT outperforms the SOTA medical report generation baselines in all metrics.
Reinforced Medical Report Generation with X-Linear Attention and Repetition Penalty
Nov 16, 2020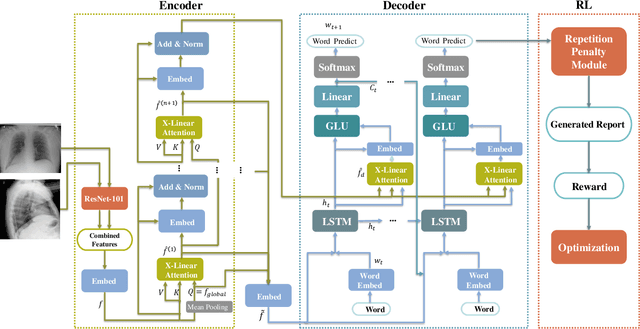
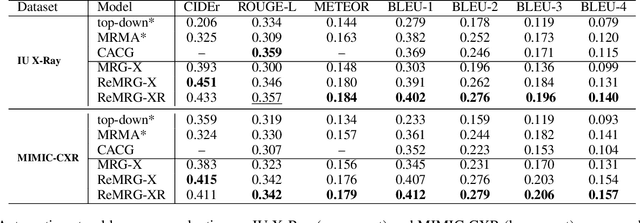

To reduce doctors' workload, deep-learning-based automatic medical report generation has recently attracted more and more research efforts, where attention mechanisms and reinforcement learning are integrated with the classic encoder-decoder architecture to enhance the performance of deep models. However, these state-of-the-art solutions mainly suffer from two shortcomings: (i) their attention mechanisms cannot utilize high-order feature interactions, and (ii) due to the use of TF-IDF-based reward functions, these methods are fragile with generating repeated terms. Therefore, in this work, we propose a reinforced medical report generation solution with x-linear attention and repetition penalty mechanisms (ReMRG-XR) to overcome these problems. Specifically, x-linear attention modules are used to explore high-order feature interactions and achieve multi-modal reasoning, while repetition penalty is used to apply penalties to repeated terms during the model's training process. Extensive experimental studies have been conducted on two public datasets, and the results show that ReMRG-XR greatly outperforms the state-of-the-art baselines in terms of all metrics.