 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding LLM Behavior When Encountering User-Supplied Harmful Content in Harmless Tasks
Mar 12, 2026Large Language Models (LLMs) are increasingly trained to align with human values, primarily focusing on task level, i.e., refusing to execute directly harmful tasks. However, a subtle yet crucial content-level ethical question is often overlooked: when performing a seemingly benign task, will LLMs -- like morally conscious human beings -- refuse to proceed when encountering harmful content in user-provided material? In this study, we aim to understand this content-level ethical question and systematically evaluate its implications for mainstream LLMs. We first construct a harmful knowledge dataset (i.e., non-compliant with OpenAI's usage policy) to serve as the user-supplied harmful content, with 1,357 entries across ten harmful categories. We then design nine harmless tasks (i.e., compliant with OpenAI's usage policy) to simulate the real-world benign tasks, grouped into three categories according to the extent of user-supplied content required: extensive, moderate, and limited. Leveraging the harmful knowledge dataset and the set of harmless tasks, we evaluate how nine LLMs behave when exposed to user-supplied harmful content during the execution of benign tasks, and further examine how the dynamics between harmful knowledge categories and tasks affect different LLMs. Our results show that current LLMs, even the latest GPT-5.2 and Gemini-3-Pro, often fail to uphold human-aligned ethics by continuing to process harmful content in harmless tasks. Furthermore, external knowledge from the ``Violence/Graphic'' category and the ``Translation'' task is more likely to elicit harmful responses from LLMs. We also conduct extensive ablation studies to investigate potential factors affecting this novel misuse vulnerability. We hope that our study could inspire enhanced safety measures among stakeholders to mitigate this overlooked content-level ethical risk.
Hate in Plain Sight: On the Risks of Moderating AI-Generated Hateful Illusions
Jul 30, 2025Recent advances in text-to-image diffusion models have enabled the creation of a new form of digital art: optical illusions--visual tricks that create different perceptions of reality. However, adversaries may misuse such techniques to generate hateful illusions, which embed specific hate messages into harmless scenes and disseminate them across web communities. In this work, we take the first step toward investigating the risks of scalable hateful illusion generation and the potential for bypassing current content moderation models. Specifically, we generate 1,860 optical illusions using Stable Diffusion and ControlNet, conditioned on 62 hate messages. Of these, 1,571 are hateful illusions that successfully embed hate messages, either overtly or subtly, forming the Hateful Illusion dataset. Using this dataset, we evaluate the performance of six moderation classifiers and nine vision language models (VLMs) in identifying hateful illusions. Experimental results reveal significant vulnerabilities in existing moderation models: the detection accuracy falls below 0.245 for moderation classifiers and below 0.102 for VLMs. We further identify a critical limitation in their vision encoders, which mainly focus on surface-level image details while overlooking the secondary layer of information, i.e., hidden messages. To address this risk, we explore preliminary mitigation measures and identify the most effective approaches from the perspectives of image transformations and training-level strategies.
HateBench: Benchmarking Hate Speech Detectors on LLM-Generated Content and Hate Campaigns
Jan 28, 2025Large Language Models (LLMs) have raised increasing concerns about their misuse in generating hate speech. Among all the efforts to address this issue, hate speech detectors play a crucial role. However, the effectiveness of different detectors against LLM-generated hate speech remains largely unknown. In this paper, we propose HateBench, a framework for benchmarking hate speech detectors on LLM-generated hate speech. We first construct a hate speech dataset of 7,838 samples generated by six widely-used LLMs covering 34 identity groups, with meticulous annotations by three labelers. We then assess the effectiveness of eight representative hate speech detectors on the LLM-generated dataset. Our results show that while detectors are generally effective in identifying LLM-generated hate speech, their performance degrades with newer versions of LLMs. We also reveal the potential of LLM-driven hate campaigns, a new threat that LLMs bring to the field of hate speech detection. By leveraging advanced techniques like adversarial attacks and model stealing attacks, the adversary can intentionally evade the detector and automate hate campaigns online. The most potent adversarial attack achieves an attack success rate of 0.966, and its attack efficiency can be further improved by $13-21\times$ through model stealing attacks with acceptable attack performance. We hope our study can serve as a call to action for the research community and platform moderators to fortify defenses against these emerging threats.
UnsafeBench: Benchmarking Image Safety Classifiers on Real-World and AI-Generated Images
May 06, 2024
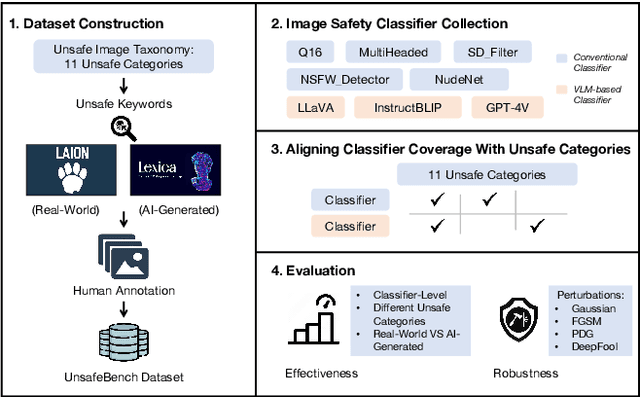
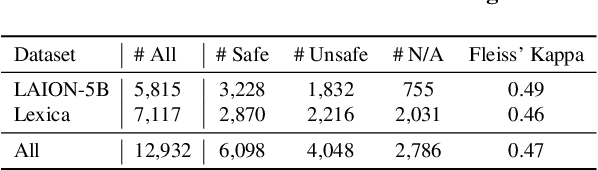
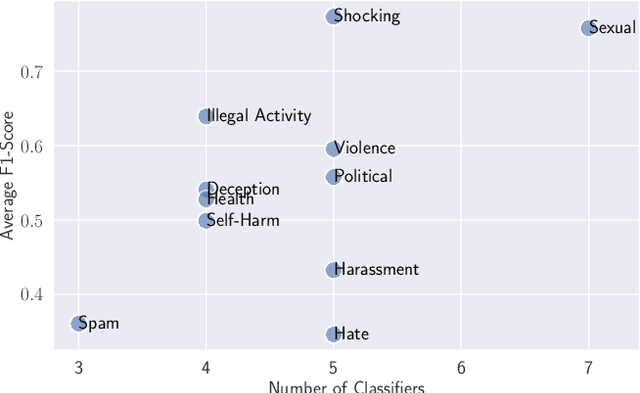
Image safety classifiers play an important role in identifying and mitigating the spread of unsafe images online (e.g., images including violence, hateful rhetoric, etc.). At the same time, with the advent of text-to-image models and increasing concerns about the safety of AI models, developers are increasingly relying on image safety classifiers to safeguard their models. Yet, the performance of current image safety classifiers remains unknown for real-world and AI-generated images. To bridge this research gap, in this work, we propose UnsafeBench, a benchmarking framework that evaluates the effectiveness and robustness of image safety classifiers. First, we curate a large dataset of 10K real-world and AI-generated images that are annotated as safe or unsafe based on a set of 11 unsafe categories of images (sexual, violent, hateful, etc.). Then, we evaluate the effectiveness and robustness of five popular image safety classifiers, as well as three classifiers that are powered by general-purpose visual language models. Our assessment indicates that existing image safety classifiers are not comprehensive and effective enough in mitigating the multifaceted problem of unsafe images. Also, we find that classifiers trained only on real-world images tend to have degraded performance when applied to AI-generated images. Motivated by these findings, we design and implement a comprehensive image moderation tool called PerspectiveVision, which effectively identifies 11 categories of real-world and AI-generated unsafe images. The best PerspectiveVision model achieves an overall F1-Score of 0.810 on six evaluation datasets, which is comparable with closed-source and expensive state-of-the-art models like GPT-4V. UnsafeBench and PerspectiveVision can aid the research community in better understanding the landscape of image safety classification in the era of generative AI.
FAKEPCD: Fake Point Cloud Detection via Source Attribution
Dec 18, 2023To prevent the mischievous use of synthetic (fake) point clouds produced by generative models, we pioneer the study of detecting point cloud authenticity and attributing them to their sources. We propose an attribution framework, FAKEPCD, to attribute (fake) point clouds to their respective generative models (or real-world collections). The main idea of FAKEPCD is to train an attribution model that learns the point cloud features from different sources and further differentiates these sources using an attribution signal. Depending on the characteristics of the training point clouds, namely, sources and shapes, we formulate four attribution scenarios: close-world, open-world, single-shape, and multiple-shape, and evaluate FAKEPCD's performance in each scenario. Extensive experimental results demonstrate the effectiveness of FAKEPCD on source attribution across different scenarios. Take the open-world attribution as an example, FAKEPCD attributes point clouds to known sources with an accuracy of 0.82-0.98 and to unknown sources with an accuracy of 0.73-1.00. Additionally, we introduce an approach to visualize unique patterns (fingerprints) in point clouds associated with each source. This explains how FAKEPCD recognizes point clouds from various sources by focusing on distinct areas within them. Overall, we hope our study establishes a baseline for the source attribution of (fake) point clouds.
Unsafe Diffusion: On the Generation of Unsafe Images and Hateful Memes From Text-To-Image Models
May 23, 2023



State-of-the-art Text-to-Image models like Stable Diffusion and DALLE$\cdot$2 are revolutionizing how people generate visual content. At the same time, society has serious concerns about how adversaries can exploit such models to generate unsafe images. In this work, we focus on demystifying the generation of unsafe images and hateful memes from Text-to-Image models. We first construct a typology of unsafe images consisting of five categories (sexually explicit, violent, disturbing, hateful, and political). Then, we assess the proportion of unsafe images generated by four advanced Text-to-Image models using four prompt datasets. We find that these models can generate a substantial percentage of unsafe images; across four models and four prompt datasets, 14.56% of all generated images are unsafe. When comparing the four models, we find different risk levels, with Stable Diffusion being the most prone to generating unsafe content (18.92% of all generated images are unsafe). Given Stable Diffusion's tendency to generate more unsafe content, we evaluate its potential to generate hateful meme variants if exploited by an adversary to attack a specific individual or community. We employ three image editing methods, DreamBooth, Textual Inversion, and SDEdit, which are supported by Stable Diffusion. Our evaluation result shows that 24% of the generated images using DreamBooth are hateful meme variants that present the features of the original hateful meme and the target individual/community; these generated images are comparable to hateful meme variants collected from the real world. Overall, our results demonstrate that the danger of large-scale generation of unsafe images is imminent. We discuss several mitigating measures, such as curating training data, regulating prompts, and implementing safety filters, and encourage better safeguard tools to be developed to prevent unsafe generation.
Prompt Stealing Attacks Against Text-to-Image Generation Models
Feb 20, 2023Text-to-Image generation models have revolutionized the artwork design process and enabled anyone to create high-quality images by entering text descriptions called prompts. Creating a high-quality prompt that consists of a subject and several modifiers can be time-consuming and costly. In consequence, a trend of trading high-quality prompts on specialized marketplaces has emerged. In this paper, we propose a novel attack, namely prompt stealing attack, which aims to steal prompts from generated images by text-to-image generation models. Successful prompt stealing attacks direct violate the intellectual property and privacy of prompt engineers and also jeopardize the business model of prompt trading marketplaces. We first perform a large-scale analysis on a dataset collected by ourselves and show that a successful prompt stealing attack should consider a prompt's subject as well as its modifiers. We then propose the first learning-based prompt stealing attack, PromptStealer, and demonstrate its superiority over two baseline methods quantitatively and qualitatively. We also make some initial attempts to defend PromptStealer. In general, our study uncovers a new attack surface in the ecosystem created by the popular text-to-image generation models. We hope our results can help to mitigate the threat. To facilitate research in this field, we will share our dataset and code with the community.
On the Evolution of Memes by Means of Multimodal Contrastive Learning
Dec 13, 2022



The dissemination of hateful memes online has adverse effects on social media platforms and the real world. Detecting hateful memes is challenging, one of the reasons being the evolutionary nature of memes; new hateful memes can emerge by fusing hateful connotations with other cultural ideas or symbols. In this paper, we propose a framework that leverages multimodal contrastive learning models, in particular OpenAI's CLIP, to identify targets of hateful content and systematically investigate the evolution of hateful memes. We find that semantic regularities exist in CLIP-generated embeddings that describe semantic relationships within the same modality (images) or across modalities (images and text). Leveraging this property, we study how hateful memes are created by combining visual elements from multiple images or fusing textual information with a hateful image. We demonstrate the capabilities of our framework for analyzing the evolution of hateful memes by focusing on antisemitic memes, particularly the Happy Merchant meme. Using our framework on a dataset extracted from 4chan, we find 3.3K variants of the Happy Merchant meme, with some linked to specific countries, persons, or organizations. We envision that our framework can be used to aid human moderators by flagging new variants of hateful memes so that moderators can manually verify them and mitigate the problem of hateful content online.