 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynoJEPP: Joint Estimation, Prediction and Planning in Dynamic Environments
May 13, 2026DynoJEPP is a factor-graph-based framework that jointly formulates and simultaneously optimizes estimation, prediction, and planning in dynamic environments. In conventional factor-graph-based approaches that jointly formulate estimation, prediction, and planning, information from prediction and planning feeds back into state estimation, yielding corrupted estimates, undesired behaviors, and unsafe plans. To address this, DynoJEPP introduces a novel directed factor that enforces directional information flow within the factor graph, preventing prediction and planning from corrupting state estimation. We evaluate the impact of directed factors on inter-module interactions during navigation in both static and dynamic environments. Our results demonstrate that these factors are critical for safe operation, as without them, the robot collides in the majority of experiments. Building on this, we further introduce Cooperative DynoJEPP, which enables the ego robot to incorporate cooperative object behavior into its prediction and trajectory planning.
Online Dynamic SLAM with Incremental Smoothing and Mapping
Sep 10, 2025Dynamic SLAM methods jointly estimate for the static and dynamic scene components, however existing approaches, while accurate, are computationally expensive and unsuitable for online applications. In this work, we present the first application of incremental optimisation techniques to Dynamic SLAM. We introduce a novel factor-graph formulation and system architecture designed to take advantage of existing incremental optimisation methods and support online estimation. On multiple datasets, we demonstrate that our method achieves equal to or better than state-of-the-art in camera pose and object motion accuracy. We further analyse the structural properties of our approach to demonstrate its scalability and provide insight regarding the challenges of solving Dynamic SLAM incrementally. Finally, we show that our formulation results in problem structure well-suited to incremental solvers, while our system architecture further enhances performance, achieving a 5x speed-up over existing methods.
Bias-Eliminated PnP for Stereo Visual Odometry: Provably Consistent and Large-Scale Localization
Apr 24, 2025



In this paper, we first present a bias-eliminated weighted (Bias-Eli-W) perspective-n-point (PnP) estimator for stereo visual odometry (VO) with provable consistency. Specifically, leveraging statistical theory, we develop an asymptotically unbiased and $\sqrt {n}$-consistent PnP estimator that accounts for varying 3D triangulation uncertainties, ensuring that the relative pose estimate converges to the ground truth as the number of features increases. Next, on the stereo VO pipeline side, we propose a framework that continuously triangulates contemporary features for tracking new frames, effectively decoupling temporal dependencies between pose and 3D point errors. We integrate the Bias-Eli-W PnP estimator into the proposed stereo VO pipeline, creating a synergistic effect that enhances the suppression of pose estimation errors. We validate the performance of our method on the KITTI and Oxford RobotCar datasets. Experimental results demonstrate that our method: 1) achieves significant improvements in both relative pose error and absolute trajectory error in large-scale environments; 2) provides reliable localization under erratic and unpredictable robot motions. The successful implementation of the Bias-Eli-W PnP in stereo VO indicates the importance of information screening in robotic estimation tasks with high-uncertainty measurements, shedding light on diverse applications where PnP is a key ingredient.
Training Trajectory Predictors Without Ground-Truth Data
Feb 13, 2025This paper presents a framework capable of accurately and smoothly estimating position, heading, and velocity. Using this high-quality input, we propose a system based on Trajectron++, able to consistently generate precise trajectory predictions. Unlike conventional models that require ground-truth data for training, our approach eliminates this dependency. Our analysis demonstrates that poor quality input leads to noisy and unreliable predictions, which can be detrimental to navigation modules. We evaluate both input data quality and model output to illustrate the impact of input noise. Furthermore, we show that our estimation system enables effective training of trajectory prediction models even with limited data, producing robust predictions across different environments. Accurate estimations are crucial for deploying trajectory prediction models in real-world scenarios, and our system ensures meaningful and reliable results across various application contexts.
DynoSAM: Open-Source Smoothing and Mapping Framework for Dynamic SLAM
Jan 21, 2025Traditional Visual Simultaneous Localization and Mapping (vSLAM) systems focus solely on static scene structures, overlooking dynamic elements in the environment. Although effective for accurate visual odometry in complex scenarios, these methods discard crucial information about moving objects. By incorporating this information into a Dynamic SLAM framework, the motion of dynamic entities can be estimated, enhancing navigation whilst ensuring accurate localization. However, the fundamental formulation of Dynamic SLAM remains an open challenge, with no consensus on the optimal approach for accurate motion estimation within a SLAM pipeline. Therefore, we developed DynoSAM, an open-source framework for Dynamic SLAM that enables the efficient implementation, testing, and comparison of various Dynamic SLAM optimization formulations. DynoSAM integrates static and dynamic measurements into a unified optimization problem solved using factor graphs, simultaneously estimating camera poses, static scene, object motion or poses, and object structures. We evaluate DynoSAM across diverse simulated and real-world datasets, achieving state-of-the-art motion estimation in indoor and outdoor environments, with substantial improvements over existing systems. Additionally, we demonstrate DynoSAM utility in downstream applications, including 3D reconstruction of dynamic scenes and trajectory prediction, thereby showcasing potential for advancing dynamic object-aware SLAM systems. DynoSAM is open-sourced at https://github.com/ACFR-RPG/DynOSAM.
TB-HSU: Hierarchical 3D Scene Understanding with Contextual Affordances
Dec 07, 2024The concept of function and affordance is a critical aspect of 3D scene understanding and supports task-oriented objectives. In this work, we develop a model that learns to structure and vary functional affordance across a 3D hierarchical scene graph representing the spatial organization of a scene. The varying functional affordance is designed to integrate with the varying spatial context of the graph. More specifically, we develop an algorithm that learns to construct a 3D hierarchical scene graph (3DHSG) that captures the spatial organization of the scene. Starting from segmented object point clouds and object semantic labels, we develop a 3DHSG with a top node that identifies the room label, child nodes that define local spatial regions inside the room with region-specific affordances, and grand-child nodes indicating object locations and object-specific affordances. To support this work, we create a custom 3DHSG dataset that provides ground truth data for local spatial regions with region-specific affordances and also object-specific affordances for each object. We employ a transformer-based model to learn the 3DHSG. We use a multi-task learning framework that learns both room classification and learns to define spatial regions within the room with region-specific affordances. Our work improves on the performance of state-of-the-art baseline models and shows one approach for applying transformer models to 3D scene understanding and the generation of 3DHSGs that capture the spatial organization of a room. The code and dataset are publicly available.
Surf-NeRF: Surface Regularised Neural Radiance Fields
Nov 27, 2024Neural Radiance Fields (NeRFs) provide a high fidelity, continuous scene representation that can realistically represent complex behaviour of light. Despite recent works like Ref-NeRF improving geometry through physics-inspired models, the ability for a NeRF to overcome shape-radiance ambiguity and converge to a representation consistent with real geometry remains limited. We demonstrate how curriculum learning of a surface light field model helps a NeRF converge towards a more geometrically accurate scene representation. We introduce four additional regularisation terms to impose geometric smoothness, consistency of normals and a separation of Lambertian and specular appearance at geometry in the scene, conforming to physical models. Our approach yields improvements of 14.4% to normals on positionally encoded NeRFs and 9.2% on grid-based models compared to current reflection-based NeRF variants. This includes a separated view-dependent appearance, conditioning a NeRF to have a geometric representation consistent with the captured scene. We demonstrate compatibility of our method with existing NeRF variants, as a key step in enabling radiance-based representations for geometry critical applications.
DynORecon: Dynamic Object Reconstruction for Navigation
Sep 30, 2024This paper presents DynORecon, a Dynamic Object Reconstruction system that leverages the information provided by Dynamic SLAM to simultaneously generate a volumetric map of observed moving entities while estimating free space to support navigation. By capitalising on the motion estimations provided by Dynamic SLAM, DynORecon continuously refines the representation of dynamic objects to eliminate residual artefacts from past observations and incrementally reconstructs each object, seamlessly integrating new observations to capture previously unseen structures. Our system is highly efficient (~20 FPS) and produces accurate (~10 cm) reconstructions of dynamic objects using simulated and real-world outdoor datasets.
The Importance of Coordinate Frames in Dynamic SLAM
Dec 07, 2023Most Simultaneous localisation and mapping (SLAM) systems have traditionally assumed a static world, which does not align with real-world scenarios. To enable robots to safely navigate and plan in dynamic environments, it is essential to employ representations capable of handling moving objects. Dynamic SLAM is an emerging field in SLAM research as it improves the overall system accuracy while providing additional estimation of object motions. State-of-the-art literature informs two main formulations for Dynamic SLAM, representing dynamic object points in either the world or object coordinate frame. While expressing object points in a local reference frame may seem intuitive, it may not necessarily lead to the most accurate and robust solutions. This paper conducts and presents a thorough analysis of various Dynamic SLAM formulations, identifying the best approach to address the problem. To this end, we introduce a front-end agnostic framework using GTSAM that can be used to evaluate various Dynamic SLAM formulations.
Robust Ego and Object 6-DoF Motion Estimation and Tracking
Jul 28, 2020
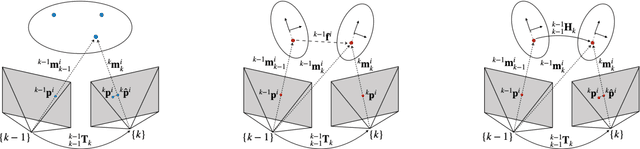
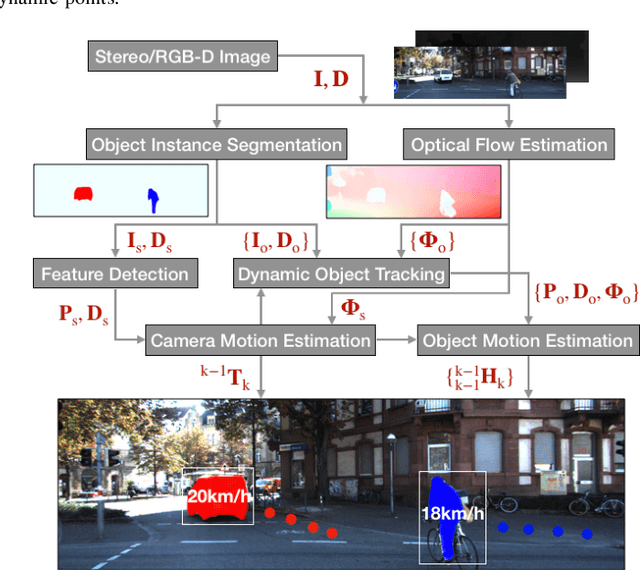

The problem of tracking self-motion as well as motion of objects in the scene using information from a camera is known as multi-body visual odometry and is a challenging task. This paper proposes a robust solution to achieve accurate estimation and consistent track-ability for dynamic multi-body visual odometry. A compact and effective framework is proposed leveraging recent advances in semantic instance-level segmentation and accurate optical flow estimation. A novel formulation, jointly optimizing SE(3) motion and optical flow is introduced that improves the quality of the tracked points and the motion estimation accuracy. The proposed approach is evaluated on the virtual KITTI Dataset and tested on the real KITTI Dataset, demonstrating its applicability to autonomous driving applications. For the benefit of the community, we make the source code public.