 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeploy DINO with Many-to-Many Association
Apr 26, 2026Motivated by the limited generalization of supervised image matching models to unseen image domains, we explore the zero-shot deployment of DINO features for this task. The generalist visual representation extracted from DINO has inherent ambiguity when used to match feature points among semantically similar instances, prompting us to adopt a many-to-many (m-to-m) matching paradigm. However, the existing robust mechanism under m-to-m data association is computationally heavy, which requires finding a maximum-cardinality matching in the inlier association graph for each parameter evaluation. To address this inefficiency, we introduce a novel likelihood perspective, which interprets the existing method as a zeroth-order approximation of otherwise intractable likelihood calculation,and inspires us to propose a faster and finer-grained robust mechanism, termed as Harmonic Consensus Maximization (HCM). Take camera pose estimation as an exemplifying downstream task, we demonstrate that general-purpose visual features, used out of the box without any adaptation, can compete with specialized matching models on out-of-distribution datasets when mated with m-to-m association and the HCM mechanism.
Hierarchical Multi-Modal Planning for Fixed-Altitude Sparse Target Search and Sampling
Mar 09, 2026Efficient monitoring of sparse benthic phenomena, such as coral colonies, presents a great challenge for Autonomous Underwater Vehicles. Traditional exhaustive coverage strategies are energy-inefficient, while recent adaptive sampling approaches rely on costly vertical maneuvers. To address these limitations, we propose HIMoS (Hierarchical Informative Multi-Modal Search), a fixed-altitude framework for sparse coral search-and-sample missions. The system integrates a heterogeneous sensor suite within a two-layer planning architecture. At the strategic level, a Global Planner optimizes topological routes to maximize potential discovery. At the tactical level, a receding-horizon Local Planner leverages differentiable belief propagation to generate kinematically feasible trajectories that balance acoustic substrate exploration, visual coral search, and close-range sampling. Validated in high-fidelity simulations derived from real-world coral reef benthic surveys, our approach demonstrates superior mission efficiency compared to state-of-the-art baselines.
SparseST: Exploiting Data Sparsity in Spatiotemporal Modeling and Prediction
Nov 18, 2025Spatiotemporal data mining (STDM) has a wide range of applications in various complex physical systems (CPS), i.e., transportation, manufacturing, healthcare, etc. Among all the proposed methods, the Convolutional Long Short-Term Memory (ConvLSTM) has proved to be generalizable and extendable in different applications and has multiple variants achieving state-of-the-art performance in various STDM applications. However, ConvLSTM and its variants are computationally expensive, which makes them inapplicable in edge devices with limited computational resources. With the emerging need for edge computing in CPS, efficient AI is essential to reduce the computational cost while preserving the model performance. Common methods of efficient AI are developed to reduce redundancy in model capacity (i.e., model pruning, compression, etc.). However, spatiotemporal data mining naturally requires extensive model capacity, as the embedded dependencies in spatiotemporal data are complex and hard to capture, which limits the model redundancy. Instead, there is a fairly high level of data and feature redundancy that introduces an unnecessary computational burden, which has been largely overlooked in existing research. Therefore, we developed a novel framework SparseST, that pioneered in exploiting data sparsity to develop an efficient spatiotemporal model. In addition, we explore and approximate the Pareto front between model performance and computational efficiency by designing a multi-objective composite loss function, which provides a practical guide for practitioners to adjust the model according to computational resource constraints and the performance requirements of downstream tasks.
TokBench: Evaluating Your Visual Tokenizer before Visual Generation
May 26, 2025In this work, we reveal the limitations of visual tokenizers and VAEs in preserving fine-grained features, and propose a benchmark to evaluate reconstruction performance for two challenging visual contents: text and face. Visual tokenizers and VAEs have significantly advanced visual generation and multimodal modeling by providing more efficient compressed or quantized image representations. However, while helping production models reduce computational burdens, the information loss from image compression fundamentally limits the upper bound of visual generation quality. To evaluate this upper bound, we focus on assessing reconstructed text and facial features since they typically: 1) exist at smaller scales, 2) contain dense and rich textures, 3) are prone to collapse, and 4) are highly sensitive to human vision. We first collect and curate a diverse set of clear text and face images from existing datasets. Unlike approaches using VLM models, we employ established OCR and face recognition models for evaluation, ensuring accuracy while maintaining an exceptionally lightweight assessment process <span style="font-weight: bold; color: rgb(214, 21, 21);">requiring just 2GB memory and 4 minutes</span> to complete. Using our benchmark, we analyze text and face reconstruction quality across various scales for different image tokenizers and VAEs. Our results show modern visual tokenizers still struggle to preserve fine-grained features, especially at smaller scales. We further extend this evaluation framework to video, conducting comprehensive analysis of video tokenizers. Additionally, we demonstrate that traditional metrics fail to accurately reflect reconstruction performance for faces and text, while our proposed metrics serve as an effective complement.
AquaticVision: Benchmarking Visual SLAM in Underwater Environment with Events and Frames
May 06, 2025



Many underwater applications, such as offshore asset inspections, rely on visual inspection and detailed 3D reconstruction. Recent advancements in underwater visual SLAM systems for aquatic environments have garnered significant attention in marine robotics research. However, existing underwater visual SLAM datasets often lack groundtruth trajectory data, making it difficult to objectively compare the performance of different SLAM algorithms based solely on qualitative results or COLMAP reconstruction. In this paper, we present a novel underwater dataset that includes ground truth trajectory data obtained using a motion capture system. Additionally, for the first time, we release visual data that includes both events and frames for benchmarking underwater visual positioning. By providing event camera data, we aim to facilitate the development of more robust and advanced underwater visual SLAM algorithms. The use of event cameras can help mitigate challenges posed by extremely low light or hazy underwater conditions. The webpage of our dataset is https://sites.google.com/view/aquaticvision-lias.
Bias-Eliminated PnP for Stereo Visual Odometry: Provably Consistent and Large-Scale Localization
Apr 24, 2025



In this paper, we first present a bias-eliminated weighted (Bias-Eli-W) perspective-n-point (PnP) estimator for stereo visual odometry (VO) with provable consistency. Specifically, leveraging statistical theory, we develop an asymptotically unbiased and $\sqrt {n}$-consistent PnP estimator that accounts for varying 3D triangulation uncertainties, ensuring that the relative pose estimate converges to the ground truth as the number of features increases. Next, on the stereo VO pipeline side, we propose a framework that continuously triangulates contemporary features for tracking new frames, effectively decoupling temporal dependencies between pose and 3D point errors. We integrate the Bias-Eli-W PnP estimator into the proposed stereo VO pipeline, creating a synergistic effect that enhances the suppression of pose estimation errors. We validate the performance of our method on the KITTI and Oxford RobotCar datasets. Experimental results demonstrate that our method: 1) achieves significant improvements in both relative pose error and absolute trajectory error in large-scale environments; 2) provides reliable localization under erratic and unpredictable robot motions. The successful implementation of the Bias-Eli-W PnP in stereo VO indicates the importance of information screening in robotic estimation tasks with high-uncertainty measurements, shedding light on diverse applications where PnP is a key ingredient.
SCORE: Saturated Consensus Relocalization in Semantic Line Maps
Mar 05, 2025



This is the arxiv version for our paper submitted to IEEE/RSJ IROS 2025. We propose a scene-agnostic and light-weight visual relocalization framework that leverages semantically labeled 3D lines as a compact map representation. In our framework, the robot localizes itself by capturing a single image, extracting 2D lines, associating them with semantically similar 3D lines in the map, and solving a robust perspective-n-line problem. To address the extremely high outlier ratios~(exceeding 99.5\%) caused by one-to-many ambiguities in semantic matching, we introduce the Saturated Consensus Maximization~(Sat-CM) formulation, which enables accurate pose estimation when the classic Consensus Maximization framework fails. We further propose a fast global solver to the formulated Sat-CM problems, leveraging rigorous interval analysis results to ensure both accuracy and computational efficiency. Additionally, we develop a pipeline for constructing semantic 3D line maps using posed depth images. To validate the effectiveness of our framework, which integrates our innovations in robust estimation and practical engineering insights, we conduct extensive experiments on the ScanNet++ dataset.
UniTok: A Unified Tokenizer for Visual Generation and Understanding
Feb 27, 2025



The representation disparity between visual generation and understanding imposes a critical gap in integrating these capabilities into a single framework. To bridge this gap, we introduce UniTok, a discrete visual tokenizer that encodes fine-grained details for generation while also capturing high-level semantics for understanding. Despite recent studies have shown that these objectives could induce loss conflicts in training, we reveal that the underlying bottleneck stems from limited representational capacity of discrete tokens. We address this by introducing multi-codebook quantization, which divides vector quantization with several independent sub-codebooks to expand the latent feature space, while avoiding training instability caused by overlarge codebooks. Our method significantly raises the upper limit of unified discrete tokenizers to match or even surpass domain-specific continuous tokenizers. For instance, UniTok achieves a remarkable rFID of 0.38 (versus 0.87 for SD-VAE) and a zero-shot accuracy of 78.6% (versus 76.2% for CLIP) on ImageNet. Our code is available at https://github.com/FoundationVision/UniTok.
Liquid: Language Models are Scalable Multi-modal Generators
Dec 05, 2024
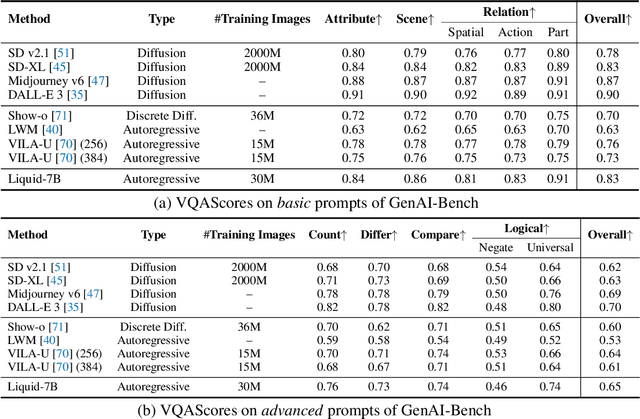

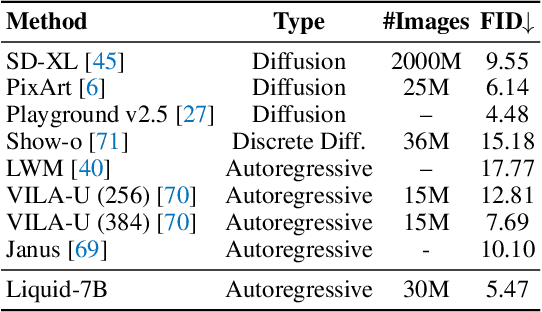
We present Liquid, an auto-regressive generation paradigm that seamlessly integrates visual comprehension and generation by tokenizing images into discrete codes and learning these code embeddings alongside text tokens within a shared feature space for both vision and language. Unlike previous multimodal large language model (MLLM), Liquid achieves this integration using a single large language model (LLM), eliminating the need for external pretrained visual embeddings such as CLIP. For the first time, Liquid uncovers a scaling law that performance drop unavoidably brought by the unified training of visual and language tasks diminishes as the model size increases. Furthermore, the unified token space enables visual generation and comprehension tasks to mutually enhance each other, effectively removing the typical interference seen in earlier models. We show that existing LLMs can serve as strong foundations for Liquid, saving 100x in training costs while outperforming Chameleon in multimodal capabilities and maintaining language performance comparable to mainstream LLMs like LLAMA2. Liquid also outperforms models like SD v2.1 and SD-XL (FID of 5.47 on MJHQ-30K), excelling in both vision-language and text-only tasks. This work demonstrates that LLMs such as LLAMA3.2 and GEMMA2 are powerful multimodal generators, offering a scalable solution for enhancing both vision-language understanding and generation. The code and models will be released.
Online Poisoning Attack Against Reinforcement Learning under Black-box Environments
Dec 01, 2024
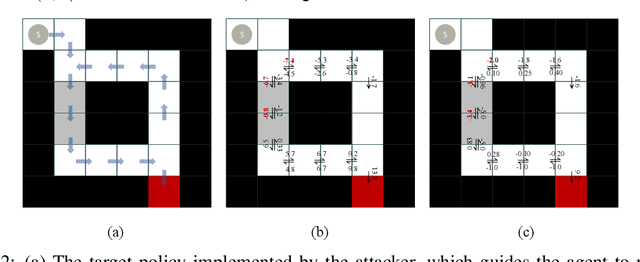
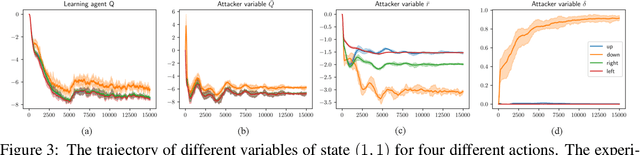
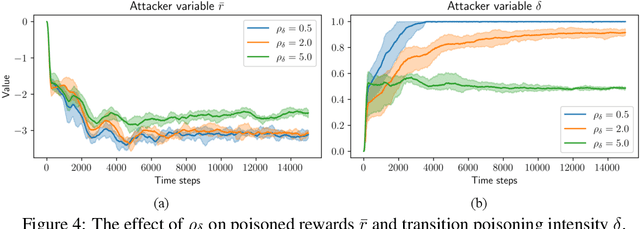
This paper proposes an online environment poisoning algorithm tailored for reinforcement learning agents operating in a black-box setting, where an adversary deliberately manipulates training data to lead the agent toward a mischievous policy. In contrast to prior studies that primarily investigate white-box settings, we focus on a scenario characterized by \textit{unknown} environment dynamics to the attacker and a \textit{flexible} reinforcement learning algorithm employed by the targeted agent. We first propose an attack scheme that is capable of poisoning the reward functions and state transitions. The poisoning task is formalized as a constrained optimization problem, following the framework of \cite{ma2019policy}. Given the transition probabilities are unknown to the attacker in a black-box environment, we apply a stochastic gradient descent algorithm, where the exact gradients are approximated using sample-based estimates. A penalty-based method along with a bilevel reformulation is then employed to transform the problem into an unconstrained counterpart and to circumvent the double-sampling issue. The algorithm's effectiveness is validated through a maze environment.