 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsafeBench: Benchmarking Image Safety Classifiers on Real-World and AI-Generated Images
Paper and Code

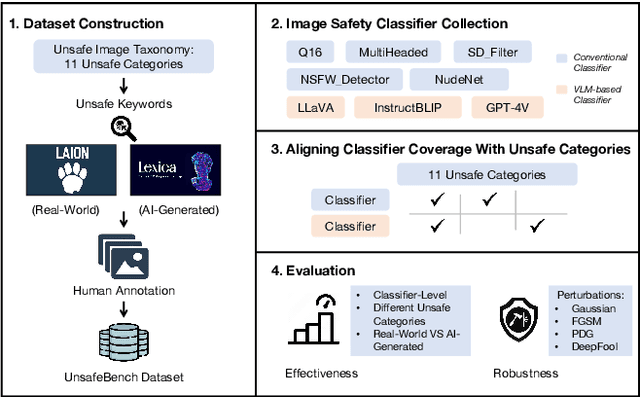
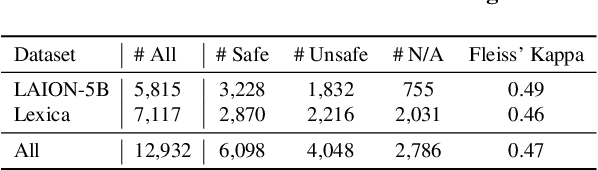
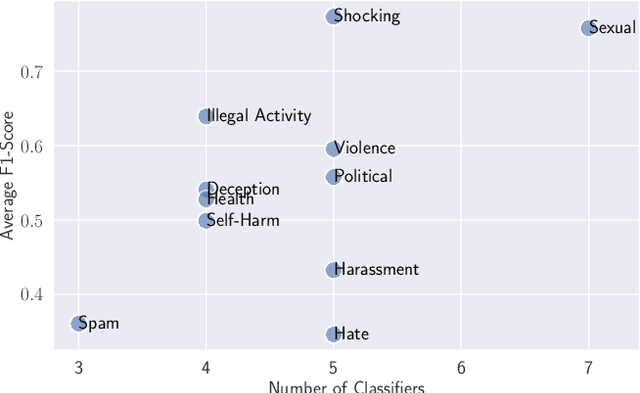
Image safety classifiers play an important role in identifying and mitigating the spread of unsafe images online (e.g., images including violence, hateful rhetoric, etc.). At the same time, with the advent of text-to-image models and increasing concerns about the safety of AI models, developers are increasingly relying on image safety classifiers to safeguard their models. Yet, the performance of current image safety classifiers remains unknown for real-world and AI-generated images. To bridge this research gap, in this work, we propose UnsafeBench, a benchmarking framework that evaluates the effectiveness and robustness of image safety classifiers. First, we curate a large dataset of 10K real-world and AI-generated images that are annotated as safe or unsafe based on a set of 11 unsafe categories of images (sexual, violent, hateful, etc.). Then, we evaluate the effectiveness and robustness of five popular image safety classifiers, as well as three classifiers that are powered by general-purpose visual language models. Our assessment indicates that existing image safety classifiers are not comprehensive and effective enough in mitigating the multifaceted problem of unsafe images. Also, we find that classifiers trained only on real-world images tend to have degraded performance when applied to AI-generated images. Motivated by these findings, we design and implement a comprehensive image moderation tool called PerspectiveVision, which effectively identifies 11 categories of real-world and AI-generated unsafe images. The best PerspectiveVision model achieves an overall F1-Score of 0.810 on six evaluation datasets, which is comparable with closed-source and expensive state-of-the-art models like GPT-4V. UnsafeBench and PerspectiveVision can aid the research community in better understanding the landscape of image safety classification in the era of generative AI.