 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVICTOR: Dataset Copyright Auditing in Video Recognition Systems
Dec 16, 2025Video recognition systems are increasingly being deployed in daily life, such as content recommendation and security monitoring. To enhance video recognition development, many institutions have released high-quality public datasets with open-source licenses for training advanced models. At the same time, these datasets are also susceptible to misuse and infringement. Dataset copyright auditing is an effective solution to identify such unauthorized use. However, existing dataset copyright solutions primarily focus on the image domain; the complex nature of video data leaves dataset copyright auditing in the video domain unexplored. Specifically, video data introduces an additional temporal dimension, which poses significant challenges to the effectiveness and stealthiness of existing methods. In this paper, we propose VICTOR, the first dataset copyright auditing approach for video recognition systems. We develop a general and stealthy sample modification strategy that enhances the output discrepancy of the target model. By modifying only a small proportion of samples (e.g., 1%), VICTOR amplifies the impact of published modified samples on the prediction behavior of the target models. Then, the difference in the model's behavior for published modified and unpublished original samples can serve as a key basis for dataset auditing. Extensive experiments on multiple models and datasets highlight the superiority of VICTOR. Finally, we show that VICTOR is robust in the presence of several perturbation mechanisms to the training videos or the target models.
GradEscape: A Gradient-Based Evader Against AI-Generated Text Detectors
Jun 09, 2025In this paper, we introduce GradEscape, the first gradient-based evader designed to attack AI-generated text (AIGT) detectors. GradEscape overcomes the undifferentiable computation problem, caused by the discrete nature of text, by introducing a novel approach to construct weighted embeddings for the detector input. It then updates the evader model parameters using feedback from victim detectors, achieving high attack success with minimal text modification. To address the issue of tokenizer mismatch between the evader and the detector, we introduce a warm-started evader method, enabling GradEscape to adapt to detectors across any language model architecture. Moreover, we employ novel tokenizer inference and model extraction techniques, facilitating effective evasion even in query-only access. We evaluate GradEscape on four datasets and three widely-used language models, benchmarking it against four state-of-the-art AIGT evaders. Experimental results demonstrate that GradEscape outperforms existing evaders in various scenarios, including with an 11B paraphrase model, while utilizing only 139M parameters. We have successfully applied GradEscape to two real-world commercial AIGT detectors. Our analysis reveals that the primary vulnerability stems from disparity in text expression styles within the training data. We also propose a potential defense strategy to mitigate the threat of AIGT evaders. We open-source our GradEscape for developing more robust AIGT detectors.
ArtistAuditor: Auditing Artist Style Pirate in Text-to-Image Generation Models
Apr 17, 2025Text-to-image models based on diffusion processes, such as DALL-E, Stable Diffusion, and Midjourney, are capable of transforming texts into detailed images and have widespread applications in art and design. As such, amateur users can easily imitate professional-level paintings by collecting an artist's work and fine-tuning the model, leading to concerns about artworks' copyright infringement. To tackle these issues, previous studies either add visually imperceptible perturbation to the artwork to change its underlying styles (perturbation-based methods) or embed post-training detectable watermarks in the artwork (watermark-based methods). However, when the artwork or the model has been published online, i.e., modification to the original artwork or model retraining is not feasible, these strategies might not be viable. To this end, we propose a novel method for data-use auditing in the text-to-image generation model. The general idea of ArtistAuditor is to identify if a suspicious model has been finetuned using the artworks of specific artists by analyzing the features related to the style. Concretely, ArtistAuditor employs a style extractor to obtain the multi-granularity style representations and treats artworks as samplings of an artist's style. Then, ArtistAuditor queries a trained discriminator to gain the auditing decisions. The experimental results on six combinations of models and datasets show that ArtistAuditor can achieve high AUC values (> 0.937). By studying ArtistAuditor's transferability and core modules, we provide valuable insights into the practical implementation. Finally, we demonstrate the effectiveness of ArtistAuditor in real-world cases by an online platform Scenario. ArtistAuditor is open-sourced at https://github.com/Jozenn/ArtistAuditor.
SoK: Dataset Copyright Auditing in Machine Learning Systems
Oct 22, 2024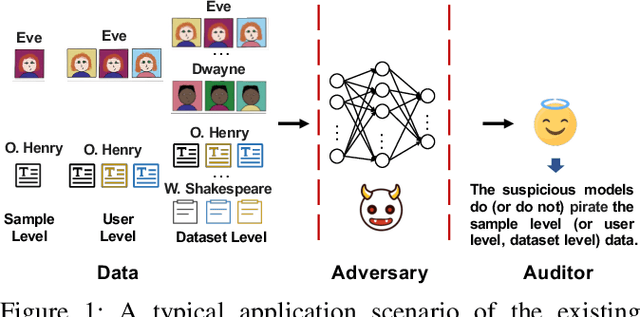
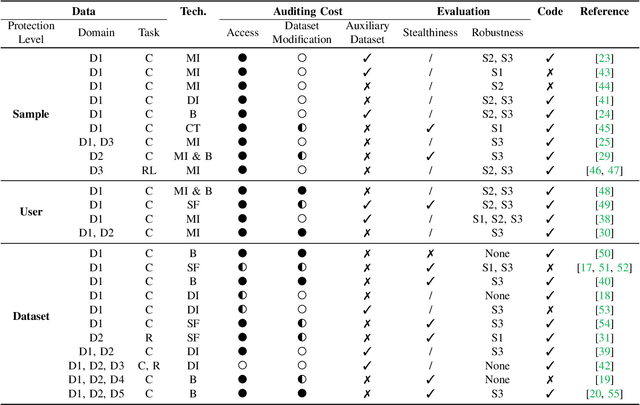
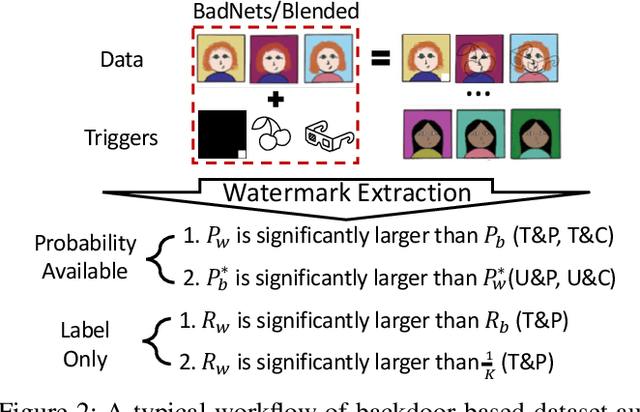

As the implementation of machine learning (ML) systems becomes more widespread, especially with the introduction of larger ML models, we perceive a spring demand for massive data. However, it inevitably causes infringement and misuse problems with the data, such as using unauthorized online artworks or face images to train ML models. To address this problem, many efforts have been made to audit the copyright of the model training dataset. However, existing solutions vary in auditing assumptions and capabilities, making it difficult to compare their strengths and weaknesses. In addition, robustness evaluations usually consider only part of the ML pipeline and hardly reflect the performance of algorithms in real-world ML applications. Thus, it is essential to take a practical deployment perspective on the current dataset copyright auditing tools, examining their effectiveness and limitations. Concretely, we categorize dataset copyright auditing research into two prominent strands: intrusive methods and non-intrusive methods, depending on whether they require modifications to the original dataset. Then, we break down the intrusive methods into different watermark injection options and examine the non-intrusive methods using various fingerprints. To summarize our results, we offer detailed reference tables, highlight key points, and pinpoint unresolved issues in the current literature. By combining the pipeline in ML systems and analyzing previous studies, we highlight several future directions to make auditing tools more suitable for real-world copyright protection requirements.
$S^2$NeRF: Privacy-preserving Training Framework for NeRF
Sep 03, 2024Neural Radiance Fields (NeRF) have revolutionized 3D computer vision and graphics, facilitating novel view synthesis and influencing sectors like extended reality and e-commerce. However, NeRF's dependence on extensive data collection, including sensitive scene image data, introduces significant privacy risks when users upload this data for model training. To address this concern, we first propose SplitNeRF, a training framework that incorporates split learning (SL) techniques to enable privacy-preserving collaborative model training between clients and servers without sharing local data. Despite its benefits, we identify vulnerabilities in SplitNeRF by developing two attack methods, Surrogate Model Attack and Scene-aided Surrogate Model Attack, which exploit the shared gradient data and a few leaked scene images to reconstruct private scene information. To counter these threats, we introduce $S^2$NeRF, secure SplitNeRF that integrates effective defense mechanisms. By introducing decaying noise related to the gradient norm into the shared gradient information, $S^2$NeRF preserves privacy while maintaining a high utility of the NeRF model. Our extensive evaluations across multiple datasets demonstrate the effectiveness of $S^2$NeRF against privacy breaches, confirming its viability for secure NeRF training in sensitive applications.
Parameters Inference for Nonlinear Wave Equations with Markovian Switching
Aug 12, 2024Traditional partial differential equations with constant coefficients often struggle to capture abrupt changes in real-world phenomena, leading to the development of variable coefficient PDEs and Markovian switching models. Recently, research has introduced the concept of PDEs with Markov switching models, established their well-posedness and presented numerical methods. However, there has been limited discussion on parameter estimation for the jump coefficients in these models. This paper addresses this gap by focusing on parameter inference for the wave equation with Markovian switching. We propose a Bayesian statistical framework using discrete sparse Bayesian learning to establish its convergence and a uniform error bound. Our method requires fewer assumptions and enables independent parameter inference for each segment by allowing different underlying structures for the parameter estimation problem within each segmented time interval. The effectiveness of our approach is demonstrated through three numerical cases, which involve noisy spatiotemporal data from different wave equations with Markovian switching. The results show strong performance in parameter estimation for variable coefficient PDEs.
Machine Learning for Complex Systems with Abnormal Pattern by Exception Maximization Outlier Detection Method
Jul 05, 2024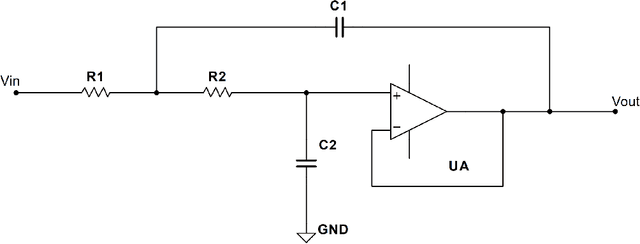
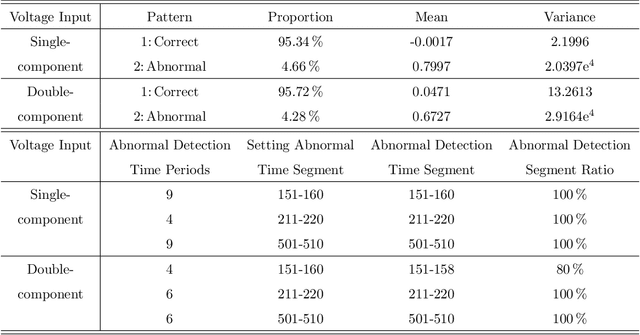
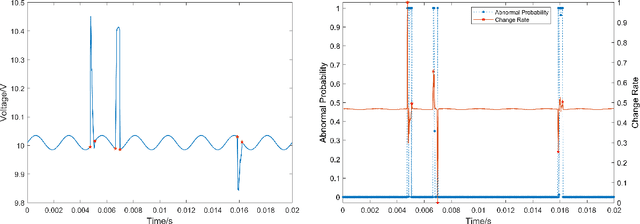

This paper proposes a novel fast online methodology for outlier detection called the exception maximization outlier detection method(EMODM), which employs probabilistic models and statistical algorithms to detect abnormal patterns from the outputs of complex systems. The EMODM is based on a two-state Gaussian mixture model and demonstrates strong performance in probability anomaly detection working on real-time raw data rather than using special prior distribution information. We confirm this using the synthetic data from two numerical cases. For the real-world data, we have detected the short circuit pattern of the circuit system using EMODM by the current and voltage output of a three-phase inverter. The EMODM also found an abnormal period due to COVID-19 in the insured unemployment data of 53 regions in the United States from 2000 to 2024. The application of EMODM to these two real-life datasets demonstrated the effectiveness and accuracy of our algorithm.
DPAdapter: Improving Differentially Private Deep Learning through Noise Tolerance Pre-training
Mar 05, 2024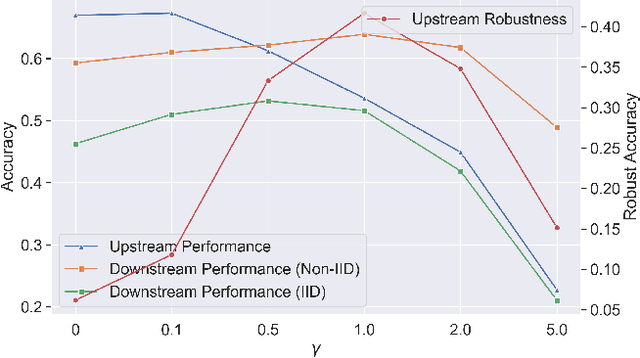
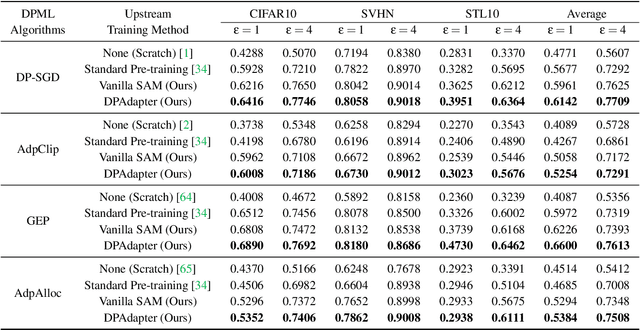
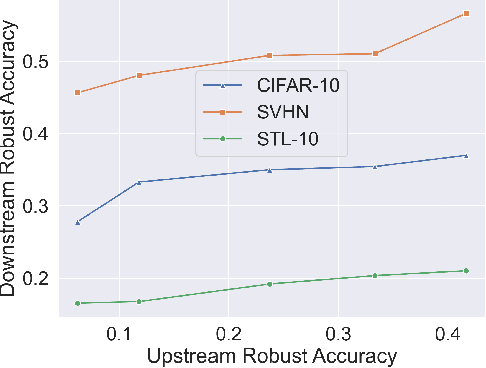
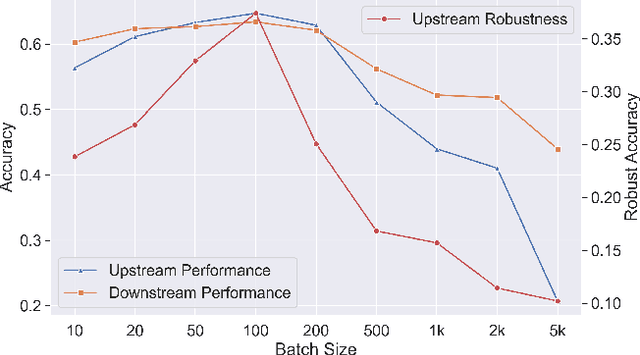
Recent developments have underscored the critical role of \textit{differential privacy} (DP) in safeguarding individual data for training machine learning models. However, integrating DP oftentimes incurs significant model performance degradation due to the perturbation introduced into the training process, presenting a formidable challenge in the {differentially private machine learning} (DPML) field. To this end, several mitigative efforts have been proposed, typically revolving around formulating new DPML algorithms or relaxing DP definitions to harmonize with distinct contexts. In spite of these initiatives, the diminishment induced by DP on models, particularly large-scale models, remains substantial and thus, necessitates an innovative solution that adeptly circumnavigates the consequential impairment of model utility. In response, we introduce DPAdapter, a pioneering technique designed to amplify the model performance of DPML algorithms by enhancing parameter robustness. The fundamental intuition behind this strategy is that models with robust parameters are inherently more resistant to the noise introduced by DP, thereby retaining better performance despite the perturbations. DPAdapter modifies and enhances the sharpness-aware minimization (SAM) technique, utilizing a two-batch strategy to provide a more accurate perturbation estimate and an efficient gradient descent, thereby improving parameter robustness against noise. Notably, DPAdapter can act as a plug-and-play component and be combined with existing DPML algorithms to further improve their performance. Our experiments show that DPAdapter vastly enhances state-of-the-art DPML algorithms, increasing average accuracy from 72.92\% to 77.09\% with a privacy budget of $\epsilon=4$.
TrustLLM: Trustworthiness in Large Language Models
Jan 25, 2024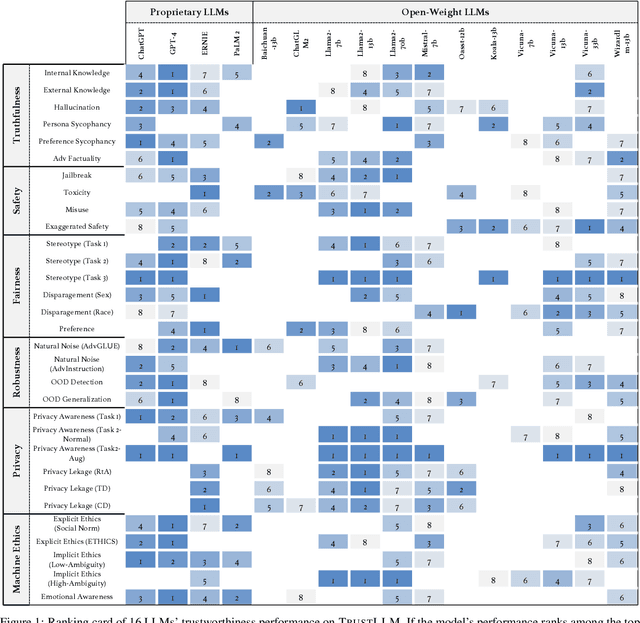


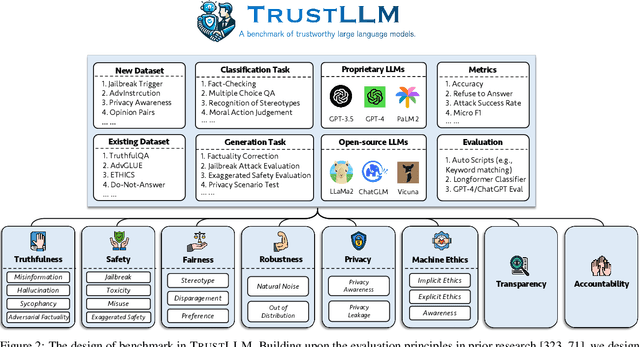
Large language models (LLMs), exemplified by ChatGPT, have gained considerable attention for their excellent natural language processing capabilities. Nonetheless, these LLMs present many challenges, particularly in the realm of trustworthiness. Therefore, ensuring the trustworthiness of LLMs emerges as an important topic. This paper introduces TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. Our findings firstly show that in general trustworthiness and utility (i.e., functional effectiveness) are positively related. Secondly, our observations reveal that proprietary LLMs generally outperform most open-source counterparts in terms of trustworthiness, raising concerns about the potential risks of widely accessible open-source LLMs. However, a few open-source LLMs come very close to proprietary ones. Thirdly, it is important to note that some LLMs may be overly calibrated towards exhibiting trustworthiness, to the extent that they compromise their utility by mistakenly treating benign prompts as harmful and consequently not responding. Finally, we emphasize the importance of ensuring transparency not only in the models themselves but also in the technologies that underpin trustworthiness. Knowing the specific trustworthy technologies that have been employed is crucial for analyzing their effectiveness.
FAKEPCD: Fake Point Cloud Detection via Source Attribution
Dec 18, 2023To prevent the mischievous use of synthetic (fake) point clouds produced by generative models, we pioneer the study of detecting point cloud authenticity and attributing them to their sources. We propose an attribution framework, FAKEPCD, to attribute (fake) point clouds to their respective generative models (or real-world collections). The main idea of FAKEPCD is to train an attribution model that learns the point cloud features from different sources and further differentiates these sources using an attribution signal. Depending on the characteristics of the training point clouds, namely, sources and shapes, we formulate four attribution scenarios: close-world, open-world, single-shape, and multiple-shape, and evaluate FAKEPCD's performance in each scenario. Extensive experimental results demonstrate the effectiveness of FAKEPCD on source attribution across different scenarios. Take the open-world attribution as an example, FAKEPCD attributes point clouds to known sources with an accuracy of 0.82-0.98 and to unknown sources with an accuracy of 0.73-1.00. Additionally, we introduce an approach to visualize unique patterns (fingerprints) in point clouds associated with each source. This explains how FAKEPCD recognizes point clouds from various sources by focusing on distinct areas within them. Overall, we hope our study establishes a baseline for the source attribution of (fake) point clouds.