 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 3D Reconstruction Benchmark for Asset Inspection
Mar 18, 2026Asset management requires accurate 3D models to inform the maintenance, repair, and assessment of buildings, maritime vessels, and other key structures as they age. These downstream applications rely on high-fidelity models produced from aerial surveys in close proximity to the asset, enabling operators to locate and characterise deterioration or damage and plan repairs. Captured images typically have high overlap between adjacent camera poses, sufficient detail at millimetre scale, and challenging visual appearances such as reflections and transparency. However, existing 3D reconstruction datasets lack examples of these conditions, making it difficult to benchmark methods for this task. We present a new dataset with ground truth depth maps, camera poses, and mesh models of three synthetic scenes with simulated inspection trajectories and varying levels of surface condition on non-Lambertian scene content. We evaluate state-of-the-art reconstruction methods on this dataset. Our results demonstrate that current approaches struggle significantly with the dense capture trajectories and complex surface conditions inherent to this domain, exposing a critical scalability gap and pointing toward new research directions for deployable 3D reconstruction in asset inspection. Project page: https://roboticimaging.org/Projects/asset-inspection-dataset/
dLITE: Differentiable Lighting-Informed Trajectory Evaluation for On-Orbit Inspection
Dec 17, 2025Visual inspection of space-borne assets is of increasing interest to spacecraft operators looking to plan maintenance, characterise damage, and extend the life of high-value satellites in orbit. The environment of Low Earth Orbit (LEO) presents unique challenges when planning inspection operations that maximise visibility, information, and data quality. Specular reflection of sunlight from spacecraft bodies, self-shadowing, and dynamic lighting in LEO significantly impact the quality of data captured throughout an orbit. This is exacerbated by the relative motion between spacecraft, which introduces variable imaging distances and attitudes during inspection. Planning inspection trajectories with the aide of simulation is a common approach. However, the ability to design and optimise an inspection trajectory specifically to improve the resulting image quality in proximity operations remains largely unexplored. In this work, we present $\partial$LITE, an end-to-end differentiable simulation pipeline for on-orbit inspection operations. We leverage state-of-the-art differentiable rendering tools and a custom orbit propagator to enable end-to-end optimisation of orbital parameters based on visual sensor data. $\partial$LITE enables us to automatically design non-obvious trajectories, vastly improving the quality and usefulness of attained data. To our knowledge, our differentiable inspection-planning pipeline is the first of its kind and provides new insights into modern computational approaches to spacecraft mission planning. Project page: https://appearance-aware.github.io/dlite/
Light Field Based 6DoF Tracking of Previously Unobserved Objects
Dec 15, 2025Object tracking is an important step in robotics and reautonomous driving pipelines, which has to generalize to previously unseen and complex objects. Existing high-performing methods often rely on pre-captured object views to build explicit reference models, which restricts them to a fixed set of known objects. However, such reference models can struggle with visually complex appearance, reducing the quality of tracking. In this work, we introduce an object tracking method based on light field images that does not depend on a pre-trained model, while being robust to complex visual behavior, such as reflections. We extract semantic and geometric features from light field inputs using vision foundation models and convert them into view-dependent Gaussian splats. These splats serve as a unified object representation, supporting differentiable rendering and pose optimization. We further introduce a light field object tracking dataset containing challenging reflective objects with precise ground truth poses. Experiments demonstrate that our method is competitive with state-of-the-art model-based trackers in these difficult cases, paving the way toward universal object tracking in robotic systems. Code/data available at https://github.com/nagonch/LiFT-6DoF.
Learning Underwater Active Perception in Simulation
Apr 23, 2025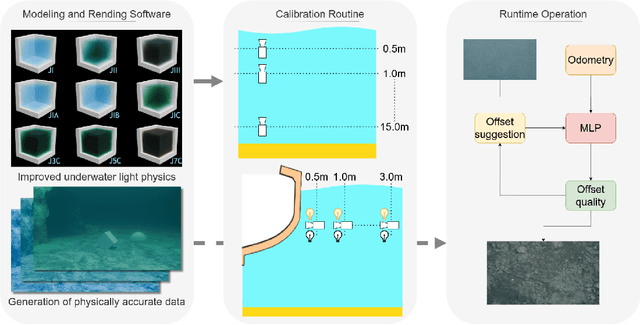

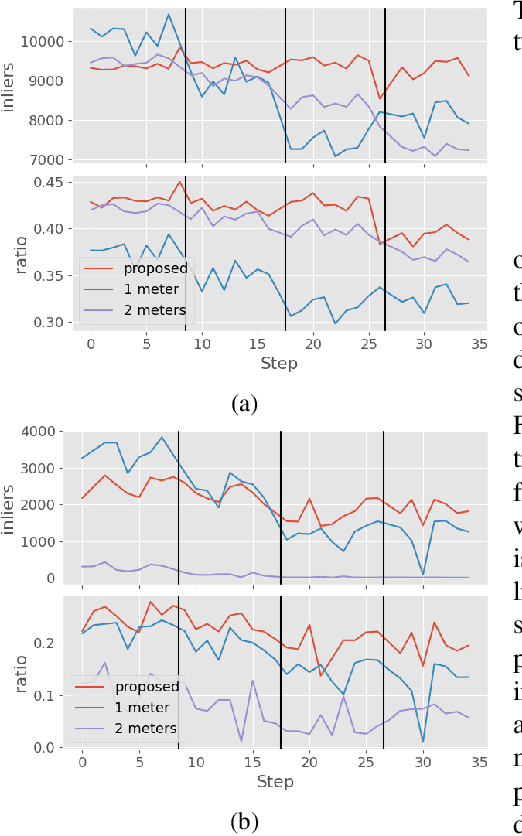
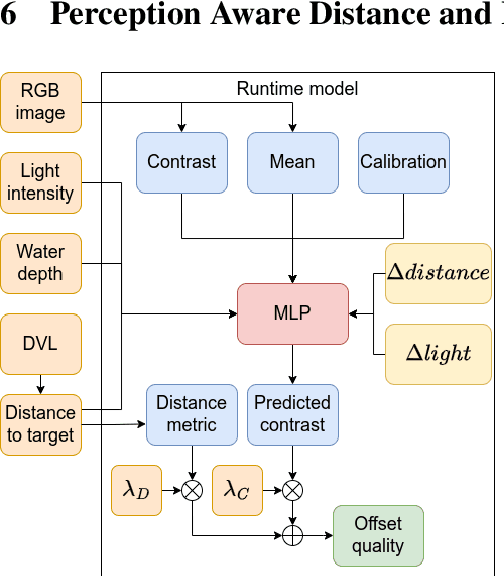
When employing underwater vehicles for the autonomous inspection of assets, it is crucial to consider and assess the water conditions. Indeed, they have a significant impact on the visibility, which also affects robotic operations. Turbidity can jeopardise the whole mission as it may prevent correct visual documentation of the inspected structures. Previous works have introduced methods to adapt to turbidity and backscattering, however, they also include manoeuvring and setup constraints. We propose a simple yet efficient approach to enable high-quality image acquisition of assets in a broad range of water conditions. This active perception framework includes a multi-layer perceptron (MLP) trained to predict image quality given a distance to a target and artificial light intensity. We generated a large synthetic dataset including ten water types with different levels of turbidity and backscattering. For this, we modified the modelling software Blender to better account for the underwater light propagation properties. We validated the approach in simulation and showed significant improvements in visual coverage and quality of imagery compared to traditional approaches. The project code is available on our project page at https://roboticimaging.org/Projects/ActiveUW/.
Surf-NeRF: Surface Regularised Neural Radiance Fields
Nov 27, 2024Neural Radiance Fields (NeRFs) provide a high fidelity, continuous scene representation that can realistically represent complex behaviour of light. Despite recent works like Ref-NeRF improving geometry through physics-inspired models, the ability for a NeRF to overcome shape-radiance ambiguity and converge to a representation consistent with real geometry remains limited. We demonstrate how curriculum learning of a surface light field model helps a NeRF converge towards a more geometrically accurate scene representation. We introduce four additional regularisation terms to impose geometric smoothness, consistency of normals and a separation of Lambertian and specular appearance at geometry in the scene, conforming to physical models. Our approach yields improvements of 14.4% to normals on positionally encoded NeRFs and 9.2% on grid-based models compared to current reflection-based NeRF variants. This includes a separated view-dependent appearance, conditioning a NeRF to have a geometric representation consistent with the captured scene. We demonstrate compatibility of our method with existing NeRF variants, as a key step in enabling radiance-based representations for geometry critical applications.
Segment Anything in Light Fields for Real-Time Applications via Constrained Prompting
Nov 21, 2024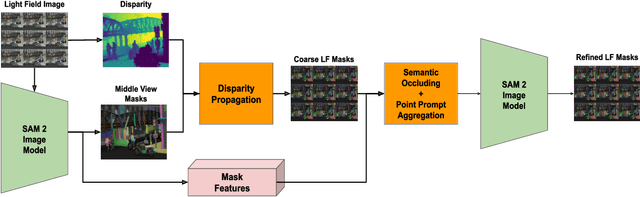

Segmented light field images can serve as a powerful representation in many of computer vision tasks exploiting geometry and appearance of objects, such as object pose tracking. In the light field domain, segmentation presents an additional objective of recognizing the same segment through all the views. Segment Anything Model 2 (SAM 2) allows producing semantically meaningful segments for monocular images and videos. However, using SAM 2 directly on light fields is highly ineffective due to unexploited constraints. In this work, we present a novel light field segmentation method that adapts SAM 2 to the light field domain without retraining or modifying the model. By utilizing the light field domain constraints, the method produces high quality and view-consistent light field masks, outperforming the SAM 2 video tracking baseline and working 7 times faster, with a real-time speed. We achieve this by exploiting the epipolar geometry cues to propagate the masks between the views, probing the SAM 2 latent space to estimate their occlusion, and further prompting SAM 2 for their refinement.
LBurst: Learning-Based Robotic Burst Feature Extraction for 3D Reconstruction in Low Light
Oct 31, 2024
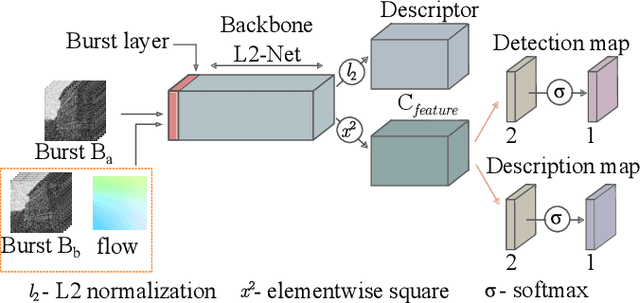
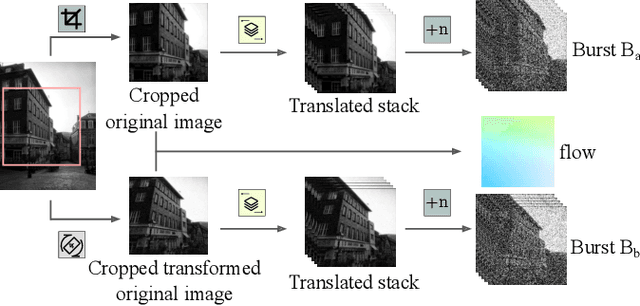

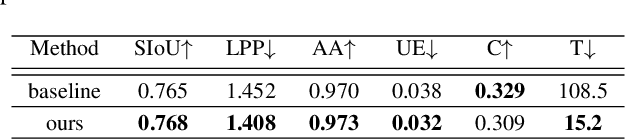
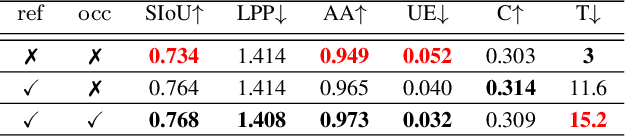
Drones have revolutionized the fields of aerial imaging, mapping, and disaster recovery. However, the deployment of drones in low-light conditions is constrained by the image quality produced by their on-board cameras. In this paper, we present a learning architecture for improving 3D reconstructions in low-light conditions by finding features in a burst. Our approach enhances visual reconstruction by detecting and describing high quality true features and less spurious features in low signal-to-noise ratio images. We demonstrate that our method is capable of handling challenging scenes in millilux illumination, making it a significant step towards drones operating at night and in extremely low-light applications such as underground mining and search and rescue operations.
TaCOS: Task-Specific Camera Optimization with Simulation
Apr 18, 2024The performance of robots in their applications heavily depends on the quality of sensory input. However, designing sensor payloads and their parameters for specific robotic tasks is an expensive process that requires well-established sensor knowledge and extensive experiments with physical hardware. With cameras playing a pivotal role in robotic perception, we introduce a novel end-to-end optimization approach for co-designing a camera with specific robotic tasks by combining derivative-free and gradient-based optimizers. The proposed method leverages recent computer graphics techniques and physical camera characteristics to prototype the camera in software, simulate operational environments and tasks for robots, and optimize the camera design based on the desired tasks in a cost-effective way. We validate the accuracy of our camera simulation by comparing it with physical cameras, and demonstrate the design of cameras with stronger performance than common off-the-shelf alternatives. Our approach supports the optimization of both continuous and discrete camera parameters, manufacturing constraints, and can be generalized to a broad range of camera design scenarios including multiple cameras and unconventional cameras. This work advances the fully automated design of cameras for specific robotics tasks.
Adapting CNNs for Fisheye Cameras without Retraining
Apr 12, 2024

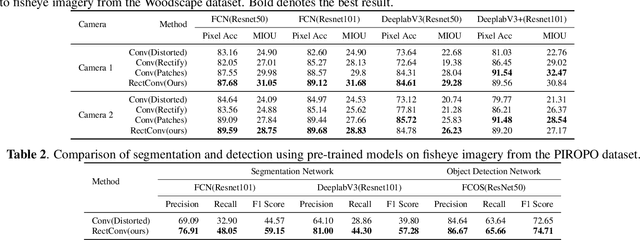
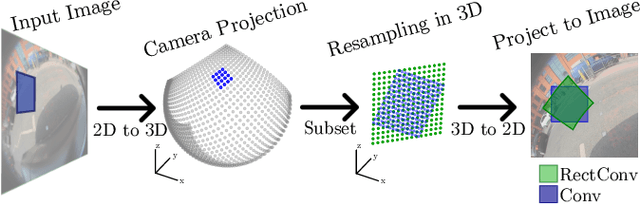
The majority of image processing approaches assume images are in or can be rectified to a perspective projection. However, in many applications it is beneficial to use non conventional cameras, such as fisheye cameras, that have a larger field of view (FOV). The issue arises that these large-FOV images can't be rectified to a perspective projection without significant cropping of the original image. To address this issue we propose Rectified Convolutions (RectConv); a new approach for adapting pre-trained convolutional networks to operate with new non-perspective images, without any retraining. Replacing the convolutional layers of the network with RectConv layers allows the network to see both rectified patches and the entire FOV. We demonstrate RectConv adapting multiple pre-trained networks to perform segmentation and detection on fisheye imagery from two publicly available datasets. Our approach requires no additional data or training, and operates directly on the native image as captured from the camera. We believe this work is a step toward adapting the vast resources available for perspective images to operate across a broad range of camera geometries.
The Need for Inherently Privacy-Preserving Vision in Trustworthy Autonomous Systems
Mar 29, 2023



Vision is a popular and effective sensor for robotics from which we can derive rich information about the environment: the geometry and semantics of the scene, as well as the age, gender, identity, activity and even emotional state of humans within that scene. This raises important questions about the reach, lifespan, and potential misuse of this information. This paper is a call to action to consider privacy in the context of robotic vision. We propose a specific form privacy preservation in which no images are captured or could be reconstructed by an attacker even with full remote access. We present a set of principles by which such systems can be designed, and through a case study in localisation demonstrate in simulation a specific implementation that delivers an important robotic capability in an inherently privacy-preserving manner. This is a first step, and we hope to inspire future works that expand the range of applications open to sighted robotic systems.